


Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Pengarang pertama kertas kerja ini ialah Yang Yuchen, pelajar sarjana tahun kedua di Pusat Pengajian Statistik dan Sains Data Universiti Nankai, dan penasihatnya ialah Profesor Madya Xu Jun di Pusat Pengajian Statistik dan Sains Data Universiti Nankai. Fokus penyelidikan pasukan Profesor Xu Jun ialah penglihatan komputer, AI generatif dan pembelajaran mesin yang cekap, dan telah menerbitkan banyak kertas kerja dalam persidangan dan jurnal teratas, dengan lebih daripada 4,700 petikan Google Scholar.
Memandangkan model Transformer berskala besar secara beransur-ansur menjadi seni bina bersatu dalam pelbagai bidang, penalaan halus telah menjadi cara penting untuk menggunakan model besar yang telah dilatih untuk tugas hiliran. Walau bagaimanapun, apabila saiz model meningkat dari hari ke hari, memori video yang diperlukan untuk penalaan halus juga meningkat secara beransur-ansur Cara mengurangkan memori video penalaan halus dengan cekap telah menjadi isu penting. Sebelum ini, apabila memperhalusi model Transformer, untuk menjimatkan overhed memori grafik, pendekatan biasa adalah menggunakan titik semak kecerunan (juga dipanggil pengiraan semula pengaktifan) untuk mengurangkan masa yang diperlukan dalam proses rambatan belakang (BP) dengan mengorbankan kelajuan latihan . Aktifkan penggunaan memori video.
Baru-baru ini, kertas kerja "Mengurangkan Overhed Memori Penalaan Halus dengan Anggaran dan Perkongsian Belakang Perkongsian Memori" yang diterbitkan di ICML 2024 oleh pasukan Guru Xu Jun dari Pusat Pengajian Statistik dan Sains Data Universiti Nankai mencadangkan bahawa dengan menukar perambatan belakang ( BP), dalam Tanpa menambah jumlah pengiraan, penggunaan memori pengaktifan puncak berkurangan dengan ketara.

Kertas: Mengurangkan Penalaan Halus Memori Overhed dengan Anggaran dan Perkongsian Balik Memori
Pautan kertas: https://arxiv.org/abs/2406.1626.1626.162 //github.com/yyyyychen/LowMemoryBP
Artikel ini mencadangkan dua strategi penambahbaikan rambatan balik, iaitu Rambatan Balik Anggaran (Approx-BP) dan Rambatan Balik Perkongsian Memori (MS-BP). Approx-BP dan MS-BP masing-masing mewakili dua penyelesaian untuk meningkatkan kecekapan memori dalam perambatan belakang, yang boleh secara kolektif dirujuk sebagai LowMemoryBP. Sama ada dari segi teori atau praktikal, artikel itu menyediakan panduan terobosan untuk latihan penyebaran belakang yang lebih cekap.
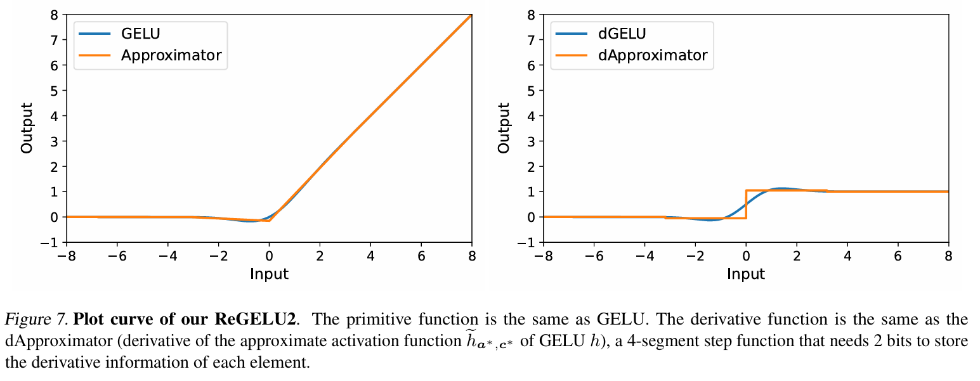
in latihan backpropagation tradisional, backpropagation kecerunan fungsi pengaktifan dengan ketat sepadan dengan fungsi derivatifnya. menjadi Tensor ciri disimpan sepenuhnya dalam memori video aktif. Penulis artikel ini mencadangkan satu set teori penghampiran perambatan balik, iaitu teori Approx-BP. Berpandukan teori ini, penulis menggunakan fungsi linear sekeping untuk menganggarkan fungsi pengaktifan, dan menggantikan perambatan belakang kecerunan GELU/SiLU dengan terbitan fungsi linear sekeping (fungsi langkah). Pendekatan ini membawa kepada dua fungsi pengaktifan cekap memori asimetri: ReGELU2 dan ReSiLU2. Jenis fungsi pengaktifan ini menggunakan fungsi langkah 4 peringkat untuk laluan balik terbalik, supaya storan pengaktifan hanya perlu menggunakan jenis data 2-bit.
