

Empat VLM utama semuanya cuba menyentuh gajah secara membabi buta?
Biar model SOTA yang paling popular (GPT-4o, Gemini-1.5, Sonnet-3, Sonnet-3.5) mengira berapa banyak persimpangan yang terdapat di antara dua garisan akan berprestasi lebih baik daripada manusia?
Jawapannya mungkin tidak.
Sejak pelancaran GPT-4V, model bahasa visual (VLM) telah menjadikan kecerdasan model besar sebagai langkah besar ke hadapan ke arah tahap kecerdasan buatan yang kami bayangkan.
VLM boleh memahami gambar dan menggunakan bahasa untuk menerangkan perkara yang mereka lihat dan melaksanakan tugas yang rumit berdasarkan pemahaman ini. Sebagai contoh, jika anda menghantar model VLM gambar meja makan dan gambar menu, ia boleh mengekstrak bilangan botol bir dan harga unit pada menu daripada dua gambar, dan mengira berapa kos bir untuk hidangan itu.
VLM telah maju dengan begitu pantas sehingga menjadi tugas untuk model untuk mengetahui sama ada terdapat beberapa "elemen abstrak" yang tidak munasabah dalam gambar ini, sebagai contoh, perlu meminta model untuk mengenal pasti sama ada ada orang yang menyeterika pakaian dalam teksi laju Kaedah penilaian biasa.

Walau bagaimanapun, set ujian penanda aras semasa tidak menilai keupayaan visual VLM dengan baik. Mengambil MMMU sebagai contoh, 42.9% daripada soalan boleh diselesaikan tanpa melihat gambar, yang bermaksud bahawa banyak jawapan boleh disimpulkan daripada soalan teks dan pilihan sahaja. Kedua, keupayaan yang ditunjukkan oleh VLM pada masa ini sebahagian besarnya adalah hasil daripada "menghafal" data Internet berskala besar. Ini menyebabkan VLM mendapat markah yang sangat tinggi dalam set ujian, tetapi ini tidak bermakna penghakiman itu benar: bolehkah VLM melihat imej seperti manusia?
Untuk mendapatkan jawapan kepada soalan ini, penyelidik dari Universiti Auburn dan Universiti Alberta memutuskan untuk "menguji penglihatan" untuk VLM. Diilhamkan oleh "ujian penglihatan" pakar optometris, mereka meminta empat VLM teratas: GPT-4o, Gemini-1.5 Pro, Claude-3 Sonnet dan Claude-3.5 Sonnet untuk membuat satu set "soalan ujian penglihatan". .

VLM Buta atau tidak? Tujuh tugas utama, anda boleh mengetahuinya dengan hanya satu ujian
Tahap 1: Kira berapa banyak persimpangan antara garisan?
Pengarang kertas itu mencipta 150 imej yang mengandungi dua segmen garisan pada latar belakang putih. Koordinat-x bagi segmen garisan ini adalah tetap dan jarak yang sama, manakala koordinat-y dijana secara rawak. Terdapat hanya tiga titik persilangan antara dua segmen garis: 0, 1 dan 2.Seperti yang ditunjukkan dalam Rajah 5, dalam ujian dua versi perkataan gesaan dan tiga versi ketebalan segmen baris, semua VLM berprestasi lemah dalam tugasan mudah ini.
Sonnet-3.5, yang mempunyai ketepatan terbaik, hanya 77.33% (lihat Jadual 1).
Secara lebih khusus, VLM cenderung berprestasi lebih teruk apabila jarak antara dua garisan mengecil (lihat Rajah 6 di bawah). Oleh kerana setiap graf garis terdiri daripada tiga titik utama, jarak antara dua garis dikira sebagai jarak purata tiga pasangan titik yang sepadan.

