
 Peranti teknologi
AI
Ejen tafsiran serentak model besar Byte mempunyai tahap tafsiran serentak yang setanding dengan manusia sejak awal lagi.
Peranti teknologi
AI
Ejen tafsiran serentak model besar Byte mempunyai tahap tafsiran serentak yang setanding dengan manusia sejak awal lagi.
Ejen tafsiran serentak model besar Byte mempunyai tahap tafsiran serentak yang setanding dengan manusia sejak awal lagi.

Sama ada penyimpangan lidah dengan pertuturan yang sangat pantas dan sebutan yang kompleks, bahasa Cina klasik yang indah atau sembang santai yang penuh dengan dadakan dan inspirasi, model ini boleh memberikan hasil terjemahan yang tepat dan tulen dengan lancar dan semula jadi.
Dalam beberapa tahun kebelakangan ini, kecerdasan buatan (AI), terutamanya AI yang diwakili oleh model bahasa besar (LLM), berkembang pada kadar yang membimbangkan. Model ini digunakan dalam pelbagai tugas pemprosesan bahasa semula jadi. Walau bagaimanapun, walaupun terdapat kejayaan dalam banyak bidang, tafsiran serentak (Simultaneous Interpretation, SI), yang mewakili tahap tertinggi bahasa manusia, masih menjadi masalah yang belum dapat diatasi sepenuhnya.
Perisian tafsiran serentak tradisional di pasaran biasanya menggunakan kaedah model bertingkat, iaitu pengecaman pertuturan automatik (ASR) dilakukan terlebih dahulu, dan kemudian terjemahan mesin (MT) dilakukan. Terdapat masalah yang ketara dengan pendekatan ini - penyebaran ralat. Ralat dalam proses ASR secara langsung akan menjejaskan kualiti terjemahan seterusnya, yang membawa kepada pengumpulan ralat yang serius. Di samping itu, disebabkan keperluan kependaman rendah yang terhad, sistem tafsiran serentak tradisional biasanya hanya menggunakan model kecil dengan prestasi yang lemah, yang mewujudkan kesesakan apabila berhadapan dengan senario aplikasi praktikal yang kompleks dan boleh diubah.
Penyelidik dari pasukan Penyelidikan ByteDance telah melancarkan ejen tafsiran serentak hujung ke hujung: Ejen Rentas Bahasa - Tafsiran Serentak, CLASI Kesannya hampir dengan tafsiran serentak peringkat buatan profesional, menunjukkan potensi besar dan keupayaan teknikal Termaju. CLASI mengguna pakai seni bina hujung ke hujung untuk mengelakkan masalah penyebaran ralat dalam model lata Ia bergantung pada keupayaan pemahaman pertuturan model asas pundi kacang besar dan kumpulan ucapan model pundi kacang besar memperoleh ilmu dari luar, dan akhirnya membentuk Sistem tafsiran serentak yang setanding dengan prestasi manusia.

Alamat kertas: https://byteresearchcla.github.io/clasi/technical_report.pdf -
Paparan halaman: https://byteresearchcla.github.io/clasi/ Tunjukkan
Video Demo: Pertama, gunakan beberapa video dadakan untuk mengalami kesan CLASI Semua sari kata dirakam dan dikeluarkan dalam masa nyata. Kita dapat melihat bahawa sama ada ia adalah pemutar lidah dengan pertuturan yang pantas dan sebutan yang kompleks, bahasa Cina klasik yang indah atau sembang santai yang penuh dengan dadakan dan inspirasi, model ini boleh memberikan hasil terjemahan yang tepat dan sahih dengan lancar dan semula jadi. Apatah lagi, CLASI cemerlang dalam kepakarannya - menterjemah adegan persidangan. .
