
 Peranti teknologi
AI
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Peranti teknologi
AI
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama


Editor |. KX
Dalam bidang penyelidikan dan pembangunan ubat, dengan tepat dan berkesan meramalkan pertalian pengikatan protein dan ligan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan.
Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat tentang permukaan protein, struktur dan jujukan 3D, serta menggunakan mekanisme perhatian silang untuk mod yang berbeza. Penjajaran ciri antara negeri.
Hasil eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini.
Penyelidikan berkaitan bertajuk "Ramalan pertalian pengikat multimodal protein–ligan berasaskan permukaan" telah diterbitkan pada "Bioinformatik" pada 21 Jun.

Penyelidikan ramalan pertalian pengikat protein-ligan
Sebagai peringkat utama penemuan ubat, meramalkan pertalian pengikatan protein-ligan telah dikaji secara meluas sejak sekian lama, yang penting untuk pemeriksaan ubat yang cekap dan tepat. Alat penemuan dadah bantuan komputer tradisional menggunakan fungsi pemarkahan (SF) untuk menganggarkan secara kasar pertalian mengikat protein-ligan, tetapi dengan ketepatan yang rendah. Kaedah simulasi dinamik molekul boleh memberikan anggaran pertalian mengikat yang lebih tepat tetapi selalunya mahal dan memakan masa. Dengan perkembangan teknologi pengkomputeran dan