Hasil ini sangat berbeza dengan ketepatan tinggi VLM pada ChartQA, yang menunjukkan bahawa VLM dapat mengenal pasti aliran keseluruhan graf garisan, tetapi tidak boleh "zum masuk" untuk melihat butiran seperti "garisan yang bersilang ".
Tahap kedua: Tentukan hubungan kedudukan antara dua bulatan
Seperti yang ditunjukkan dalam gambar, pengarang kertas secara rawak menghasilkan dua bulatan yang sama saiz pada kanvas dengan saiz tertentu. Terdapat hanya tiga situasi dalam hubungan kedudukan antara dua bulatan: persilangan, tangen dan pemisahan. 
Anehnya, dalam tugasan ini yang boleh dilihat secara intuitif oleh manusia dan jawapannya boleh dilihat sepintas lalu, tiada VLM yang dapat memberikan jawapan dengan sempurna (lihat Rajah 7).

Model dengan ketepatan terbaik (92.78%) ialah Gemini-1.5 (lihat Jadual 2).

Dalam percubaan, satu situasi kerap berlaku: apabila dua kalangan sangat rapat, VLM cenderung berprestasi buruk tetapi membuat tekaan yang berpendidikan. Seperti yang ditunjukkan dalam rajah di bawah, Sonnet-3.5 biasanya menjawab "tidak" konservatif.

Seperti yang ditunjukkan dalam Rajah 8, walaupun jarak antara dua bulatan berjauhan dan mempunyai jejari (d = 0.5) selebar itu, GPT-4o, yang mempunyai ketepatan yang paling teruk, tidak dapat mencapai 100 % tepat.
Maksudnya, penglihatan VLM nampaknya tidak cukup jelas untuk melihat celah kecil atau persimpangan antara dua bulatan.

Tahap 3: Berapakah bilangan huruf yang dibulatkan dengan warna merah?
Memandangkan jarak antara huruf dalam perkataan adalah sangat kecil, pengarang kertas itu membuat hipotesis bahawa jika VLM adalah "rabun", maka mereka tidak akan dapat mengenali huruf yang dibulatkan dengan warna merah.
Jadi, mereka memilih rentetan seperti "Pengiktirafan", "Subdermatoglyphic" dan "tHyUiKaRbNqWeOpXcZvM". Hasilkan bulatan merah secara rawak untuk membulatkan huruf dalam rentetan sebagai ujian.

Keputusan ujian menunjukkan bahawa model yang diuji menunjukkan prestasi yang sangat teruk pada tahap ini (lihat Rajah 9 dan Jadual 3).


Sebagai contoh, model bahasa visual cenderung melakukan kesilapan apabila huruf dikaburkan sedikit oleh bulatan merah. Mereka sering mengelirukan huruf di sebelah bulatan merah. Kadangkala model akan menghasilkan halusinasi Sebagai contoh, walaupun ia boleh mengeja perkataan dengan tepat, ia akan menambah aksara bercelaru (contohnya, "9", "n", "©") pada perkataan.

Semua model kecuali GPT-4o menunjukkan prestasi yang lebih baik sedikit pada perkataan berbanding rentetan rawak, menunjukkan bahawa mengetahui ejaan sesuatu perkataan boleh membantu model bahasa visual membuat pertimbangan, dengan itu meningkatkan sedikit ketepatan.
Gemini-1.5 dan Sonnet-3.5 ialah dua model teratas dengan kadar ketepatan masing-masing 92.81% dan 89.22%, dan mengatasi prestasi GPT-4o dan Sonnet-3 hampir 20%.

Tahap 4 dan Tahap 5: Berapakah bilangan bentuk bertindih? Berapakah bilangan petak "matryoshka" yang ada?
Dengan mengandaikan bahawa VLM adalah "rabun", mereka mungkin tidak dapat melihat dengan jelas persilangan antara setiap dua bulatan dalam corak yang serupa dengan "gelang Olimpik". Untuk tujuan ini, pengarang kertas kerja secara rawak menjana 60 kumpulan corak yang serupa dengan "Gelang Olimpik" dan meminta VLM mengira berapa banyak corak bertindih yang mereka ada. Mereka juga menghasilkan versi pentagonal "Gelang Olimpik" untuk ujian lanjut.

