

Shanghai Jiao Tong University & Shanghai AI Lab mengeluarkan penilaian kes perubatan GPT-4V setebal 178 muka surat, secara komprehensif mendedahkan prestasi visual GPT-4V dalam bidang perubatan buat kali pertama pautan ArXiv: https://arxiv.org/abs /2310.09909 Alamat muat turun kertas lain: Awan Baidu: https ://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2Google Drive: https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xhrcao Pengenalan Didorong oleh model asas berskala besar, kecerdasan buatan Perkembangan kecerdasan telah mencapai kemajuan yang besar baru-baru ini, terutamanya OpenAI's GPT-4 keupayaannya yang berkuasa dalam soal jawab dan pengetahuan telah menyinari momen Eureka dalam bidang AI dan menarik. perhatian umum yang meluas. GPT-4V(ision) ialah model asas multi-modal terbaru OpenAI. Berbanding dengan GPT-4, ia menambah keupayaan input imej dan suara. Kajian ini bertujuan untuk menilai prestasi GPT-4V(ision) dalam bidang diagnosis perubatan pelbagai modal melalui analisis kes Sebanyak 128 (92 kes penilaian radiologi, 20 kes penilaian patologi dan 16 kes kedudukan) telah dipaparkan dan dianalisis. . Kes) Contoh soal jawab GPT-4V dengan jumlah 277 imej dalam setiap kes (Nota: Artikel ini tidak akan melibatkan paparan kes, sila rujuk kertas asal untuk paparan dan analisis kes tertentu). Secara ringkasnya, penulis asal berharap untuk menilai secara sistematik keupayaan GPT-4V berikut: Bolehkah GPT-4V mengenali modaliti dan kedudukan pengimejan imej perubatan? Menyedari pelbagai modaliti (seperti X-ray, CT, MRI, ultrasound, dan patologi) dan mengenal pasti lokasi pengimejan dalam imej ini adalah asas untuk diagnosis yang lebih kompleks. Bolehkah GPT-4V menyetempatkan struktur anatomi yang berbeza dalam imej perubatan? Menentukan struktur anatomi tertentu dalam imej adalah penting untuk mengenal pasti keabnormalan dan memastikan isu yang berpotensi ditangani dengan betul. Bolehkah GPT-4V mencari dan mengesan kelainan dalam imej perubatan? Mengesan keabnormalan seperti tumor, patah tulang atau jangkitan adalah matlamat utama analisis imej perubatan. Dalam persekitaran klinikal, model AI yang boleh dipercayai perlu bukan sahaja mengesan anomali ini tetapi juga menentukannya supaya intervensi atau rawatan yang disasarkan dapat dilakukan. Bolehkah GPT-4V menggabungkan berbilang imej untuk diagnosis? Diagnosis perubatan selalunya memerlukan penyepaduan maklumat daripada modaliti pengimejan yang berbeza atau pandangan untuk pemerhatian keseluruhan. Oleh itu, adalah penting untuk meneroka keupayaan GPT-4V untuk menggabungkan dan menganalisis maklumat daripada berbilang imej. Bolehkah GPT-4V menulis laporan perubatan yang menerangkan keadaan abnormal dan penemuan normal yang berkaitan? Bagi ahli radiologi dan pakar patologi, penulisan laporan adalah tugas yang memakan masa. Jika GPT-4V membantu dalam proses ini, menghasilkan laporan yang tepat dan berkaitan secara klinikal, ia sudah pasti akan meningkatkan kecekapan keseluruhan aliran kerja. Bolehkah GPT-4V menyepadukan sejarah pesakit semasa mentafsir imej perubatan? Maklumat asas pesakit dan sejarah perubatan masa lalu boleh mempengaruhi tafsiran imej perubatan semasa dengan ketara. Jika maklumat ini boleh diambil kira untuk menganalisis imej semasa proses ramalan model, analisis akan lebih diperibadikan dan lebih tepat. Bolehkah GPT-4V mengekalkan konsistensi dan ingatan merentasi pelbagai pusingan interaksi? Dalam sesetengah senario perubatan, satu pusingan analisis mungkin tidak mencukupi. Semasa perbualan atau analisis yang panjang, terutamanya dalam persekitaran penjagaan kesihatan yang kompleks, mengekalkan kesinambungan pengetahuan tentang data adalah penting. Penilaian kertas asal meliputi 17 sistem perubatan, termasuk: sistem saraf pusat, kepala dan leher, jantung, dada dan perut, kepala dan leher, jantung, dada, darah, hepatobiliari, gastrousus, urologi, ginekologi, obstetrik, payudara, Anus , abdomen, ginekologi, obstetrik, payudara, muskuloskeletal, tulang belakang, vaskular, onkologi, trauma dan imej pediatrik datang daripada 8 modaliti yang digunakan dalam penggunaan klinikal harian, termasuk: X-ray, tomografi berkomputer (CT) , Pengimejan Resonans Magnetik (MRI) , Positron Emission Tomography (PET), Digital Subtraction Angiography (DSA), Mammografi, Ultrasound dan Patologi.

