Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Pengarang artikel ini adalah dari Universiti Zhejiang, Makmal Kepintaran Buatan Shanghai, Universiti China Hong Kong, Universiti Sydney dan Universiti Oxford. Senarai pengarang: Wu Yixuan, Wang Yizhou, Tang Shixiang, Wu Wenhao, He Tong, Wanli Ouyang, Philip Torr, Jian Wu. Antaranya, pengarang bersama pertama Wu Yixuan ialah pelajar kedoktoran di Universiti Zhejiang, dan Wang Yizhou ialah pembantu penyelidik saintifik di Makmal Kepintaran Buatan Shanghai. Pengarang yang sepadan Tang Shixiang ialah penyelidik pasca doktoral di Universiti Cina Hong Kong.
Model Bahasa Besar Berbilang Modal (MLLM) telah menunjukkan keupayaan yang mengagumkan dalam tugasan yang berbeza, walaupun begitu, potensi model ini dalam tugas pengesanan masih dipandang remeh. Apabila koordinat yang tepat diperlukan dalam tugas pengesanan objek yang kompleks, halusinasi MLLM sering menyebabkan mereka terlepas objek sasaran atau memberikan kotak sempadan yang tidak tepat. Untuk mendayakan MLLM untuk pengesanan, kerja sedia ada bukan sahaja memerlukan pengumpulan sejumlah besar set data arahan berkualiti tinggi, tetapi juga memperhalusi model sumber terbuka. Walaupun memakan masa dan susah payah, ia juga gagal memanfaatkan keupayaan pemahaman visual yang lebih berkuasa bagi model sumber tertutup. Untuk tujuan ini, Universiti Zhejiang, bersama Makmal Kepintaran Buatan Shanghai dan Universiti Oxford, mencadangkan DetToolChain, paradigma segera baharu yang mengeluarkan keupayaan pengesanan model bahasa besar berbilang mod. Model berbilang modal yang besar boleh belajar untuk mengesan dengan tepat tanpa latihan. Penyelidikan yang berkaitan telah dimasukkan dalam ECCV 2024. Untuk menyelesaikan masalah MLLM dalam tugas pengesanan, DetToolChain bermula dari tiga perkara: (1) Reka bentuk gesaan visual untuk pengesanan, yang lebih langsung dan berkesan untuk MLLM daripada gesaan tekstual tradisional, (. 2) pecahkan tugas pengesanan terperinci kepada tugas kecil dan mudah, (3) gunakan rantaian pemikiran untuk mengoptimumkan hasil pengesanan secara beransur-ansur, dan elakkan ilusi model berbilang modal yang besar sebanyak mungkin. Sejajar dengan pandangan di atas, DetToolChain mengandungi dua reka bentuk utama: (1) Set komprehensif gesaan pemprosesan visual (gesaan pemprosesan visual), yang dilukis terus dalam imej dan boleh mengecilkan jurang antara maklumat visual dan perbezaan maklumat teks. (2) Satu set penaakulan pengesanan yang komprehensif mendorong untuk meningkatkan pemahaman spatial sasaran pengesanan dan secara beransur-ansur menentukan lokasi sasaran tepat akhir melalui rantaian alat pengesanan penyesuaian sampel. Dengan menggabungkan DetToolChain dengan MLLM, seperti GPT-4V dan Gemini, pelbagai tugas pengesanan boleh disokong tanpa penalaan arahan, termasuk pengesanan perbendaharaan kata terbuka, pengesanan sasaran perihalan, pemahaman ungkapan rujukan dan pengesanan sasaran berorientasikan . 
- Tajuk kertas: DetToolChain: Paradigma Mendorong Baharu untuk Melancarkan Keupayaan Pengesanan MLLM
- Pautan kertas: https://arxiv.org.1
803
...