peningkatan jumlah data biologi berskala besar, kaedah berasaskan pembelajaran mendalam telah menunjukkan potensi besar dalam bidang ramalan pertalian pengikat protein-ligan. Walau bagaimanapun, penyelidikan semasa kebanyakannya menggunakan perwakilan berasaskan jujukan atau struktur untuk meramalkan pertalian mengikat ligan protein, dan terdapat sedikit kajian mengenai maklumat permukaan protein yang penting untuk interaksi ligan protein. Permukaan molekul ialah perwakilan peringkat tinggi bagi struktur protein, yang mempamerkan corak kimia dan geometri yang berfungsi sebagai cap jari corak interaksi protein dengan biomolekul lain. Oleh itu, beberapa kajian mula menggunakan maklumat permukaan protein untuk meramalkan pertalian mengikat protein-ligan. Tetapi kaedah sedia ada tertumpu terutamanya pada data modal tunggal dan mengabaikan maklumat pelbagai mod protein. Tambahan pula, apabila memproses maklumat multimodal protein, kaedah tradisional biasanya menghubungkan ciri-ciri daripada modaliti yang berbeza secara langsung tanpa mengambil kira kepelbagaian antara mereka, yang mengakibatkan ketidakupayaan untuk mengeksploitasi pelengkap antara modaliti dengan berkesan.Rangka kerja pengekstrakan ciri multi-modal novel
Di sini, penyelidik mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel yang buat pertama kalinya menggabungkan maklumat daripada permukaan protein, struktur dan jujukan 3D.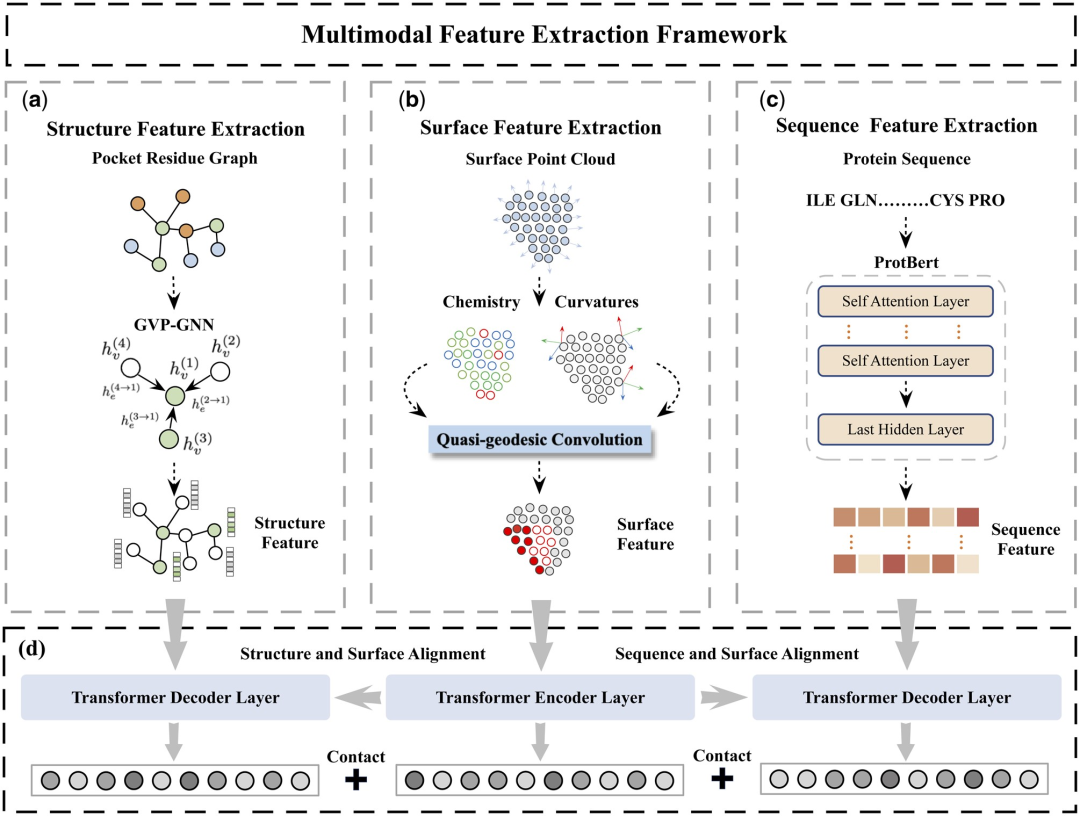