Perbandingan kuantitatif
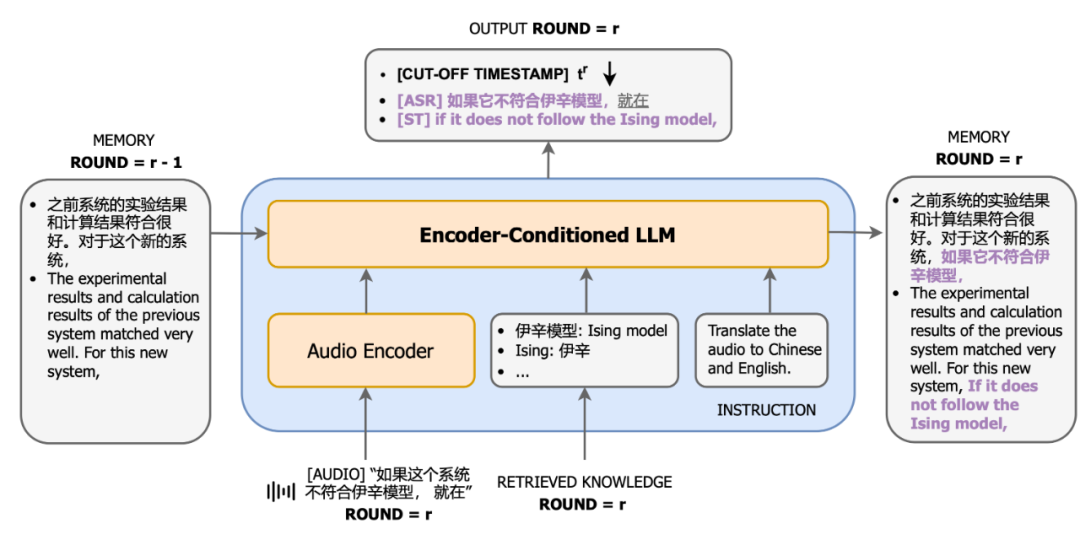
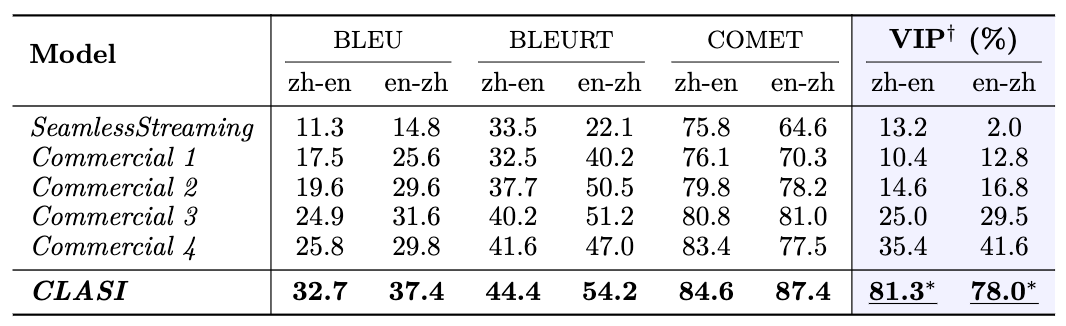
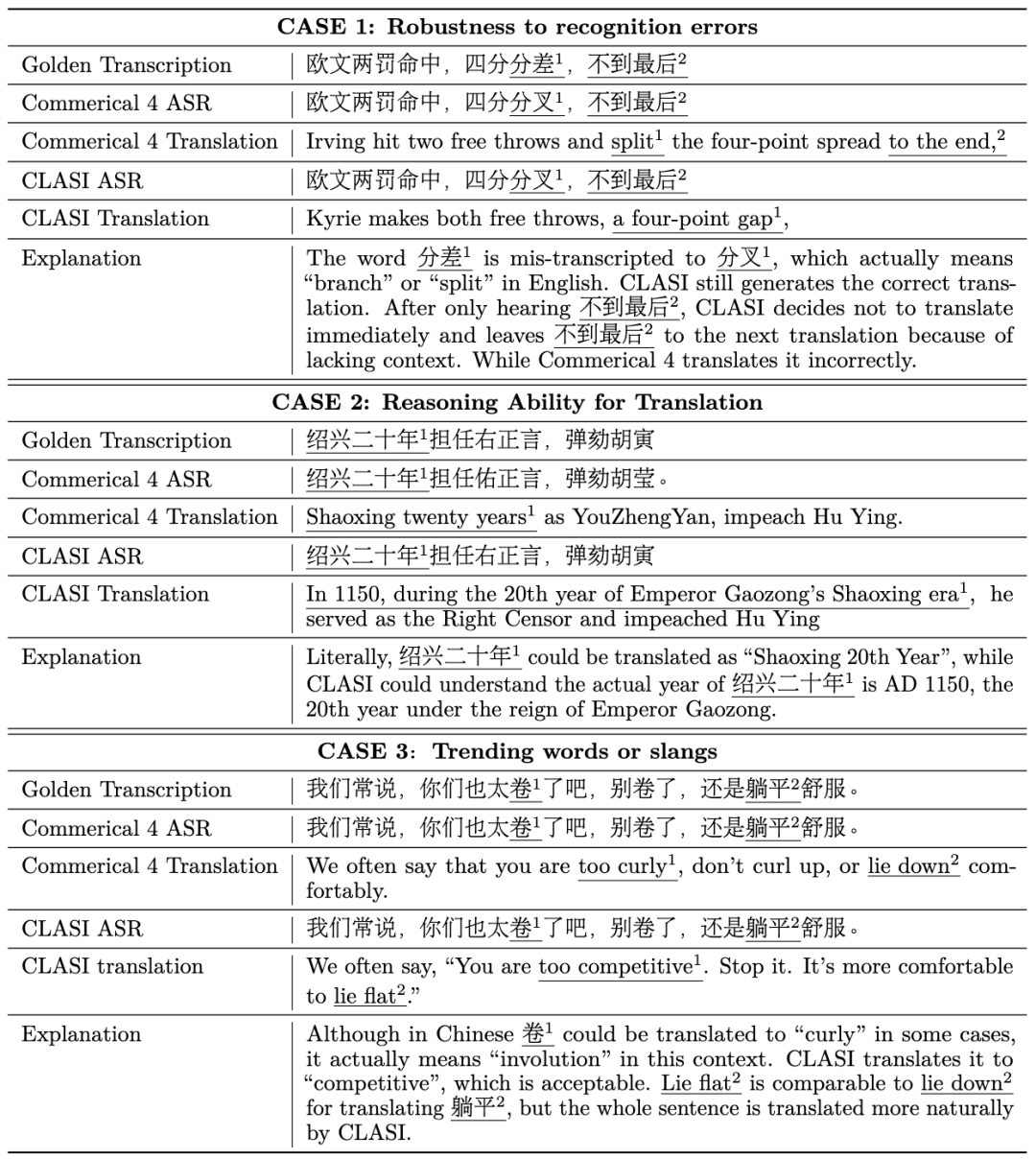
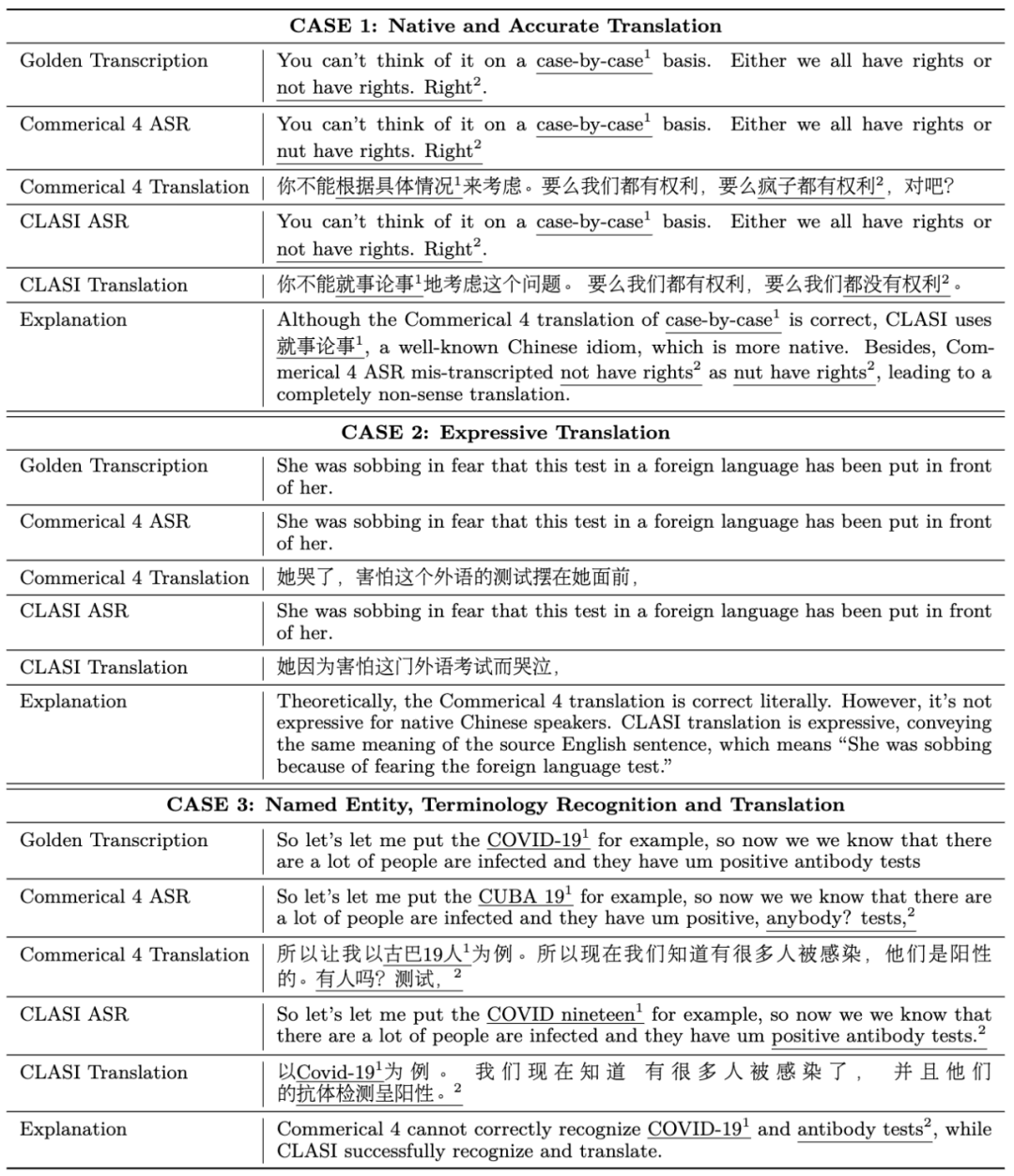
: Para penyelidik menjemput jurubahasa serentak profesional untuk menjalankan penilaian manual dalam empat bidang berbeza dari segi terjemahan Cina-Inggeris dan Inggeris-Cina, dan menggunakan indeks penilaian yang konsisten dengan tafsiran serentak manual: perkadaran maklumat yang berkesan (sistem peratusan) . Seperti yang dapat dilihat dalam rajah, sistem CLASI jauh mendahului semua sistem komersial dan sistem SOTA sumber terbuka, malah mencapai atau melebihi tahap tafsiran serentak manusia pada beberapa set ujian (secara amnya dipercayai bahawa tahap purata manusia tafsiran serentak adalah kira-kira 80%). In Bezug auf die Systemarchitektur übernimmt CLASI eine auf LLM-Agenten basierende Architektur (links in der Abbildung unten), die Simultandolmetschen als eine Reihe einfacher und koordinierter Vorgänge definiert, einschließlich des Lesens von Audiostreams, des Abrufens (optional) und des Lesens des Speichers. Speicher, Ausgabe usw. aktualisieren. Der gesamte Prozess wird autonom durch ein großes Sprachmodell gesteuert und so ein effizientes Gleichgewicht zwischen Echtzeitleistung und Übersetzungsqualität erreicht. Das System kann die Verarbeitungsstrategien jedes Links flexibel an den tatsächlichen Bedarf anpassen und so sicherstellen, dass die Genauigkeit und Kohärenz der übersetzten Inhalte erhalten bleibt und gleichzeitig Informationen effizient übertragen werden. Das zugrunde liegende Modell von CLASI ist ein vom Encoder bedingter LLM, der auf riesigen Mengen unbeaufsichtigter und überwachter Daten vorab trainiert wurde. Die Systemarchitektur des CLASI-Modells ist in der folgenden Abbildung dargestellt. Abbildung 1: Diagramm, das den gesamten Betriebsablauf