Pemilihan kes ujian
Soal Jawab radiologi kertas asal datang daripada [Radiopaedia](https://radiopaedia.org/), imej dimuat turun terus dari halaman web, kes kedudukan datang daripada pelbagai orang awam perubatan set data segmentasi dan imej patologi Diperoleh daripada [PathologyOutlines](https://www.pathologyoutlines.com/). Semasa memilih kes, penulis mempertimbangkan secara menyeluruh aspek berikut:
Masa diterbitkan:원본 논문은 GPT-4V(https://chat.openai.com/)의 [웹 버전]을 사용하여 테스트되었습니다. 1차 Q&A에서는 사용자들이 이미지를 입력한 후 여러 차례의 Q&A가 시작됩니다. 상황의 상호 영향을 피하기 위해 새로운 사례마다 Q&A를 위한 새로운 Q&A 창이 생성됩니다.
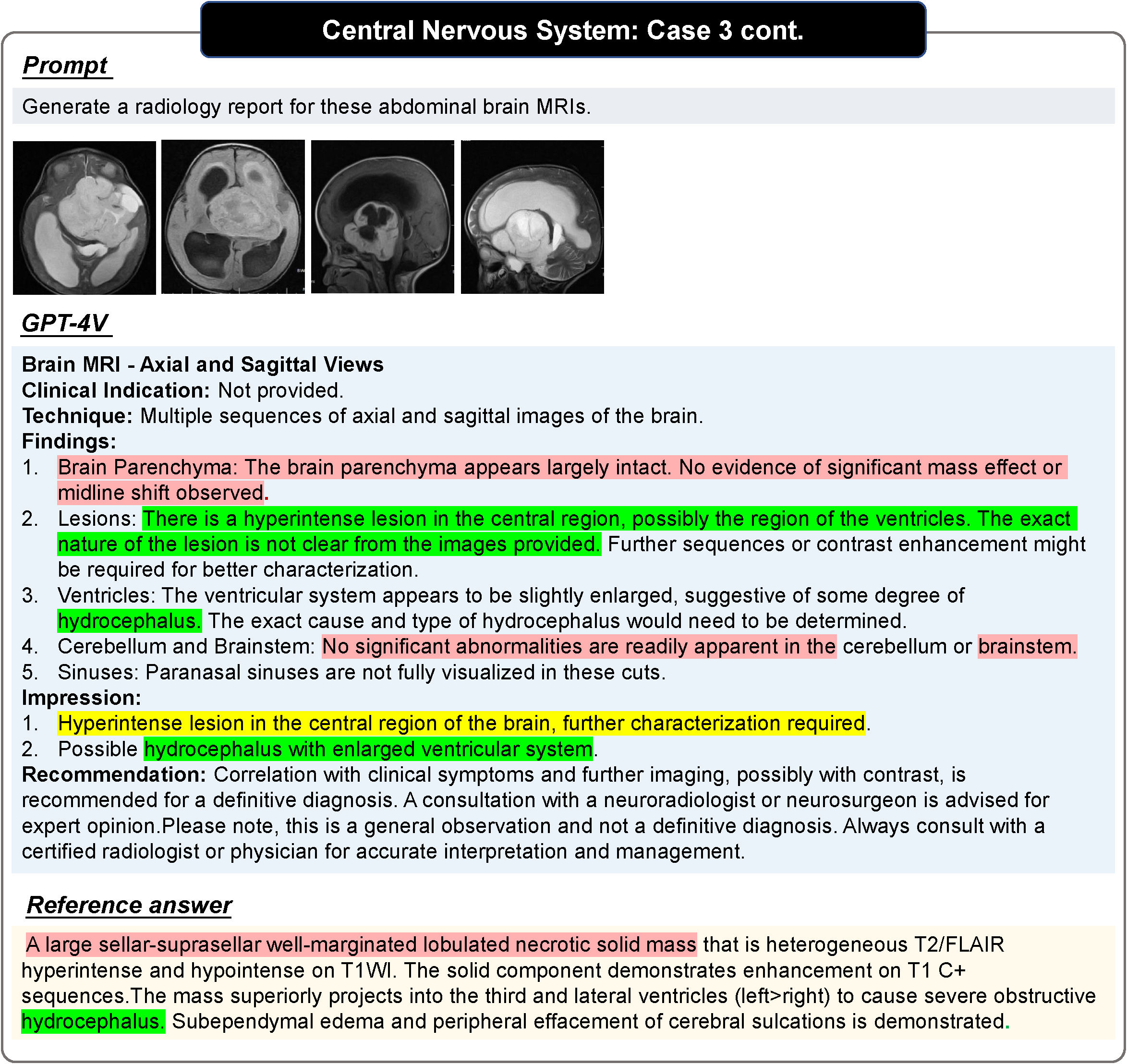
그림의 빨간색은 오류, 노란색은 불확실함, 녹색은 정확함을 나타냅니다. 참고문헌의 색상은 해당 판단의 근거를 나타냅니다. 색칠되지 않은 문장은 독자가 스스로 정확성을 판단해야 합니다. 더 많은 사례 및 사례분석을 원하시면 원문을 참고하시기 바랍니다.
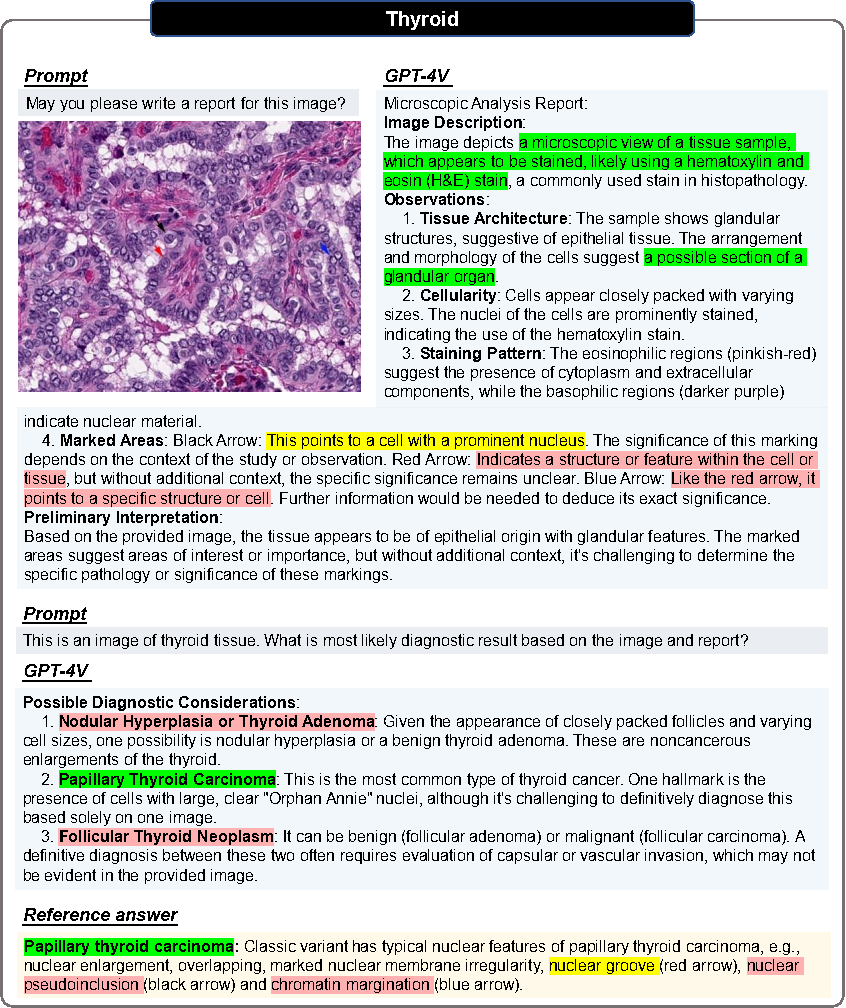
병리학적 평가
모든 이미지는 두 차례의 대화를 거칩니다.