Prestasi SOTA
Jadual 1 menunjukkan keputusan MFE dan model garis dasar lain pada tugas ramalan pertalian pengikat protein-ligan. Semua model menggunakan kaedah pembahagian set latihan dan pengesahan yang sama dan telah diuji pada set teras PDBbind (versi 2016). Ia boleh didapati bahawa kaedah MFE mencapai prestasi SOTA berbanding semua garis dasar.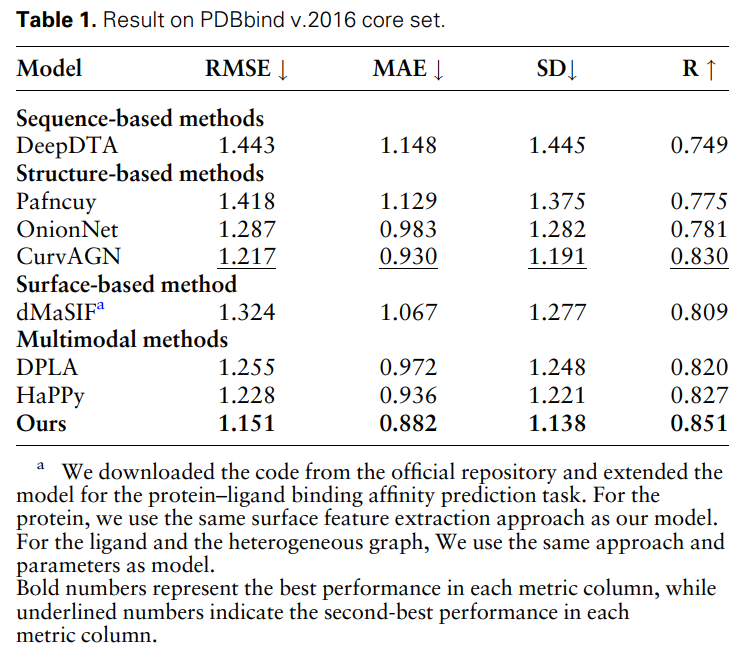
Kajian Ablasi
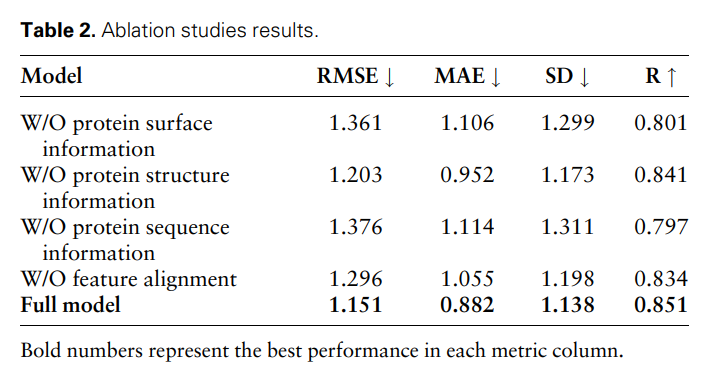
Untuk membuktikan lagi keberkesanan dan keperluan ciri-ciri modal yang berbeza dan perbandingan ciri, para penyelidik menjalankan kajian ablasi berikut: Maklumat permukaan protein W/O, maklumat struktur protein W/O , w/ o maklumat jujukan protein dan penjajaran tanpa ciri. Keputusan ditunjukkan dalam Jadual 2 dan Rajah 2.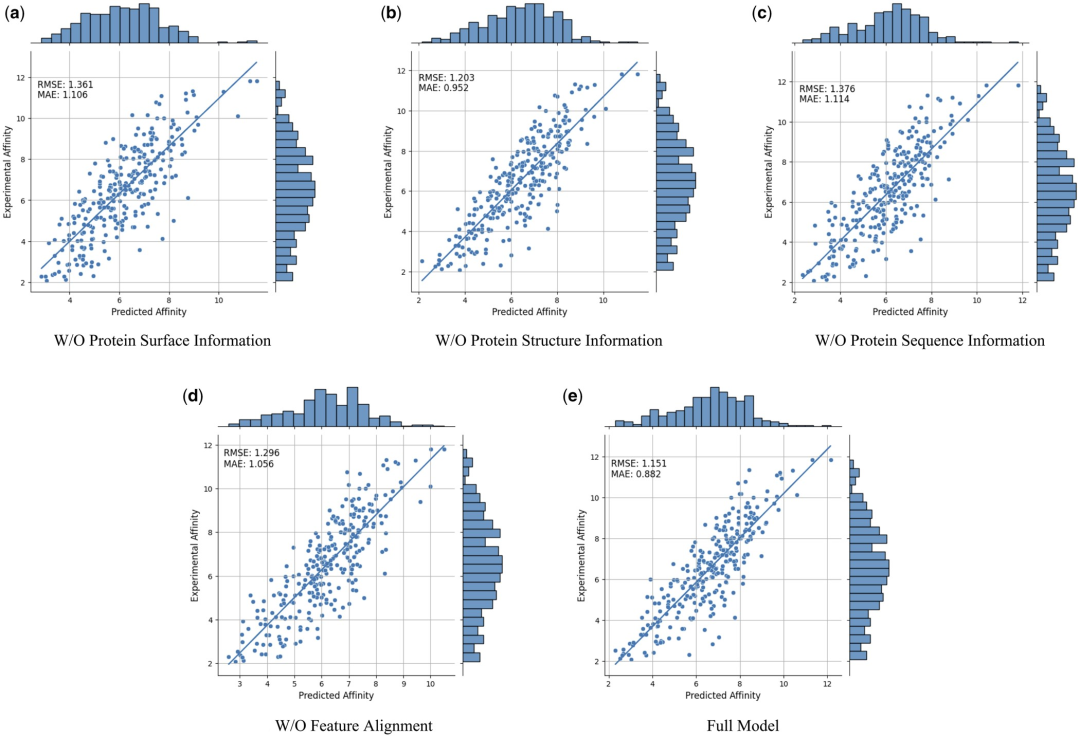
Rajah 2: Keputusan kajian Ablasi. (Sumber: kertas)
Hasilnya menunjukkan bahawa apabila maklumat permukaan dialih keluar, prestasi menurun dengan ketara, menunjukkan bahawa maklumat permukaan memainkan peranan penting dalam model. Begitu juga, mengecualikan sama ada maklumat struktur atau jujukan mengakibatkan kemerosotan prestasi, manakala penyingkiran maklumat jujukan menghasilkan kemerosotan yang lebih ketara. Ini kerana maklumat jujukan mengandungi maklumat global tentang protein, yang penting untuk model memahami protein sepenuhnya.
