

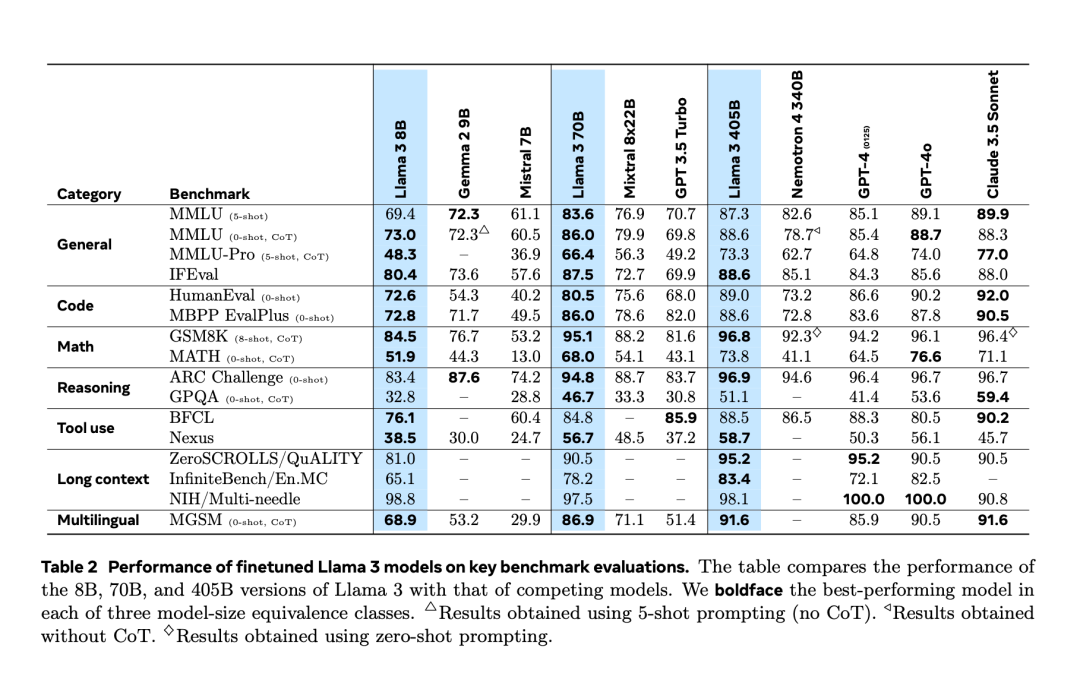
Selepas mengalami "kebocoran tidak sengaja" dua hari lebih awal, akhirnya Llama 3.1 dikeluarkan secara rasmi malam tadi. Llama 3.1 memanjangkan panjang konteks kepada 128K dan tersedia dalam versi 8B, 70B dan 405B, sekali lagi secara bersendirian meningkatkan bar untuk persaingan pada trek model besar. Bagi komuniti AI, kepentingan paling penting Llama 3.1 405B ialah ia menyegarkan had atas keupayaan model asas sumber terbuka, pegawai Meta berkata dalam satu siri tugasan, prestasinya adalah setanding dengan yang terbaik tertutup model sumber. Jadual di bawah menunjukkan prestasi model Siri Llama 3 semasa pada penanda aras utama. Ia boleh dilihat bahawa prestasi model 405B sangat hampir dengan GPT-4o.

Meta meningkatkan prapemprosesan model Llama dan saluran paip Curation bagi data pra-latihan, serta jaminan kualiti dan kaedah penapisan data selepas latihan.
Meta percaya bahawa terdapat tiga tuil utama untuk pembangunan model asas berkualiti tinggi: pengurusan data, skala dan kerumitan.
Atas ialah kandungan terperinci Bagaimana untuk mencipta model sumber terbuka yang boleh mengalahkan GPT-4o? Mengenai Llama 3.1 405B, Meta ditulis dalam kertas ini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah ciri baharu Hongmeng OS 3.0?
Apakah ciri baharu Hongmeng OS 3.0?
 penyelesaian laluan fakepath
penyelesaian laluan fakepath
 Apakah itu Bitcoin Futures ETF?
Apakah itu Bitcoin Futures ETF?
 Penjelasan terperinci tentang penggunaan arahan netsh
Penjelasan terperinci tentang penggunaan arahan netsh
 Perbezaan antara indeks dan termasuk
Perbezaan antara indeks dan termasuk
 apa yang okx
apa yang okx
 ps keluar kekunci pintasan skrin penuh
ps keluar kekunci pintasan skrin penuh
 Bagaimana untuk meningkatkan peminat Douyin dengan cepat dan berkesan
Bagaimana untuk meningkatkan peminat Douyin dengan cepat dan berkesan
 Terdapat beberapa fungsi output dan input dalam bahasa C
Terdapat beberapa fungsi output dan input dalam bahasa C








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