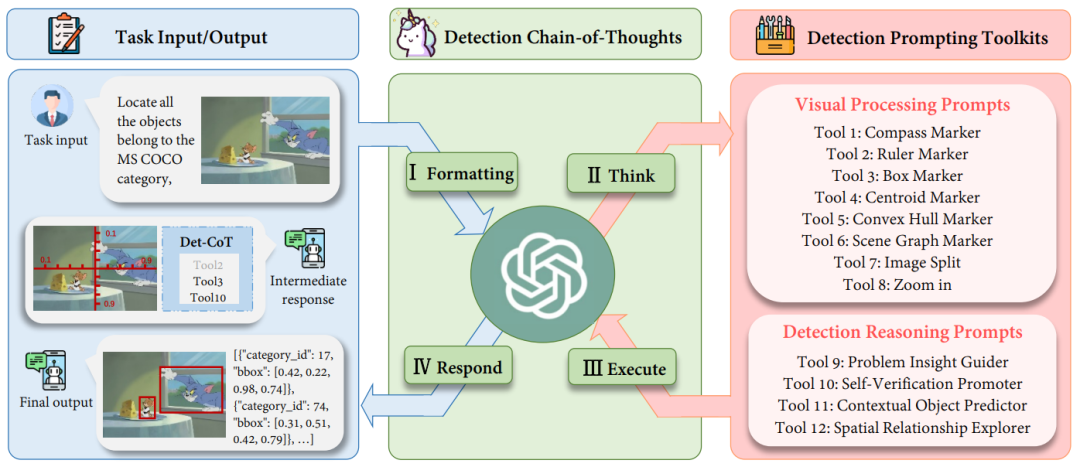
I. Memformat: Tukar format input asal tugasan ke dalam templat arahan yang sesuai sebagai input kepada MLLM II tugaskan ke dalam subtugas yang lebih mudah dan pilih petua yang berkesan daripada kit alat petua pengesanan ( gesaan); dan kembalikan jawapan akhir (jawapan akhir). Kit Alat Gesaan Pengesanan: Gesaan Pemprosesan VisualRajah 2: Gambarajah skematik gesaan pemprosesan visual. Kami mereka bentuk (1) Penguat Serantau, (2) Piawaian Pengukuran Spatial, (3) Penghurai Imej Pemandangan untuk meningkatkan keupayaan pengesanan MLLM daripada perspektif yang berbeza. Seperti yang ditunjukkan dalam Rajah 2, (1) Penguat Serantau bertujuan untuk meningkatkan keterlihatan MLLM pada kawasan yang diminati (ROI), termasuk memotong imej asal kepada sub-rantau yang berbeza, memfokuskan pada sub-rantau di mana kawasan sasaran terletak di samping itu, fungsi zum membolehkan pemerhatian terperinci bagi sub-kawasan tertentu dalam imej. (2) Piawaian Pengukuran Spatial menyediakan rujukan yang lebih jelas untuk pengesanan sasaran dengan menindih pembaris dan kompas dengan skala linear pada imej asal, seperti yang ditunjukkan dalam Rajah 2 (2). Pembaris dan kompas bantu membolehkan MLLM mengeluarkan koordinat dan sudut yang tepat menggunakan rujukan translasi dan putaran yang ditindih pada imej. Pada asasnya, garisan tambahan ini memudahkan tugas pengesanan, membolehkan MLLM membaca koordinat objek dan bukannya meramalkannya secara langsung. (3) Penghurai Imej Adegan menandakan kedudukan atau hubungan objek yang diramalkan, dan menggunakan maklumat ruang dan kontekstual untuk mencapai pemahaman hubungan ruang bagi imej. Penghurai Imej Pemandangan boleh dibahagikan kepada dua kategori: Pertama, untuk objek sasaran tunggal , kami melabel objek yang diramalkan dengan centroid, badan cembung dan kotak sempadan dengan nama label dan indeks kotak. Penanda ini mewakili maklumat kedudukan objek dalam format yang berbeza, membolehkan MLLM mengesan pelbagai objek dengan bentuk dan latar belakang yang berbeza, terutamanya objek dengan bentuk yang tidak sekata atau objek yang sangat tertutup. Contohnya, penanda badan cembung menandakan titik sempadan objek dan menyambungkannya ke dalam badan cembung untuk meningkatkan prestasi pengesanan objek berbentuk sangat tidak sekata. Kedua, untuk berbilang objektif, kami menyambungkan pusat objek berbeza melalui penanda graf pemandangan untuk menyerlahkan hubungan antara objek dalam imej. Berdasarkan graf adegan, MLLM boleh memanfaatkan keupayaan penaakulan kontekstualnya untuk mengoptimumkan kotak sempadan yang diramalkan dan mengelakkan halusinasi. Sebagai contoh, seperti yang ditunjukkan dalam Rajah 2 (3), Jerry ingin makan keju, jadi kotak sempadan mereka haruslah sangat dekat. Kit Alat Gesaan Penaakulan Pengesanan: Gesaan Penaakulan Pengesanan
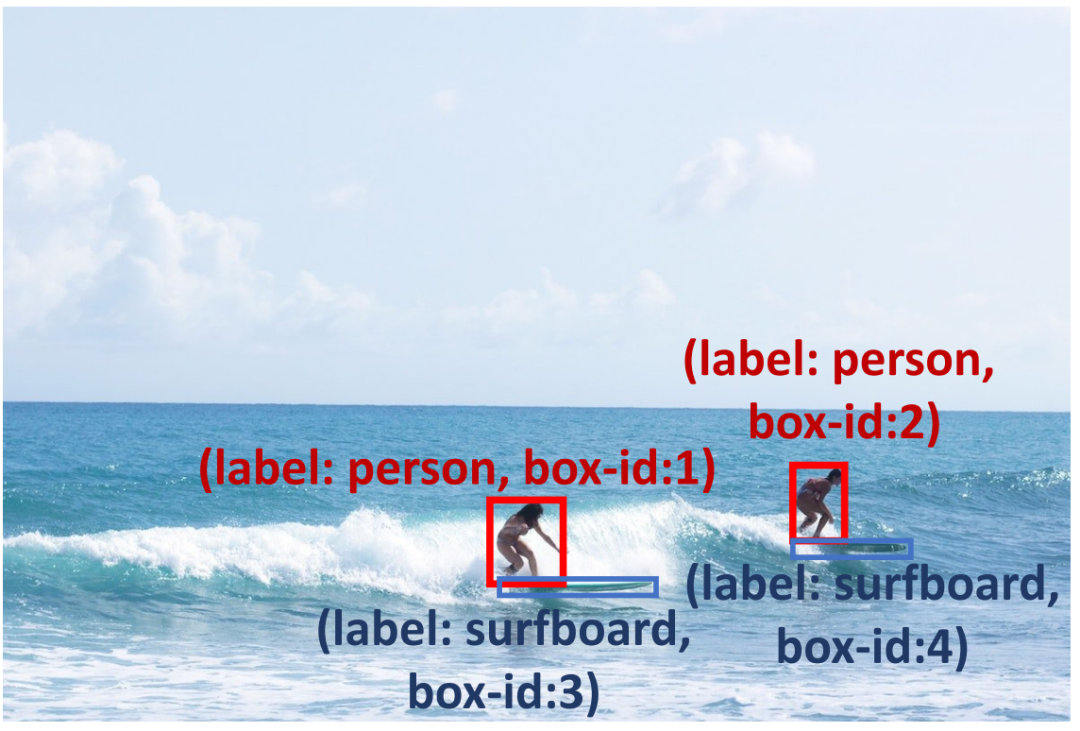
