

Baru-baru ini saya menemui Surat Berita Kejuruteraan Data Ju oleh Julien Hurault pada tindanan data berbilang enjin. Ideanya mudah; kami ingin mengalihkan kod kami dengan mudah ke mana-mana bahagian belakang sambil mengekalkan fleksibiliti untuk mengembangkan saluran paip kami apabila bahagian belakang dan ciri baharu dibangunkan. Ini memerlukan sekurang-kurangnya aliran kerja peringkat tinggi berikut:
Dalam siaran ini, kami menyelami bagaimana kami boleh melaksanakan saluran paip berbilang enjin daripada bahasa pengaturcaraan; Daripada SQL, kami menggunakan cadangan menggunakan API Dataframe yang boleh digunakan untuk kedua-dua kes penggunaan interaktif dan kelompok. Secara khusus, kami menunjukkan cara untuk memecahkan saluran paip kami kepada bahagian yang lebih kecil dan melaksanakannya merentas DuckDB, panda dan Snowflake. Kami juga membincangkan kelebihan susunan data berbilang enjin dan menyerlahkan arah aliran yang muncul dalam bidang.
Kod yang dilaksanakan dalam siaran ini tersedia di GitHub^[Untuk mencuba repo dengan cepat, saya juga menyediakan serpihan nix]. Kerja rujukan dalam surat berita dengan pelaksanaan asal ada di sini.
Saluran paip tindanan data berbilang enjin berfungsi seperti berikut: Sesetengah data mendarat dalam baldi S3, dipraproses untuk mengalih keluar sebarang pendua dan kemudian dimuatkan ke dalam jadual Snowflake, di mana ia diubah lagi dengan fungsi khusus ML atau Snowflake^[Sila ambil perhatian kami tidak akan melaksanakan jenis perkara yang mungkin boleh dilakukan dalam Snowflake dan menganggapnya sebagai keperluan untuk aliran kerja]. Saluran paip menerima pesanan sebagai fail parket yang disimpan ke lokasi pendaratan, diproses terlebih dahulu dan kemudian disimpan di lokasi pementasan dalam baldi S3. Data pementasan kemudian dimuatkan dalam Snowflake untuk menyambungkan alat BI hiliran kepadanya. Saluran paip diikat bersama oleh SQL dbt dengan satu model untuk setiap bahagian belakang dan surat berita memilih Dagster sebagai alat orkestrasi.
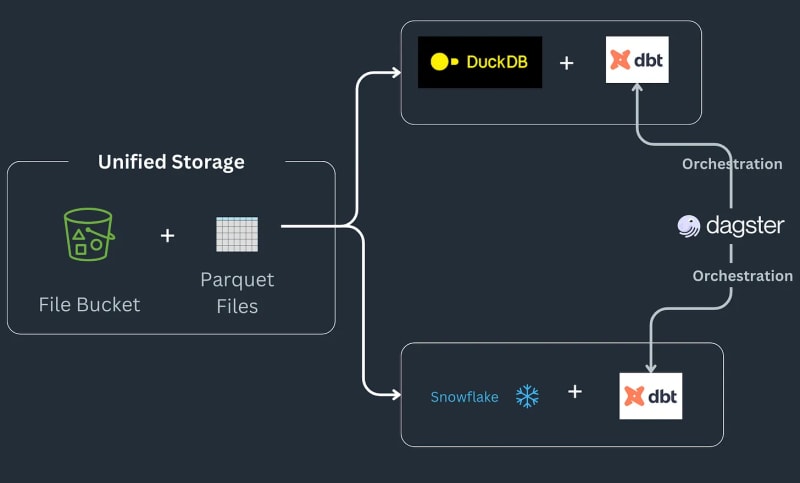
Hari ini, kita akan menyelami cara kita boleh menukar kod panda kita kepada ungkapan Ibis, menghasilkan semula contoh lengkap untuk contoh tindanan berbilang enjin Julien Hurault 1. Daripada menggunakan Model dbt dan SQL, kami menggunakan ibis dan beberapa Python untuk menyusun dan mengatur enjin SQL daripada shell. Dengan menulis semula kod kami sebagai ungkapan Ibis, kami boleh membina saluran paip data kami secara deklaratif dengan pelaksanaan tertunda. Selain itu, Ibis menyokong lebih 20 hujung belakang, jadi kami boleh menulis kod sekali dan mengalihkan ibis.exprs kami ke berbilang hujung belakang. Untuk memudahkan lagi, kami menyerahkan penjadualan dan orkestrasi tugas2 yang disediakan oleh Dagster, terpulang kepada pembaca.