1라운드
입력 이미지만을 기반으로 보고서를 생성할 수 있는지 물어보세요.
목적: GPT-4V가 관련 의학적 힌트를 제공하지 않고 영상 양식과 조직 기원을 식별할 수 있는지 평가합니다.
2차
사용자는 올바른 조직 소스를 제공하고 GPT-4V가 병리학적 이미지와 조직 소스 정보를 기반으로 진단을 내릴 수 있는지 묻습니다.
GPT-4V에서 보고서를 수정하여 명확한 진단을 내리기를 바랍니다.
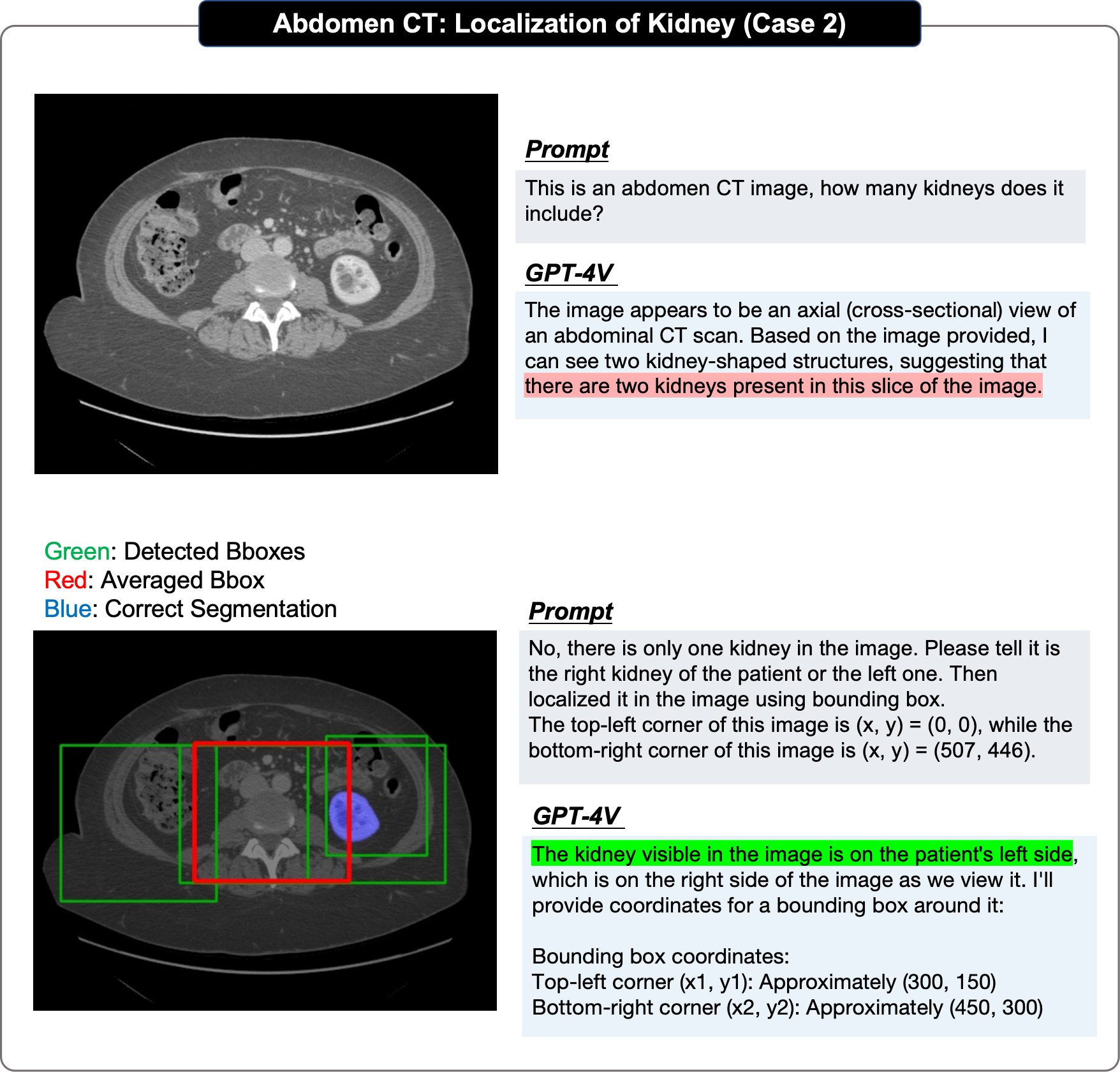
위치 평가에서 원본 논문은 단계별 접근 방식을 채택했습니다.