von CLASI zeigt. In Schritt 1 verarbeitet CLASI die aktuell eingegebenen Audiodaten. Anschließend wird der Sucher aktiviert (optional), um relevante Informationen aus der benutzerdefinierten Wissensdatenbank abzurufen. In diesem Beispiel kann die Verwendung des Übersetzungspaars „Ising-Modell: Ising-Modell“ in der Wissensdatenbank dazu beitragen, dass das Modell die richtige Übersetzung ausgibt. In Schritt 3 lädt CLASI die Transkription (optional) und die Übersetzung aus dem Speicher der vorherigen Runde. Als nächstes (Schritte 4 und 5) aktiviert CLASI möglicherweise die Chain of Thoughts (CoT), um die Transliterations- (optional) und Übersetzungsergebnisse auszugeben, und aktualisiert dann seinen Speicher. Kehren Sie abschließend zu Schritt 1 zurück, um die nächste Rederunde zu verarbeiten. Abbildung 2: Strukturdiagramm von CLASI. In Runde r verwendet CLASI als Eingabe den aktuellen Audiostream, den vorherigen Speicher (r-1) und das abgerufene Wissen (falls vorhanden). CLASI gibt eine Antwort basierend auf den gegebenen Anweisungen aus und aktualisiert dann den Speicher. Gleichzeitig gibt CLASI auch den Deadline-Zeitstempel des ab sofort letzten semantischen Fragments aus. Für das gegebene Beispiel wird das, was vor der Phrase „kurz davor“ steht, als vollständiges semantisches Fragment betrachtet, sodass der Cutoff-Zeitstempel direkt vor dieser Phrase liegt. Experimentelle Ergebnisse Tabelle 1: Bei der manuellen Auswertung des gültigen Feldanteils (Valid Information Proportion, VIP) übertraf das CLASI-System alle anderen Konkurrenzprodukte deutlich, und zwar in beiden Sprachrichtungen An Es wurde eine Genauigkeit von über 78 % erreicht. Im Allgemeinen kann davon ausgegangen werden, dass die Genauigkeit des menschlichen Simultandolmetschens über 70 % liegt und idealerweise 95 % erreichen kann, wobei Forscher eine Genauigkeit von 80 % als