MS-BP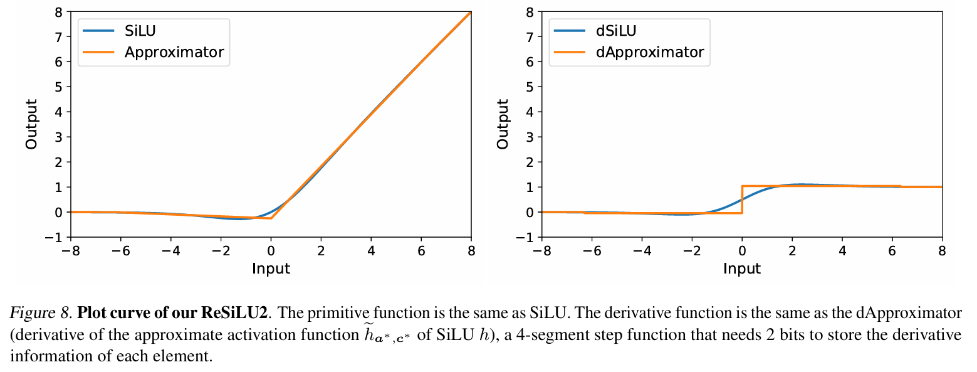
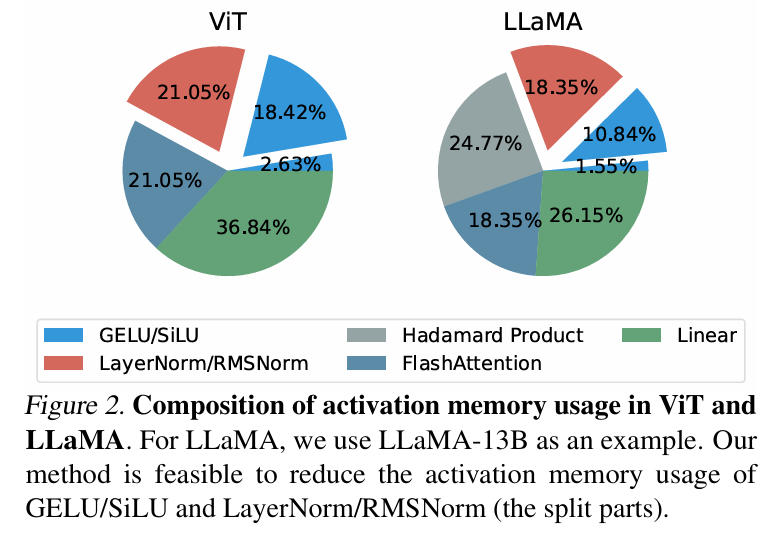
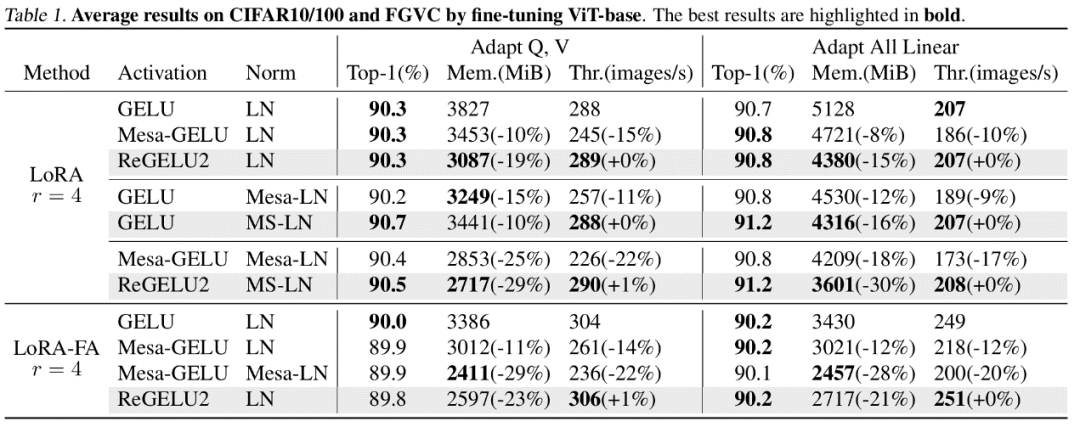
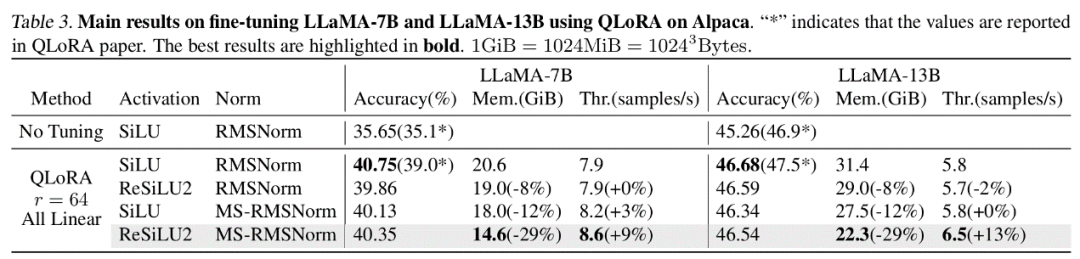
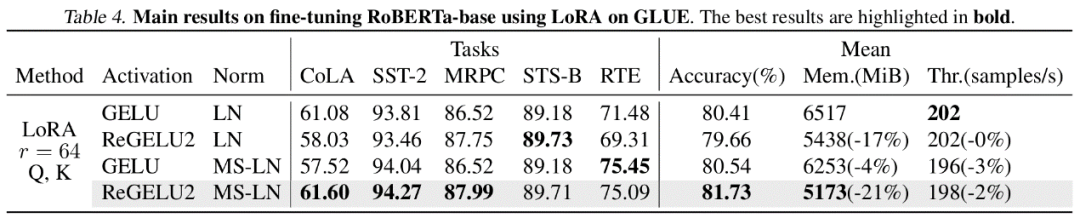
BP Setiap lapisan rangkaian biasanya menyimpan tensor input ke dalam memori pengaktifan untuk pengiraan rambatan belakang. Penulis menegaskan bahawa jika perambatan belakang lapisan tertentu boleh ditulis semula ke dalam bentuk bergantung kepada output, maka lapisan ini dan lapisan seterusnya boleh berkongsi tensor pengaktifan yang sama, sekali gus mengurangkan redundansi storan pengaktifan. Artikel tersebut menunjukkan bahawa LayerNorm dan RMSNorm, yang biasa digunakan dalam model Transformer, boleh memenuhi keperluan strategi MS-BP dengan baik selepas menggabungkan parameter afin ke dalam lapisan linear lapisan terakhir. MS-LayerNorm dan MS-RMSNorm yang direka bentuk semula tidak lagi menjana memori grafik aktif bebas. Hasil eksperimen Pengarang menjalankan eksperimen penalaan halus ke atas beberapa model perwakilan dalam bidang penglihatan komputer dan pemprosesan bahasa semula jadi. Antaranya, dalam eksperimen penalaan halus ViT, LLaMA dan RoBERTa, kaedah yang dicadangkan dalam artikel mengurangkan penggunaan memori puncak masing-masing sebanyak 27%, 29% dan 21%, tanpa menyebabkan sebarang kehilangan dalam kesan latihan dan kelajuan latihan. Ambil perhatian bahawa perbandingan Mesa (kaedah Latihan Mampat Pengaktifan 8-bit) mengurangkan kelajuan latihan sebanyak kira-kira 20%, manakala kaedah LowMemoryBP yang dicadangkan dalam artikel mengekalkan kelajuan latihan sepenuhnya. Kesimpulan dan kepentingan Dua strategi penambahbaikan BP yang