Berikut ialah konsep teras susunan data berbilang enjin seperti yang digariskan dalam surat berita Julien:
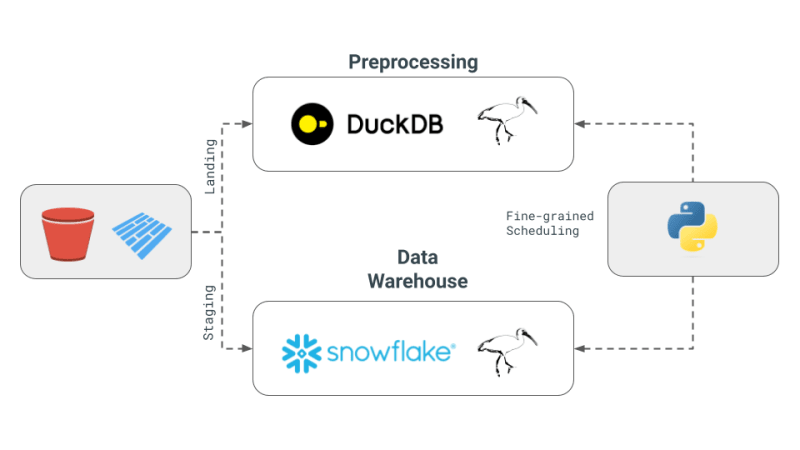
Walaupun saluran paip di atas bagus untuk ETL dan ELT, kadangkala kami mahukan kuasa bahasa pengaturcaraan penuh dan bukannya Bahasa Pertanyaan seperti SQL cth. penyahpepijatan, ujian, UDF kompleks dsb. Untuk penerokaan saintifik, pengkomputeran interaktif adalah penting kerana saintis data perlu mengulangi kod mereka dengan cepat, memvisualisasikan keputusan dan membuat keputusan berdasarkan data.
DataFrames ialah struktur data sedemikian: DataFrames digunakan untuk memproses data tersusun dan menggunakan operasi pengiraan padanya secara interaktif. Mereka menyediakan fleksibiliti untuk dapat memproses data besar dengan operasi gaya SQL, tetapi juga menyediakan kawalan tahap yang lebih rendah untuk mengedit perubahan tahap sel ala Helaian Excel. Biasanya, jangkaan ialah semua data diproses dalam ingatan dan lazimnya sesuai dalam ingatan. Selain itu, DataFrames memudahkan untuk berulang-alik antara mod tertunda/kelompok dan interaktif.
DataFrames excel^[no pun intended] untuk membolehkan orang ramai menggunakan fungsi yang ditentukan pengguna dan membebaskan pengguna daripada batasan SQL iaitu anda kini boleh menggunakan semula kod, menguji operasi anda, dengan mudah memanjangkan jentera hubungan untuk operasi yang kompleks. DataFrames juga memudahkan untuk beralih daripada perwakilan Jadual data ke dalam Tatasusunan dan Tensor yang dijangkakan oleh perpustakaan Pembelajaran Mesin dengan cepat.
Pangkalan data khusus dan dalam proses cth. DuckDB untuk OLAP3, mengaburkan sempadan antara pangkalan data berat terpencil seperti Snowflake dan perpustakaan ergonomik seperti panda. Kami percaya ini adalah peluang untuk membenarkan DataFrames memproses lebih besar daripada data memori sambil mengekalkan jangkaan interaktiviti dan rasa pembangun shell Python tempatan, menjadikan data yang lebih besar daripada memori terasa kecil.
Pelaksanaan kami memberi tumpuan kepada 4 konsep yang dibentangkan sebelum ini:

panda ialah perpustakaan DataFrame yang paling penting dan mungkin menyediakan cara paling mudah untuk melaksanakan aliran kerja di atas. Pertama, kami menjana peminjaman data rawak daripada pelaksanaan dalam surat berita.