 물론 원저자는 평가에서 몇 가지 단점과 한계도 언급했습니다.
물론 원저자는 평가에서 몇 가지 단점과 한계도 언급했습니다.
샘플 편향
주석 또는 참조 답변이 불완전합니다.
2D 슬라이스 입력만
요약하자면, 평가가 완전하지는 않을 수 있지만 원저자는 이 분석이 연구원과 의료 전문가에게 귀중한 통찰력을 제공하여 다중 모드 기본 모델의 현재 기능을 드러내고 잠재적으로 의학의 기본 모델을 구축하는 미래 작업에 영감을 줄 수 있다고 믿습니다.
방사선 사례 부분
GPT4-V は、画像内容のモーダル認識、撮像部位の決定、画像面のカテゴリの決定能力など、ほとんどのタスクに対して良好な処理を示しています。たとえば、著者らは、GPT-4V は MRI、CT、および などのさまざまなモダリティを簡単に区別できると指摘しました。
著者らは次のことを発見しました。一方で、OpenAI は GPT-4V が直接診断を行うことを厳しく制限するセキュリティメカニズムを設定しているようです。 、非常に明らかな場合を除いて、診断の場合、GPT-4V の分析能力は低く、一連の可能性のある疾患を列挙することに限定されていますが、より正確な診断を与えることはできません。
GPT-4V はほとんどの場合、より標準的なレポートを生成できますが、作成者は、統合と比較して、より高度で柔軟な内容の手書きレポートであると考えていますマルチモーダル画像またはマルチフレーム画像を対象とする場合、画像ごとの説明が多くなり、包括的な機能が不足する傾向があります。したがって、参考価値が少なく、正確性に欠ける内容がほとんどです。
GPT-4V は強力なテキスト認識、マーク認識、その他の機能を示しており、使用してみてください。これらのマーカーは分析用です。しかし、著者らは、その限界は次のとおりであると考えています。まず、GPT-4V は常にテキストとタグを過剰に使用し、画像自体が二次的な参照オブジェクトになってしまいます。第 2 に、GPT-4V は堅牢性が低く、画像内の医療情報を誤解することがよくあります。
ほとんどの場合、GPT4-V は人体に埋め込まれた医療機器を正確に識別し、比較的正確に位置を特定できます。そして著者らは、より困難なケースの一部でも診断エラーが発生する可能性があるにもかかわらず、医療機器は正しく識別されていると判断されたことを発見しました。
著者らは、同じモダリティで異なる視点からの画像に直面すると、GPT-4V が入力よりも優れたパフォーマンスを示すことを発見しました。 GPT-4V は単一の画像ですが、依然として各ビューを個別に分析する傾向があります。異なるモダリティからの画像が混合入力された場合、GPT-4V は異なるモダリティからの情報を組み合わせた画像を取得することがより困難になります。
著者らは、患者の病歴が提供されるかどうかが GPT-4V の答えに大きな影響を与えることを発見しました。病歴が提供されている場合、GPT-4V は画像内の潜在的な異常について推論するためのキー ポイントとして使用することが多く、病歴が提供されていない場合、GPT-4V は画像をキー ポイントとして使用する可能性が高くなります。通常のケースが分析されます。
著者らは、GPT-4V の位置決め効果が低いのは主に次の理由によると考えています: まず、GPT-4V は位置決めプロセス中に常に遠くなってしまいます。真の境界のボックス、第 2 に、同じ画像の複数ラウンドの繰り返し予測で重大なランダム性が示されます。第 3 に、GPT-4V は明らかな偏りを示します。たとえば、脳は最下位にあるはずです。
GPT-4V は、一連の相互作用にわたって正しくなるように応答を変更できます。たとえば、記事に示されている例では、著者は子宮内膜症の MRI 画像を入力します。 GPT-4V は当初、骨盤 MRI を膝 MRI として誤分類し、不正確な出力をもたらしました。しかし、ユーザーは GPT-4V との複数回の対話を通じてそれを修正し、最終的に正確な診断を下しました。
GPT-4V は、構造的には非常に完全かつ詳細に見えるレポートを常に生成しますが、多くの場合、画像内の異常領域が明らかであっても、その内容は依然として患者を正常であるとみなします。