Memandangkan VLM berprestasi lemah semasa mengira bilangan bulatan bersilang, pengarang terus menguji kes apabila tepi corak tidak bersilang dan setiap bentuk bersarang sepenuhnya dalam bentuk lain. Mereka menghasilkan corak seperti "matryoshka" sebanyak 2-5 petak dan meminta VLM mengira jumlah bilangan petak dalam imej.

Adalah mudah untuk melihat dari salib merah terang dalam jadual di bawah bahawa kedua-dua tahap ini juga merupakan halangan yang tidak dapat diatasi untuk VLM.

Dalam ujian petak bersarang, ketepatan setiap model sangat berbeza: GPT-4o (ketepatan 48.33%) dan Sonnet-3 (ketepatan 55.00%) sekurang-kurangnya lebih baik daripada Gemini-1.5 (ketepatan 80.00%) dan Sonnet-3.5 (ketepatan 87.50%) 30 mata peratusan lebih rendah.
Jurang ini akan menjadi lebih besar apabila model mengira bulatan bertindih dan pentagon, tetapi Sonnet-3.5 berprestasi beberapa kali lebih baik daripada model lain. Seperti yang ditunjukkan dalam jadual di bawah, apabila imej ialah pentagon, ketepatan Sonnet-3.5 sebanyak 75.83% jauh melebihi Gemini-1.5 9.16%.
Anehnya, keempat-empat model yang diuji mencapai ketepatan 100% apabila mengira 5 cincin, tetapi menambah hanya satu cincin tambahan sudah cukup untuk menyebabkan ketepatan menurun dengan ketara kepada hampir sifar.
Walau bagaimanapun, apabila mengira pentagon, semua VLM (kecuali Sonnet-3.5) berprestasi lemah walaupun semasa mengira 5 pentagon. Secara keseluruhan, pengiraan 6 hingga 9 bentuk (termasuk bulatan dan pentagon) adalah sukar untuk semua model.

Ini menunjukkan bahawa VLM berat sebelah dan mereka lebih cenderung untuk mengeluarkan "Gelang Olimpik" yang terkenal sebagai hasilnya. Sebagai contoh, Gemini-1.5 akan meramalkan keputusan sebagai "5" dalam 98.95% percubaan, tanpa mengira bilangan bulatan sebenar (lihat Jadual 5). Untuk model lain, ralat ramalan ini berlaku lebih kerap untuk gelang berbanding pentagon.

Selain kuantiti, VLM juga mempunyai "keutamaan" yang berbeza dalam warna bentuk.
GPT-4o berprestasi lebih baik pada bentuk berwarna berbanding bentuk hitam tulen, manakala Sonnet-3.5 meramalkan lebih baik dan lebih baik apabila saiz imej meningkat. Walau bagaimanapun, apabila penyelidik menukar warna dan resolusi imej, ketepatan model lain hanya berubah sedikit.
Perlu diingat bahawa dalam tugas mengira petak bersarang, GPT-4o dan Sonnet-3 masih sukar untuk dikira walaupun bilangan petak hanya 2-3. Apabila bilangan segi empat sama meningkat kepada empat dan lima, semua model jatuh jauh daripada ketepatan 100%. Ini menunjukkan bahawa sukar untuk VLM mengekstrak bentuk sasaran dengan tepat walaupun tepi bentuk tidak bersilang.