Untuk meningkatkan kebolehpercayaan kotak ramalan, kami menjalankan gesaan penaakulan pengesanan (ditunjukkan dalam Jadual 1 kemungkinan masalah) . Pertama, kami mencadangkan Problem Insight Guider, yang menyerlahkan masalah sukar dan menyediakan cadangan pengesanan yang berkesan dan contoh serupa untuk imej pertanyaan. Sebagai contoh, untuk Rajah 3, Panduan Wawasan Masalah mentakrifkan pertanyaan sebagai masalah pengesanan objek kecil dan mencadangkan penyelesaiannya dengan mengezum masuk pada kawasan papan luncur. Kedua, untuk memanfaatkan keupayaan spatial dan kontekstual yang wujud bagi MLLM, kami mereka bentuk Penjelajah Perhubungan Spatial dan Peramal Objek Kontekstual untuk memastikan hasil pengesanan konsisten dengan akal sehat. Seperti yang ditunjukkan dalam Rajah 3, papan luncur mungkin berlaku bersama lautan (pengetahuan kontekstual), dan perlu ada papan luncur berhampiran kaki peluncur (pengetahuan ruang). Tambahan pula, kami menggunakan Promoter Pengesahan Kendiri untuk meningkatkan ketekalan respons merentas berbilang pusingan. Untuk meningkatkan lagi keupayaan penaakulan MLLM, kami menggunakan kaedah gesaan yang digunakan secara meluas, seperti perbahasan dan nyahpepijat kendiri. Sila lihat teks asal untuk penerangan terperinci.
Pembayang inferens pengesanan boleh membantu MLLM menyelesaikan masalah pengesanan objek kecil, contohnya, menggunakan akal untuk mencari papan luncur di bawah kaki seseorang dan menggalakkan model mengesan papan luncur di lautan.
experiment: Anda boleh melepasi kaedah penalaan halus tanpa latihan yang ditunjukkan dalam jadual seperti yang ditunjukkan dalam 2, kami menilai kaedah kami pada pengesanan perbendaharaan kata terbuka (OVD) , menguji keputusan AP50 pada 17 kelas baharu, 48 kelas asas dan semua kelas dalam penanda aras COCO OVD. Keputusan menunjukkan bahawa prestasi kedua-dua GPT-4V dan Gemini meningkat dengan ketara menggunakan DetToolChain kami. 参照式の理解における私たちの方法の有効性を実証するために、RefCOCO、RefCOCO+、および RefCOCOg データセットで私たちの方法を他のゼロショット法と比較します (表 5)。 RefCOCO では、DetToolChain は、val、test-A、および test-B で GPT-4V ベースラインのパフォーマンスをそれぞれ 44.53%、46.11%、および 24.85% 向上させ、ゼロショット条件下での DetToolChain の優れた参照式の理解とパフォーマンスを実証しました。 Atas ialah kandungan terperinci ECCV 2024 |. Untuk meningkatkan prestasi tugas pengesanan GPT-4V dan Gemini, anda memerlukan paradigma segera ini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!






 WeChat memulihkan sejarah sembang
WeChat memulihkan sejarah sembang
 Apakah pernyataan untuk memadam jadual dalam sql
Apakah pernyataan untuk memadam jadual dalam sql
 Bagaimana untuk membuka fail apk
Bagaimana untuk membuka fail apk
 Cara menggunakan shuffle
Cara menggunakan shuffle
 Komponen utama yang membentuk CPU
Komponen utama yang membentuk CPU
 Bagaimana untuk mematikan autolengkap yang hebat
Bagaimana untuk mematikan autolengkap yang hebat
 apakah fail
apakah fail
 Berapa tinggi Ethereum akan pergi?
Berapa tinggi Ethereum akan pergi?
 Apakah maksud kelas dalam bahasa c?
Apakah maksud kelas dalam bahasa c?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