Selain itu, tanpa perbandingan ciri, prestasi model akan menurun. Ini menekankan kepentingan perbandingan ciri dalam memproses data berbilang modal, kerana ia membantu mengurangkan kepelbagaian antara ciri-ciri modal yang berbeza, dengan itu meningkatkan keupayaan model untuk menyepadukan ciri-ciri modal yang berbeza dengan berkesan.
Analisis hiperparameter
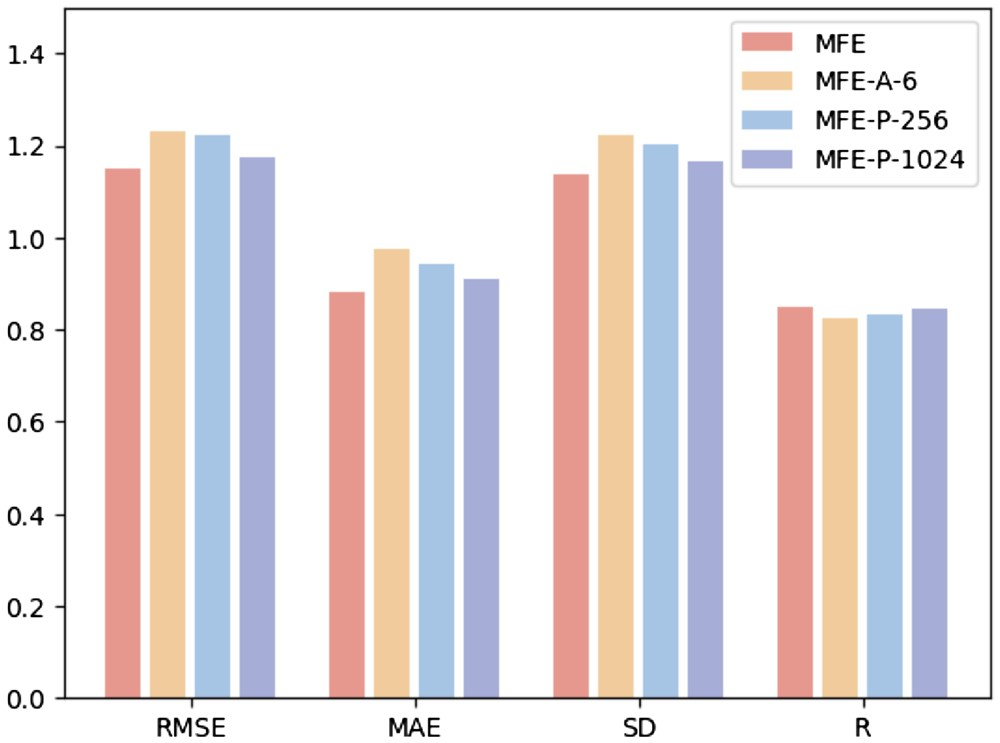
Untuk mengkaji kesan hiperparameter yang berbeza pada prestasi model, penyelidik menjalankan tiga eksperimen berikut: (i) MFE-A-6: hanya menggunakan 6 jenis atom asas untuk mewakili Kimia sifat permukaan, termasuk hidrogen, karbon, nitrogen, oksigen, fosforus, dan sulfur; (ii) MFE-P-256: Hanya 256 titik permukaan yang paling hampir dengan pusat ligan dipilih sebagai permukaan poket protein; -P -1024: Pilih 1024 titik permukaan yang paling hampir dengan pusat ligan sebagai permukaan poket protein.
Rajah 3 menunjukkan keputusan tiga kaedah pemilihan hiperparameter berbeza pada tugas ramalan pertalian pengikat protein-ligan.
Analisis dan Visualisasi Penjajaran Ciri
Untuk mengkaji secara mendalam kesan penjajaran ciri pada prestasi model, penyelidik menggunakan analisis komponen utama (PCA) untuk melakukan pengurangan dimensi dan penjumlahan permukaan protein, struktur. dan ciri urutan dalam set ujian Analisis visual. Pendekatan ini bertujuan untuk menentukan sama ada penjajaran ciri boleh mengurangkan kepelbagaian antara benam multimodal.