#| echo: false
import pandas as pd
from multi_engine_stack_ibis.generator import generate_random_data
generate_random_data("landing/orders.parquet")
df = pd.read_parquet("landing/orders.parquet")
deduped = df.drop_duplicates(["order_id", "dt"])
Pelaksanaan panda adalah penting dalam gaya dan direka bentuk supaya data yang boleh dimuatkan dalam ingatan. API panda sukar dikompilasi ke SQL dengan semua nuansanya dan sebahagian besarnya terletak di tempat istimewanya yang menggabungkan visualisasi Python, plot, pembelajaran mesin, AI dan perpustakaan pemprosesan yang kompleks.
pt.write_pandas(
conn,
deduped,
table_name="T_ORDERS",
auto_create_table=True,
quote_identifiers=False,
table_type="temporary"
)
Selepas menyahgandakan menggunakan operator panda, kami bersedia untuk menghantar data ke Snowflake. Kepingan salji mempunyai kaedah yang dipanggil write_pandas yang berguna untuk kes penggunaan kami.
Satu had panda ialah ia mempunyai API sendiri yang tidak cukup memetakan kembali kepada algebra hubungan. Ibis ialah perpustakaan yang benar-benar dibina oleh orang yang membina panda untuk menyediakan sistem ekspresi waras yang boleh dipetakan kembali ke beberapa bahagian belakang SQL. Ibis mengambil inspirasi daripada pakej dplyr R untuk membina sistem ekspresi baharu yang boleh dengan mudah memetakan kembali kepada algebra hubungan dan dengan itu menyusun kepada SQL. Ia juga adalah gaya deklaratif, membolehkan kami menggunakan pengoptimuman gaya pangkalan data pada pelan logik lengkap atau ungkapan. Ibis ialah komponen utama untuk membolehkan kebolehkomposisian seperti yang diserlahkan dalam codex boleh gubah yang sangat baik.
#| echo: false
import pathlib
import ibis
import ibis.backends.pandas.executor
import ibis.expr.types.relations
from ibis import _
from multi_engine_stack_ibis.generator import generate_random_data
from multi_engine_stack_ibis.utils import (MyExecutor, checkpoint_parquet,
create_table_snowflake,
replace_unbound)
from multi_engine_stack_ibis.connections import make_ibis_snowflake_connection
ibis.backends.pandas.executor.PandasExecutor = MyExecutor
setattr(ibis.expr.types.relations.Table, "checkpoint_parquet", checkpoint_parquet)
setattr(
ibis.expr.types.relations.Table,
"create_table_snowflake",
create_table_snowflake,
)
ibis.set_backend("pandas")
p_staging = pathlib.Path("staging/staging.parquet")
p_landing = pathlib.Path("landing/orders.parquet")
snow_backend = make_ibis_snowflake_connection(database="MULTI_ENGINE", schema="PUBLIC", warehouse="COMPUTE_WH")
expr = (
ibis.read_parquet(p_landing)
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt]))
.filter(_.row_number == 0)
.checkpoint_parquet(p_staging)
.create_table_snowflake("T_ORDERS")
)
expr
Ekspresi Ibis mencetak dirinya sebagai pelan yang serupa dengan Pelan Logik tradisional dalam pangkalan data. Pelan Logik ialah pokok pengendali algebra hubungan yang menerangkan pengiraan yang perlu dilakukan. Pelan ini kemudiannya dioptimumkan oleh pengoptimum pertanyaan dan ditukar kepada pelan fizikal yang dilaksanakan oleh pelaksana pertanyaan. Ungkapan Ibis adalah serupa dengan Rancangan Logik kerana ia menerangkan pengiraan yang perlu dilakukan, tetapi ia tidak dilaksanakan serta-merta. Sebaliknya, mereka disusun ke dalam SQL dan dilaksanakan pada bahagian belakang apabila diperlukan. Pelan Logik secara amnya berada pada tahap butiran yang lebih tinggi daripada DAG yang dihasilkan oleh rangka kerja penjadualan tugas seperti Dask. Secara teorinya, rancangan ini boleh disusun ke dalam DAG Dask.
While pandas is embedded and is just a pip install away, it still has much documented limitations with plenty of performance improvements left on the table. This is where the recent embedded databases like DuckDB fill the gap of packing the full punch of a SQL engine, with all of its optimizations and benefiting from years of research that is as easy to import as is pandas. In this world, at minimum we can delegate all relational and SQL parts of our pipeline in pandas to DuckDB and only get the processed data ready for complex user defined Python.
Now, we are ready to take our Ibisified code and compile our expression above to execute on arbitrary engines, to truly realize the write-once-run-anywhere paradigm: We have successfully decoupled our compute engine with the expression system describing our computation.
Let's break our expression above into smaller parts and have them run across DuckDB, pandas and Snowflake. Note that we are not doing anything once the data lands in Snowflake and just show that we can select the data. Instead, we are leaving that up to the user's imagination what is possible with Snowflake native features.