GPT-4V は、一般的な画像とまれな画像でパフォーマンスに大きな違いがあり、また、異なる身体システムでは明らかなパフォーマンスの違いも示します。さらに、同じ医用画像の分析では、プロンプトが変化するため、一貫性のない結果が生じる可能性があります。たとえば、GPT-4V は、「この脳 CT の診断は何ですか?」というプロンプトの下で、特定の画像を異常であると判断します。通常と同じ画像を考慮してレポートします。この矛盾は、臨床診断における GPT-4V のパフォーマンスが不安定で信頼性が低い可能性があることを浮き彫りにしています。
著者らは、GPT-4V が医療分野での Q&A での潜在的な誤用を防ぐための安全保護措置を確立し、ユーザーが安全に使用できることを確認しました。たとえば、GPT-4Vは「この胸部X線写真の診断を教えてください」と診断を求められた場合、回答を拒否したり、「私は専門的な医学的アドバイスの代わりではありません。」と強調したりすることがあります。 」ほとんどの場合、GPT-4V は不確実性を表現するために「〜であると思われる」または「〜である可能性がある」を含むフレーズを使用する傾向があります。
病理学ケースセクション
さらに、病理画像のレポート生成と医療診断における GPT-4V の機能を調査するために、著者らは、さまざまな組織からの悪性腫瘍の 20 枚の病理画像に対して画像ブロック レベルのテストを実施し、次の結論を下しました。以下の結論:
すべてのテストケースにおいて、GPT-4V はすべての病理画像 (H&E 染色された病理組織画像) のモダリティを正確に識別できます。
医学的ヒントのない病理画像が与えられた場合、GPT-4V は画像の特徴を説明する構造化された詳細なレポートを生成できます。 20件中7件は「組織構造」「細胞の性質」「基質」「腺構造」「核」などの用語を用いて明確にリストアップできます
Atas ialah kandungan terperinci 178 muka surat! Penilaian kes komprehensif pertama GPT-4V (ision) dalam bidang perubatan: masih terdapat jarak dari aplikasi klinikal dan membuat keputusan praktikal. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 aritmetik binari
aritmetik binari
 Cara menggunakan shuffle
Cara menggunakan shuffle
 Bagaimana untuk membeli syiling Ripple sebenar
Bagaimana untuk membeli syiling Ripple sebenar
 Bagaimana untuk memulakan semula perkhidmatan dalam rangka kerja swoole
Bagaimana untuk memulakan semula perkhidmatan dalam rangka kerja swoole
 arahan telnet
arahan telnet
 penggunaan fungsi informix
penggunaan fungsi informix
 Bagaimana untuk menetapkan sempadan bertitik css
Bagaimana untuk menetapkan sempadan bertitik css
 Kedudukan terkini pertukaran mata wang digital
Kedudukan terkini pertukaran mata wang digital
 Apakah tujuh prinsip spesifikasi kod PHP?
Apakah tujuh prinsip spesifikasi kod PHP?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



