

Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model persembahan cemerlang yang lain. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak kawasan.
Selain model umum, terdapat juga beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, InternVL 1.5 untuk tugasan bahasa visual (yang digunakan dalam beberapa bidang Setanding kepada GPT-4-Turbo-2024-04-09).
Sebagai "raja penyodok dalam era tergesa-gesa emas AI", NVIDIA sendiri turut memberikan sumbangan kepada bidang model terbuka, seperti siri model ChatQA yang dibangunkannya Sila rujuk laporan di laman web ini ". Model QA dialog baharu NVIDIA adalah lebih tepat daripada GPT-4, Tetapi saya telah dikritik: Kod tidak berwajaran mempunyai sedikit makna.》. Awal tahun ini, ChatQA 1.5 telah dikeluarkan, yang menyepadukan teknologi penjanaan dipertingkatkan semula (RAG) dan mengatasi prestasi GPT-4 dalam menjawab soalan perbualan.
Kini, ChatQA telah berkembang kepada versi 2.0 Hala tuju utama penambahbaikan kali ini adalah untuk mengembangkan tetingkap konteks. . masa, memanjangkan panjang tetingkap konteks LLM ialah tempat liputan penyelidikan dan pembangunan utama Contohnya, tapak ini pernah melaporkan
"Secara langsung berkembang ke panjang tak terhingga, Google Infini-Transformer menamatkan perbahasan panjang konteks". 
Kembangkan tetingkap konteks kepada 128K
Jadi, bagaimanakah NVIDIA meningkatkan tetingkap konteks Llama-3 daripada 8K kepada 128K? Pertama, mereka menyediakan korpus pra-latihan konteks yang panjang berdasarkan Slimpajama, menggunakan kaedah daripada kertas "Kejuruteraan data untuk menskalakan model bahasa kepada konteks 128k" oleh Fu et al (2024). Mereka juga membuat penemuan menarik semasa proses latihan: Berbanding dengan menggunakan token mula dan tamat asaldan
, menggunakan aksara khas sepertiuntuk memisahkan dokumen yang berbeza akan memberi kesan yang lebih baik. Mereka membuat spekulasi bahawa sebabnya ialah token
dandalam Llama-3 memberitahu model untuk mengabaikan blok teks sebelumnya selepas pra-latihan, tetapi ini tidak membantu LLM menyesuaikan diri dengan input kontekstual yang lebih panjang.
Menggunakan data konteks panjang untuk penalaan halus arahanPasukan juga mereka bentuk kaedah penalaan halus arahan yang boleh meningkatkan keupayaan pemahaman konteks panjang model dan prestasi RAG secara serentak.
Plus précisément, cette méthode de mise au point des instructions est divisée en trois étapes. Les deux premières étapes sont les mêmes que dans ChatQA 1.5, c'est-à-dire former d'abord le modèle sur l'ensemble de données de conformité aux instructions de haute qualité de 128 000, puis former sur un mélange de données de questions-réponses conversationnelles et de contexte fourni. Cependant, les contextes impliqués dans les deux étapes sont relativement courts : la longueur maximale de la séquence ne dépasse pas 4 000 jetons. Pour augmenter la taille de la fenêtre contextuelle du modèle à 128 000 jetons, l'équipe a collecté un long ensemble de données de réglage fin supervisé (SFT).
Il adopte deux méthodes de collecte :
1. Pour les séquences de données SFT inférieures à 32 ko : en utilisant des ensembles de données de contexte longs existants basés sur LongAlpaca12k, des échantillons GPT-4 d'Open Orca et des collections de données longues.
2. Pour les données dont la longueur de séquence est comprise entre 32 000 et 128 000 : en raison de la difficulté de collecter de tels échantillons SFT, ils ont choisi des ensembles de données synthétiques. Ils ont utilisé NarrativeQA, qui contient à la fois des vérités terrain et des paragraphes sémantiquement pertinents. Ils ont assemblé tous les paragraphes pertinents et inséré de manière aléatoire de vrais résumés pour simuler de vrais documents longs pour des paires de questions et réponses.
Ensuite, l'ensemble de données SFT complet et l'ensemble de données SFT court obtenu au cours des deux premières étapes sont combinés puis entraînés. Ici, le taux d'apprentissage est fixé à 3e-5 et la taille du lot est de 32.
Le récupérateur de contexte long rencontre le LLM à contexte long
Il y a quelques problèmes avec le processus RAG actuellement utilisé par LLM :
1 Afin de générer des réponses précises, la récupération bloc par bloc top-k introduira des non-. fragments de contexte négligeables. Par exemple, les anciens récupérateurs basés sur l’intégration dense ne prenaient en charge que 512 jetons.
2. Un petit top-k (comme 5 ou 10) entraînera un taux de rappel relativement faible, tandis qu'un grand top-k (comme 100) entraînera de mauvais résultats de génération car le LLM précédent ne peut pas être bien utilisé. . Contexte fragmenté.
Pour résoudre ce problème, l'équipe propose d'utiliser le récupérateur de contexte long le plus récent, qui prend en charge des milliers de jetons. Plus précisément, ils ont choisi d’utiliser le modèle d’intégration E5-mistral comme récupérateur.
Le tableau 1 compare la récupération du top-k pour différentes tailles de blocs et le nombre total de jetons dans la fenêtre contextuelle.

En comparant l'évolution du nombre de jetons de 3 000 à 12 000, l'équipe a constaté que plus il y a de jetons, meilleurs sont les résultats, ce qui a confirmé que la capacité de contexte long du nouveau modèle est effectivement bonne. Ils ont également constaté que si le nombre total de jetons est de 6 000, il existe un meilleur compromis entre coût et performances. Lorsque le nombre total de jetons a été fixé à 6 000, ils ont constaté que plus le bloc de texte était grand, meilleurs étaient les résultats. Par conséquent, dans leurs expériences, les paramètres par défaut qu’ils ont choisis étaient une taille de bloc de 1 200 et les 5 premiers blocs de texte.