durchschnittlichen Standard für hochqualifizierte menschliche Übersetzer verwenden. Beispielanalyse Chinesisch nach Englisch: Englisch nach Chinesisch: Es zeigt sich, dass die Übersetzung von CLASI in vielen Aspekten deutlich besser ist als kommerzielle Systeme. Zusammenfassung Forscher des ByteDance Research-Teams schlugen einen Simultandolmetscher vor, der auf dem großen Beanbao-Modell basiert: CLASI. Dank umfangreichem Vortraining und Nachahmungslernen übertrifft CLASI die Leistung bestehender automatischer Simultandolmetschersysteme bei der menschlichen Bewertung deutlich und erreicht fast das Niveau menschlicher Simultandolmetschen. 1. Forscher schlagen eine datengesteuerte Alphabetisierungsstrategie vor, die professionelle menschliche Übersetzer nachahmt. Diese Strategie gleicht Übersetzungsqualität und Latenz problemlos aus, ohne dass ein komplexer menschlicher Vorentwurf erforderlich ist. Im Gegensatz zu den meisten kommerziellen Systemen, die die Ausgabe während der Übersetzung häufig umschreiben, um die Qualität zu verbessern, garantiert diese Strategie, dass die gesamte Ausgabe deterministisch ist und gleichzeitig eine hohe Qualität beibehält. 2. Menschliche Übersetzer müssen im Allgemeinen Simultandolmetscherinhalte vorbereiten. Davon inspiriert führten Forscher einen multimodalen Retrieval-Augmented-Generierungsprozess (MM-RAG) ein, um LLM in Echtzeit über domänenspezifisches Wissen zu verfügen. Das vorgeschlagene Modul verbessert die Übersetzungsqualität bei minimalem Rechenaufwand während der Inferenz weiter. 3. Forscher arbeiteten eng mit professionellen menschlichen Simultandolmetschern zusammen, um eine neue manuelle Bewertungsstrategie „Valid Information Proportion“ (VIP) zu entwickeln und detaillierte Richtlinien zu veröffentlichen. Gleichzeitig wurde auch ein domänenübergreifendes manuelles Annotationstestset für die Übersetzung langer Sprache veröffentlicht, das realen Szenarien näher kommt.  Seni Bina Sistem