Notice our expression above is bound to the pandas backend. First, lets create an UnboundTable expression to not have to depend on a backend when writing our expressions.

schema = {
"user_id": "int64",
"dt": "timestamp",
"order_id": "string",
"quantity": "int64",
"purchase_price": "float64",
"sku": "string",
"row_number": "int64",
}
first_expr_for = (
ibis.table(schema, name="orders")
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt])
)
.filter(_.row_number == 0)
)
first_expr_for
Next, we replace the UnboundTable expression with the DuckDB backend and execute it with to_parquet method4. This step is covered by the checkpoint_parquet operator that we added to pandas backend above. Here is an excellent blog that discusses inserting data into Snowflake from any Ibis backend with to_pyarrow functionality.
data = pd.read_parquet("landing/orders.parquet")
duck_backend = ibis.duckdb.connect()
duck_backend.con.execute("CREATE TABLE orders as SELECT * from data")
bind_to_duckdb = replace_unbound(first_expr_for, duck_backend)
bind_to_duckdb.to_parquet(p_staging)
to_sql = ibis.to_sql(bind_to_duckdb)
print(to_sql)
Once the above step creates the de-duplicated table, we can then send data to Snowflake using the pandas backend. This functionality is covered by create_table_snowflake operator that we added to pandas backend above.
second_expr_for = ibis.table(schema, name="T_ORDERS") # nothing special just a reading the data from orders table
snow_backend.create_table("T_ORDERS", schema=second_expr_for.schema(), temp=True)
pandas_backend = ibis.pandas.connect({"T_ORDERS": pd.read_parquet(p_staging)})
snow_backend.insert("T_ORDERS", pandas_backend.to_pyarrow(second_expr_for))
Finally, we can select the data from the Snowflake table to verify that the data has been loaded successfully.
third_expr_for = ibis.table(schema, name="T_ORDERS") # add you Snowflake ML functions here third_expr_for
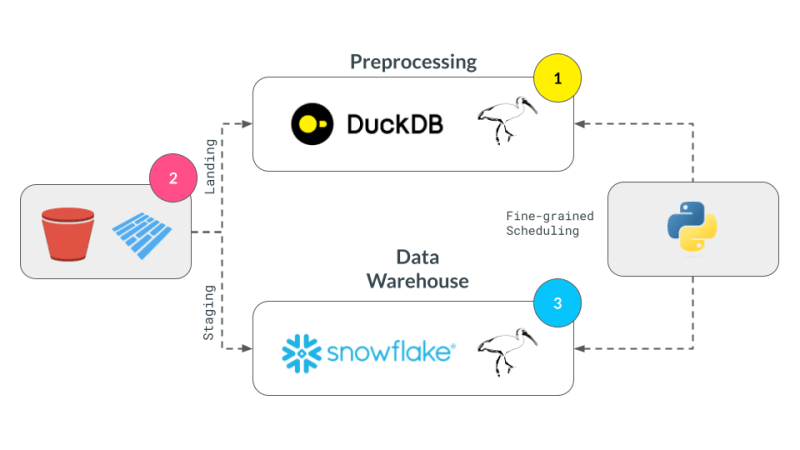
We successfully broke up our computation in pieces, albeit manually, and executed them across DuckDB, pandas, and Snowflake. This demonstrates the flexibility and power of a multi-engine data stack, allowing users to leverage the strengths of different engines to optimize their data processing pipelines.
I'd like to thank Neal Richardson, Dan Lovell and Daniel Mesejo for providing the initial feedback on the post. I highly appreciate the early review and encouragement by Wes McKinney.
In this post, we have primarily focused on v0 of the multi-engine data stack. In the latest version, Apache Iceberg is included as a storage and data format layer. NYC Taxi data is used instead of the random Orders data treated in this and v0 of the posts. ↩
Orchestration Vs fine-grained scheduling: ↩
Some of the examples of in-process databases is described in this post extending DuckDB example above to newer purpose built databases like LanceDB and KuzuDB. ↩
The Ibis docs use backend.to_pandas(expr) commands to bind and run the expression in the same go. Instead, we use replace_unbound method to show a generic way to just compile the expression and not execute it to said backend. This is just for illustration purposes. All the code below, uses the backend.to_pyarrow methods from here on. ↩
Atas ialah kandungan terperinci Timbunan Data Berbilang Enjin Deklaratif dengan Ibis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