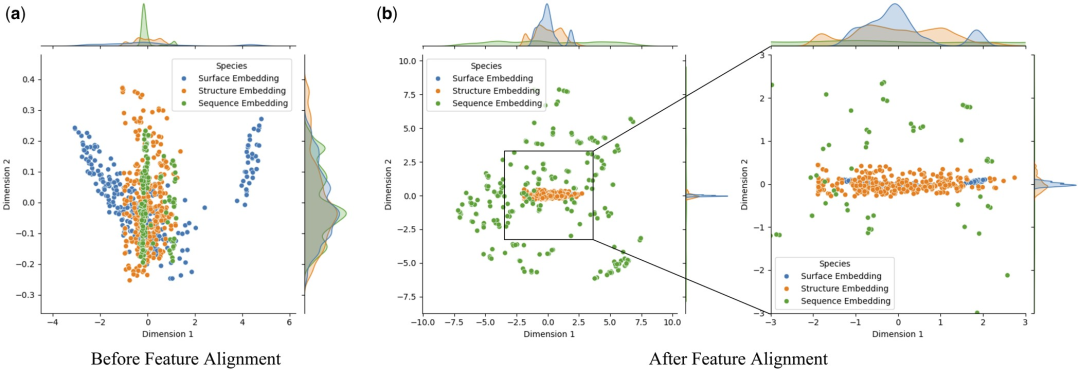
Penyelidikan mendapati penjajaran ciri telah meningkatkan konsistensi antara permukaan protein, struktur dan pembenaman jujukan. Ini disebabkan oleh pengoptimuman interaksi ciri berbilang modal dalam Transformer melalui mekanisme perhatian, yang mengira berat perhatian antara ciri yang berbeza. Ini meningkatkan keupayaan model untuk menangkap maklumat utama, membolehkan data daripada modaliti berbeza dikelompokkan lebih rapat dalam ruang ciri, dengan itu mengurangkan hingar dan ralat dalam pengenalpastian model interaksi protein-ligan.
Akhirnya, para penyelidik membuat kesimpulan, "Ringkasnya, dengan mengkaji permukaan protein, kita boleh memperoleh pemahaman yang lebih mendalam tentang bagaimana protein berinteraksi dengan biomolekul lain Dalam kerja masa hadapan, kita akan meneroka permukaan protein dengan lebih teliti untuk mendedahkan penggunaannya yang lebih luas bioinformatik"
Nota: Muka depan datang daripada Internet
.Atas ialah kandungan terperinci Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Teknologi Simou telah membangunkan set data "DefectSpectrum" secara inovatif, yang menyediakan anotasi berskala besar yang kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "DefectSpectrum" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan) dan klasifikasi kecacatan yang paling terperinci (125 kategori kecacatan
 Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model yang cemerlang. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak bidang. Selain model umum, beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, dan InternVL untuk tugasan bahasa visual.
 Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Editor |KX Sehingga hari ini, perincian dan ketepatan struktur yang ditentukan oleh kristalografi, daripada logam ringkas kepada protein membran yang besar, tidak dapat ditandingi oleh mana-mana kaedah lain. Walau bagaimanapun, cabaran terbesar, yang dipanggil masalah fasa, kekal mendapatkan maklumat fasa daripada amplitud yang ditentukan secara eksperimen. Penyelidik di Universiti Copenhagen di Denmark telah membangunkan kaedah pembelajaran mendalam yang dipanggil PhAI untuk menyelesaikan masalah fasa kristal Rangkaian saraf pembelajaran mendalam yang dilatih menggunakan berjuta-juta struktur kristal tiruan dan data pembelauan sintetik yang sepadan boleh menghasilkan peta ketumpatan elektron yang tepat. Kajian menunjukkan bahawa kaedah penyelesaian struktur ab initio berasaskan pembelajaran mendalam ini boleh menyelesaikan masalah fasa pada resolusi hanya 2 Angstrom, yang bersamaan dengan hanya 10% hingga 20% daripada data yang tersedia pada resolusi atom, manakala Pengiraan ab initio tradisional
 Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Bagi AI, Olimpik Matematik tidak lagi menjadi masalah. Pada hari Khamis, kecerdasan buatan Google DeepMind menyelesaikan satu kejayaan: menggunakan AI untuk menyelesaikan soalan sebenar IMO Olimpik Matematik Antarabangsa tahun ini, dan ia hanya selangkah lagi untuk memenangi pingat emas. Pertandingan IMO yang baru berakhir minggu lalu mempunyai enam soalan melibatkan algebra, kombinatorik, geometri dan teori nombor. Sistem AI hibrid yang dicadangkan oleh Google mendapat empat soalan dengan betul dan memperoleh 28 mata, mencapai tahap pingat perak. Awal bulan ini, profesor UCLA, Terence Tao baru sahaja mempromosikan Olimpik Matematik AI (Anugerah Kemajuan AIMO) dengan hadiah berjuta-juta dolar Tanpa diduga, tahap penyelesaian masalah AI telah meningkat ke tahap ini sebelum Julai. Lakukan soalan secara serentak pada IMO Perkara yang paling sukar untuk dilakukan dengan betul ialah IMO, yang mempunyai sejarah terpanjang, skala terbesar dan paling negatif
 PRO |. Mengapa model besar berdasarkan MoE lebih patut diberi perhatian?
Aug 07, 2024 pm 07:08 PM
PRO |. Mengapa model besar berdasarkan MoE lebih patut diberi perhatian?
Aug 07, 2024 pm 07:08 PM
Pada tahun 2023, hampir setiap bidang AI berkembang pada kelajuan yang tidak pernah berlaku sebelum ini. Pada masa yang sama, AI sentiasa menolak sempadan teknologi trek utama seperti kecerdasan yang terkandung dan pemanduan autonomi. Di bawah trend berbilang modal, adakah status Transformer sebagai seni bina arus perdana model besar AI akan digoncang? Mengapakah penerokaan model besar berdasarkan seni bina MoE (Campuran Pakar) menjadi trend baharu dalam industri? Bolehkah Model Penglihatan Besar (LVM) menjadi satu kejayaan baharu dalam penglihatan umum? ...Daripada surat berita ahli PRO 2023 laman web ini yang dikeluarkan dalam tempoh enam bulan lalu, kami telah memilih 10 tafsiran khas yang menyediakan analisis mendalam tentang aliran teknologi dan perubahan industri dalam bidang di atas untuk membantu anda mencapai matlamat anda dalam bidang baharu. tahun. Tafsiran ini datang dari Week50 2023
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Kadar ketepatan mencapai 60.8%. Model ramalan retrosintesis kimia Universiti Zhejiang berdasarkan Transformer diterbitkan dalam sub-jurnal Nature
Aug 06, 2024 pm 07:34 PM
Kadar ketepatan mencapai 60.8%. Model ramalan retrosintesis kimia Universiti Zhejiang berdasarkan Transformer diterbitkan dalam sub-jurnal Nature
Aug 06, 2024 pm 07:34 PM
Editor |. KX Retrosynthesis ialah tugas kritikal dalam penemuan ubat dan sintesis organik, dan AI semakin digunakan untuk mempercepatkan proses. Kaedah AI sedia ada mempunyai prestasi yang tidak memuaskan dan kepelbagaian terhad. Dalam amalan, tindak balas kimia sering menyebabkan perubahan molekul tempatan, dengan pertindihan yang besar antara bahan tindak balas dan produk. Diilhamkan oleh ini, pasukan Hou Tingjun di Universiti Zhejiang mencadangkan untuk mentakrifkan semula ramalan retrosintetik satu langkah sebagai tugas penyuntingan rentetan molekul, secara berulang menapis rentetan molekul sasaran untuk menghasilkan sebatian prekursor. Dan model retrosintetik berasaskan penyuntingan EditRetro dicadangkan, yang boleh mencapai ramalan berkualiti tinggi dan pelbagai. Eksperimen yang meluas menunjukkan bahawa model itu mencapai prestasi cemerlang pada set data penanda aras standard USPTO-50 K, dengan ketepatan 1 teratas 60.8%.