Seni Bina Sistem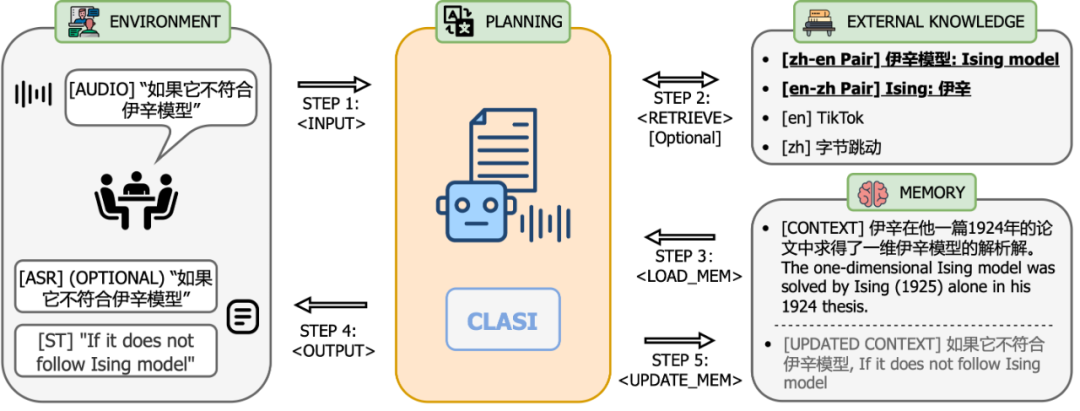
Atas ialah kandungan terperinci Ejen tafsiran serentak model besar Byte mempunyai tahap tafsiran serentak yang setanding dengan manusia sejak awal lagi.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Tetapi mungkin dia tidak dapat mengalahkan lelaki tua di taman itu? Sukan Olimpik Paris sedang rancak berlangsung, dan pingpong telah menarik perhatian ramai. Pada masa yang sama, robot juga telah membuat penemuan baru dalam bermain pingpong. Sebentar tadi, DeepMind mencadangkan ejen robot pembelajaran pertama yang boleh mencapai tahap pemain amatur manusia dalam pingpong yang kompetitif. Alamat kertas: https://arxiv.org/pdf/2408.03906 Sejauh manakah robot DeepMind bermain pingpong? Mungkin setanding dengan pemain amatur manusia: kedua-dua pukulan depan dan pukulan kilas: pihak lawan menggunakan pelbagai gaya permainan, dan robot juga boleh bertahan: servis menerima dengan putaran yang berbeza: Walau bagaimanapun, keamatan permainan nampaknya tidak begitu sengit seperti lelaki tua di taman itu. Untuk robot, pingpong
 Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Pada 21 Ogos, Persidangan Robot Dunia 2024 telah diadakan dengan megah di Beijing. Jenama robot rumah SenseTime "Yuanluobot SenseRobot" telah memperkenalkan seluruh keluarga produknya, dan baru-baru ini mengeluarkan robot permainan catur AI Yuanluobot - Edisi Profesional Catur (selepas ini dirujuk sebagai "Yuanluobot SenseRobot"), menjadi robot catur A pertama di dunia untuk rumah. Sebagai produk robot permainan catur ketiga Yuanluobo, robot Guoxiang baharu telah melalui sejumlah besar peningkatan teknikal khas dan inovasi dalam AI dan jentera kejuruteraan Buat pertama kalinya, ia telah menyedari keupayaan untuk mengambil buah catur tiga dimensi melalui cakar mekanikal pada robot rumah, dan melaksanakan Fungsi mesin manusia seperti bermain catur, semua orang bermain catur, semakan notasi, dsb.
 Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Permulaan sekolah akan bermula, dan bukan hanya pelajar yang akan memulakan semester baharu yang harus menjaga diri mereka sendiri, tetapi juga model AI yang besar. Beberapa ketika dahulu, Reddit dipenuhi oleh netizen yang mengadu Claude semakin malas. "Tahapnya telah banyak menurun, ia sering berhenti seketika, malah output menjadi sangat singkat. Pada minggu pertama keluaran, ia boleh menterjemah dokumen penuh 4 halaman sekaligus, tetapi kini ia tidak dapat mengeluarkan separuh halaman pun. !" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dalam siaran bertajuk "Totally disappointed with Claude", penuh dengan
 Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Dunia yang diadakan di Beijing, paparan robot humanoid telah menjadi tumpuan mutlak di gerai Stardust Intelligent, pembantu robot AI S1 mempersembahkan tiga persembahan utama dulcimer, seni mempertahankan diri dan kaligrafi dalam. satu kawasan pameran, berkebolehan kedua-dua sastera dan seni mempertahankan diri, menarik sejumlah besar khalayak profesional dan media. Permainan elegan pada rentetan elastik membolehkan S1 menunjukkan operasi halus dan kawalan mutlak dengan kelajuan, kekuatan dan ketepatan. CCTV News menjalankan laporan khas mengenai pembelajaran tiruan dan kawalan pintar di sebalik "Kaligrafi Pengasas Syarikat Lai Jie menjelaskan bahawa di sebalik pergerakan sutera, bahagian perkakasan mengejar kawalan daya terbaik dan penunjuk badan yang paling menyerupai manusia (kelajuan, beban). dll.), tetapi di sisi AI, data pergerakan sebenar orang dikumpulkan, membolehkan robot menjadi lebih kuat apabila ia menghadapi situasi yang kuat dan belajar untuk berkembang dengan cepat. Dan tangkas
 Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Pada persidangan ACL ini, para penyumbang telah mendapat banyak keuntungan. ACL2024 selama enam hari diadakan di Bangkok, Thailand. ACL ialah persidangan antarabangsa teratas dalam bidang linguistik pengiraan dan pemprosesan bahasa semula jadi Ia dianjurkan oleh Persatuan Antarabangsa untuk Linguistik Pengiraan dan diadakan setiap tahun. ACL sentiasa menduduki tempat pertama dalam pengaruh akademik dalam bidang NLP, dan ia juga merupakan persidangan yang disyorkan CCF-A. Persidangan ACL tahun ini adalah yang ke-62 dan telah menerima lebih daripada 400 karya termaju dalam bidang NLP. Petang semalam, persidangan itu mengumumkan kertas kerja terbaik dan anugerah lain. Kali ini, terdapat 7 Anugerah Kertas Terbaik (dua tidak diterbitkan), 1 Anugerah Kertas Tema Terbaik, dan 35 Anugerah Kertas Cemerlang. Persidangan itu turut menganugerahkan 3 Anugerah Kertas Sumber (ResourceAward) dan Anugerah Impak Sosial (
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Petang ini, Hongmeng Zhixing secara rasmi mengalu-alukan jenama baharu dan kereta baharu. Pada 6 Ogos, Huawei mengadakan persidangan pelancaran produk baharu Hongmeng Smart Xingxing S9 dan senario penuh Huawei, membawakan sedan perdana pintar panoramik Xiangjie S9, M7Pro dan Huawei novaFlip baharu, MatePad Pro 12.2 inci, MatePad Air baharu, Huawei Bisheng With banyak produk pintar semua senario baharu termasuk pencetak laser siri X1, FreeBuds6i, WATCHFIT3 dan skrin pintar S5Pro, daripada perjalanan pintar, pejabat pintar kepada pakaian pintar, Huawei terus membina ekosistem pintar senario penuh untuk membawa pengguna pengalaman pintar Internet Segala-galanya. Hongmeng Zhixing: Pemerkasaan mendalam untuk menggalakkan peningkatan industri kereta pintar Huawei berganding bahu dengan rakan industri automotif China untuk menyediakan
 Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Penyepaduan mendalam penglihatan dan pembelajaran robot. Apabila dua tangan robot bekerja bersama-sama dengan lancar untuk melipat pakaian, menuang teh dan mengemas kasut, ditambah pula dengan 1X robot humanoid NEO yang telah menjadi tajuk berita baru-baru ini, anda mungkin mempunyai perasaan: kita seolah-olah memasuki zaman robot. Malah, pergerakan sutera ini adalah hasil teknologi robotik canggih + reka bentuk bingkai yang indah + model besar berbilang modal. Kami tahu bahawa robot yang berguna sering memerlukan interaksi yang kompleks dan indah dengan alam sekitar, dan persekitaran boleh diwakili sebagai kekangan dalam domain spatial dan temporal. Sebagai contoh, jika anda ingin robot menuang teh, robot terlebih dahulu perlu menggenggam pemegang teko dan memastikannya tegak tanpa menumpahkan teh, kemudian gerakkannya dengan lancar sehingga mulut periuk sejajar dengan mulut cawan. , dan kemudian condongkan teko pada sudut tertentu. ini
 Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Pengenalan Persidangan Dengan perkembangan pesat sains dan teknologi, kecerdasan buatan telah menjadi kuasa penting dalam menggalakkan kemajuan sosial. Dalam era ini, kami bertuah untuk menyaksikan dan mengambil bahagian dalam inovasi dan aplikasi Kecerdasan Buatan Teragih (DAI). Kecerdasan buatan yang diedarkan adalah cabang penting dalam bidang kecerdasan buatan, yang telah menarik lebih banyak perhatian dalam beberapa tahun kebelakangan ini. Agen berdasarkan model bahasa besar (LLM) tiba-tiba muncul Dengan menggabungkan pemahaman bahasa yang kuat dan keupayaan penjanaan model besar, mereka telah menunjukkan potensi besar dalam interaksi bahasa semula jadi, penaakulan pengetahuan, perancangan tugas, dsb. AIAgent mengambil alih model bahasa besar dan telah menjadi topik hangat dalam kalangan AI semasa. Au