dicadangkan dalam artikel, Approx-BP dan MS-BP, kedua-duanya mencapai kesan latihan dan latihan semasa pengaktifan latihan penjimatan yang ketara. Ini bermakna pengoptimuman berdasarkan prinsip BP adalah penyelesaian penjimatan memori yang sangat menjanjikan. Di samping itu, teori Approx-BP yang dicadangkan dalam artikel itu memecahkan rangka kerja pengoptimuman rangkaian saraf tradisional dan menyediakan kemungkinan teori untuk menggunakan derivatif tidak berpasangan. ReGELU2 dan ReSiLU2 yang diperolehi menunjukkan nilai praktikal penting pendekatan ini. Anda dialu-alukan untuk membaca kertas atau kod untuk memahami butiran algoritma Modul yang berkaitan telah dibuka sumber pada repositori github projek LowMemoryBP. 
Atas ialah kandungan terperinci ICML 2024 |. Tanpa memperlahankan dan menyimpan memori video, LowMemoryBP meningkatkan kecekapan ingatan video perambatan belakang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah perbezaan antara rabbitmq dan kafka
Apakah perbezaan antara rabbitmq dan kafka
 Apakah mata wang USDT?
Apakah mata wang USDT?
 Windows 11 pemindahan komputer saya ke tutorial desktop
Windows 11 pemindahan komputer saya ke tutorial desktop
 Apakah yang perlu saya lakukan jika iPad saya tidak boleh dicas?
Apakah yang perlu saya lakukan jika iPad saya tidak boleh dicas?
 Bagaimana untuk menyambungkan php ke pangkalan data mssql
Bagaimana untuk menyambungkan php ke pangkalan data mssql
 Apakah perbezaan antara USB-C dan TYPE-C
Apakah perbezaan antara USB-C dan TYPE-C
 Tutorial penggunaan Kindeditor
Tutorial penggunaan Kindeditor
 Apakah carian sorotan?
Apakah carian sorotan?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