Tahap 6: Kira berapa baris yang terdapat dalam jadual? Berapakah bilangan lajur yang ada?
Walaupun VLM menghadapi masalah untuk bertindih atau menyusun grafik, apakah yang mereka lihat sebagai corak jubin? Dalam set ujian asas, terutamanya DocVQA, yang mengandungi banyak tugas jadual, ketepatan model yang diuji ialah ≥90%. Pengarang kertas itu menjana 444 jadual secara rawak dengan bilangan baris dan lajur yang berbeza, dan meminta VLM mengira berapa banyak baris yang terdapat dalam jadual itu? Berapakah bilangan lajur yang ada?
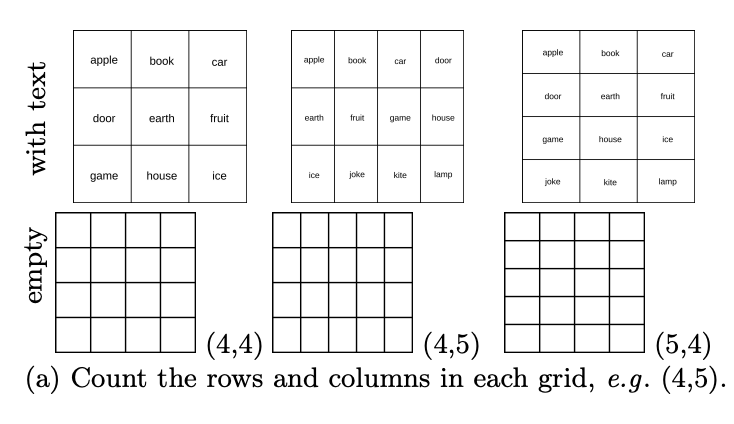
Keputusan menunjukkan bahawa walaupun ia mencapai markah tinggi dalam set data asas, seperti yang ditunjukkan dalam rajah di bawah, VLM juga berprestasi lemah dalam mengira baris dan lajur dalam jadual kosong.

Secara khusus, ia biasanya 1-2 bar off. Seperti yang ditunjukkan dalam rajah di bawah, GPT-4o mengiktiraf grid 4×5 sebagai 4×4, dan Gemini-1.5 mengiktirafnya sebagai 5×5.

Ini menunjukkan bahawa walaupun VLM boleh mengekstrak kandungan penting daripada jadual untuk menjawab soalan berkaitan jadual dalam DocVQA, mereka tidak dapat mengenal pasti dengan jelas jadual sel demi sel.
Ini mungkin kerana jadual dalam dokumen kebanyakannya tidak kosong dan VLM tidak digunakan untuk mengosongkan jadual. Menariknya, selepas penyelidik mempermudahkan tugas dengan cuba menambah perkataan pada setiap sel, peningkatan yang ketara dalam ketepatan diperhatikan untuk semua VLM, contohnya, GPT-4o bertambah baik daripada 26.13% kepada 53.03% (lihat Jadual 6). Walau bagaimanapun, dalam kes ini, prestasi model yang diuji masih tidak sempurna. Seperti yang ditunjukkan dalam Rajah 15a dan b, model berprestasi terbaik (Sonnet-3.5) menunjukkan 88.68% dalam grid yang mengandungi teks dan 59.84% dalam grid kosong.
Dan kebanyakan model (Gemini-1.5, Sonnet-3 dan Sonnet-3.5) secara konsisten menunjukkan prestasi yang lebih baik dalam mengira lajur berbanding dalam mengira baris (lihat Rajah 15c dan d).

Tahap 7: Berapakah bilangan laluan kereta api bawah tanah terus dari titik permulaan ke destinasi?
Ujian ini menguji keupayaan VLM untuk mengikut laluan, yang penting untuk model mentafsir peta, carta dan memahami anotasi seperti anak panah yang ditambahkan oleh pengguna dalam imej input. Untuk tujuan ini, pengarang kertas itu secara rawak menjana 180 peta laluan kereta api bawah tanah, setiap satu dengan empat stesen tetap. Mereka meminta VLM mengira berapa banyak laluan monokromatik yang terdapat di antara dua tapak.

Hasil ujian mengejutkan Walaupun laluan antara dua tapak dipermudahkan kepada hanya satu, semua model tidak boleh mencapai ketepatan 100%. Seperti yang ditunjukkan dalam Jadual 7, model berprestasi terbaik ialah Sonnet-3.5 dengan ketepatan 95% model paling teruk ialah Sonnet-3 dengan ketepatan 23.75%.

Tidak sukar untuk melihat dari rajah di bawah bahawa ramalan VLM biasanya mempunyai sisihan 1 hingga 3 laluan. Apabila kerumitan peta meningkat daripada 1 kepada 3 laluan, prestasi kebanyakan VLM menjadi lebih teruk.

Berdepan dengan "fakta kejam" bahawa VLM arus perdana hari ini berprestasi sangat teruk dalam pengiktirafan imej, ramai netizen terlebih dahulu mengetepikan status mereka sebagai "peguam pembela AI" dan meninggalkan banyak komen pesimis.
Seorang netizen berkata: “Memalukan model SOTA (GPT-4o, Gemini-1.5 Pro, Sonnet-3, Sonnet-3.5) berprestasi sangat teruk, dan model ini sebenarnya mendakwa dalam promosi mereka: mereka boleh Memahami imej? contohnya mereka boleh digunakan untuk membantu orang buta atau mengajar geometri kepada kanak-kanak


Di sisi lain kem yang pesimis, seorang netizen percaya bahawa keputusan buruk ini boleh diselesaikan dengan mudah dengan latihan dan penalaan halus. Kira-kira 100,000 contoh dan dilatih dengan data sebenar, masalah itu diselesaikan

Walau bagaimanapun, kedua-dua "pembela AI" dan "pesimis AI" telah bersetuju dengan fakta bahawa VLM masih menunjukkan prestasi yang baik dalam ujian imej kelemahan yang amat sukar untuk didamaikan.
Pengarang kertas itu juga telah menerima lebih banyak soalan tentang sama ada ujian ini saintifik.

Sesetengah netizen percaya bahawa ujian dalam kertas ini tidak membuktikan bahawa VLM adalah "rabun". Pertama sekali, penghidap rabun tidak melihat butiran kabur "Butir kabur" adalah simptom hiperopia. Kedua, tidak dapat melihat butiran bukanlah perkara yang sama dengan tidak dapat mengira bilangan persimpangan. Ketepatan mengira bilangan baris dan lajur grid kosong tidak bertambah baik dengan resolusi yang semakin meningkat, dan meningkatkan resolusi imej tidak membantu dalam memahami tugas ini. Tambahan pula, peningkatan peleraian imej tidak mempunyai kesan yang ketara ke atas pemahaman garisan bertindih atau persimpangan dalam tugasan ini.
Malah, cabaran yang dihadapi oleh model bahasa visual (VLM) ini dalam mengendalikan tugasan sedemikian mungkin lebih berkaitan dengan keupayaan penaakulan mereka dan cara mereka mentafsir kandungan imej, dan bukannya hanya masalah resolusi visual. Dalam erti kata lain, walaupun jika setiap butiran imej jelas kelihatan, model mungkin masih tidak dapat menyelesaikan tugasan ini dengan tepat jika mereka tidak mempunyai logik penaakulan yang betul atau pemahaman yang mendalam tentang maklumat visual. Oleh itu, penyelidikan ini mungkin perlu menyelidiki dengan lebih mendalam keupayaan VLM dalam pemahaman dan penaakulan visual, bukannya hanya keupayaan pemprosesan imej mereka.
Sesetengah netizen percaya jika penglihatan manusia diproses secara konvolusi, manusia sendiri juga akan menghadapi kesukaran dalam ujian menilai persilangan garisan.
Untuk maklumat lanjut, sila rujuk kertas asal.
Pautan rujukan:
https://arxiv.org/pdf/2407.06581
2?
https://vlmsareblind.github.io/
Atas ialah kandungan terperinci Adakah semua VLM ini buta? GPT-4o dan Sonnet-3.5 berturut-turut gagal dalam ujian 'penglihatan'.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyambung jalur lebar ke pelayan
Bagaimana untuk menyambung jalur lebar ke pelayan
 Bagaimana untuk menyediakan memori maya komputer
Bagaimana untuk menyediakan memori maya komputer
 Pengesyoran kedudukan perisian pengesanan perkakasan komputer
Pengesyoran kedudukan perisian pengesanan perkakasan komputer
 pengecualian nullpointerexception
pengecualian nullpointerexception
 Apakah ruang bebas
Apakah ruang bebas
 Apakah peranan pelayan sip
Apakah peranan pelayan sip
 ps keluar kekunci pintasan skrin penuh
ps keluar kekunci pintasan skrin penuh
 arahan cmd untuk membersihkan sampah pemacu C
arahan cmd untuk membersihkan sampah pemacu C








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