Expériences
Repères d'évaluation
Afin de mener une évaluation complète et d'analyser différentes longueurs de contexte, l'équipe a utilisé trois types de repères d'évaluation :
1 Des repères de contexte longs, plus de 100 000 jetons ; 2. Benchmark de contexte moyen long, moins de 32 000 jetons ;
3. Benchmark de contexte court, moins de 4 000 jetons ;
Si une tâche en aval peut utiliser RAG, elle utilisera RAG.
RésultatsL'équipe a d'abord mené un test Needle in a Haystack basé sur des données synthétiques, puis a testé la compréhension du contexte long du modèle dans le monde réel et les capacités RAG.
1. Test d'aiguille dans une botte de foin
Llama3-ChatQA-2-70B Pouvez-vous trouver l'aiguille cible dans la mer de texte ? Il s'agit d'une tâche synthétique couramment utilisée pour tester la capacité du LLM dans un contexte long et peut être considérée comme une évaluation du niveau seuil du LLM. La figure 1 montre les performances du nouveau modèle en 128 000 jetons. On peut voir que la précision du nouveau modèle atteint 100 %. Ce test a confirmé que le nouveau modèle possède des capacités parfaites de récupération de contexte long.
 2. Évaluation de contexte longue sur 100 000 jetons
2. Évaluation de contexte longue sur 100 000 jetons
Sur des tâches réelles d'InfiniteBench, l'équipe a évalué les performances du modèle lorsque la longueur du contexte dépassait 100 000 jetons. Les résultats sont présentés dans le tableau 2.
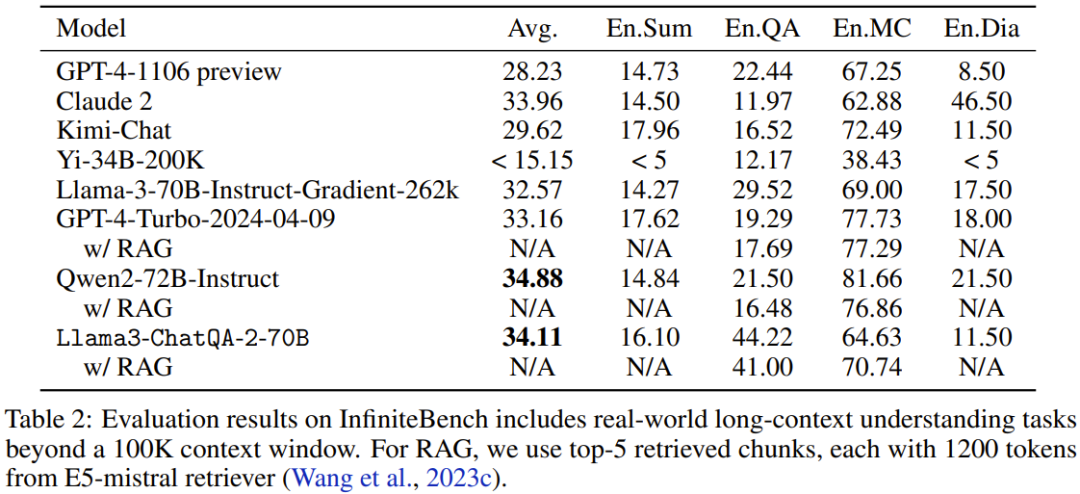 On peut voir que le nouveau modèle fonctionne mieux que de nombreux meilleurs modèles actuels, tels que GPT4-Turbo-2024-04-09 (33.16), aperçu GPT4-1106 (28.23), Llama-3-70B- Instruire -Gradient-262k (32,57) et Claude 2 (33,96). De plus, le score du nouveau modèle est très proche du score le plus élevé de 34,88 obtenu par Qwen2-72B-Instruct. Dans l’ensemble, le nouveau modèle de Nvidia est assez compétitif.
On peut voir que le nouveau modèle fonctionne mieux que de nombreux meilleurs modèles actuels, tels que GPT4-Turbo-2024-04-09 (33.16), aperçu GPT4-1106 (28.23), Llama-3-70B- Instruire -Gradient-262k (32,57) et Claude 2 (33,96). De plus, le score du nouveau modèle est très proche du score le plus élevé de 34,88 obtenu par Qwen2-72B-Instruct. Dans l’ensemble, le nouveau modèle de Nvidia est assez compétitif.
3. Évaluation des contextes moyen-longs avec un nombre de jetons inférieur à 32K
Le tableau 3 montre les performances de chaque modèle lorsque le nombre de jetons dans le contexte est inférieur à 32K.
Comme vous pouvez le constater, GPT-4-Turbo-2024-04-09 a le score le plus élevé, 51,93. Le score du nouveau modèle est de 47,37, ce qui est supérieur à Llama-3-70B-Instruct-Gradient-262k mais inférieur à Qwen2-72B-Instruct. La raison peut être que la pré-formation de Qwen2-72B-Instruct utilise fortement 32 000 jetons, alors que le corpus de pré-formation continue utilisé par l'équipe est beaucoup plus petit. En outre, ils ont constaté que toutes les solutions RAG fonctionnaient moins bien que les solutions à contexte long, ce qui indique que tous ces LLM à contexte long de pointe peuvent gérer 32 000 jetons dans leur fenêtre de contexte.
4. ChatRAG Bench : courte évaluation du contexte avec un nombre de jetons inférieur à 4K
Sur ChatRAG Bench, l'équipe a évalué les performances du modèle lorsque la longueur du contexte est inférieure à 4K tokens, voir Tableau 4.
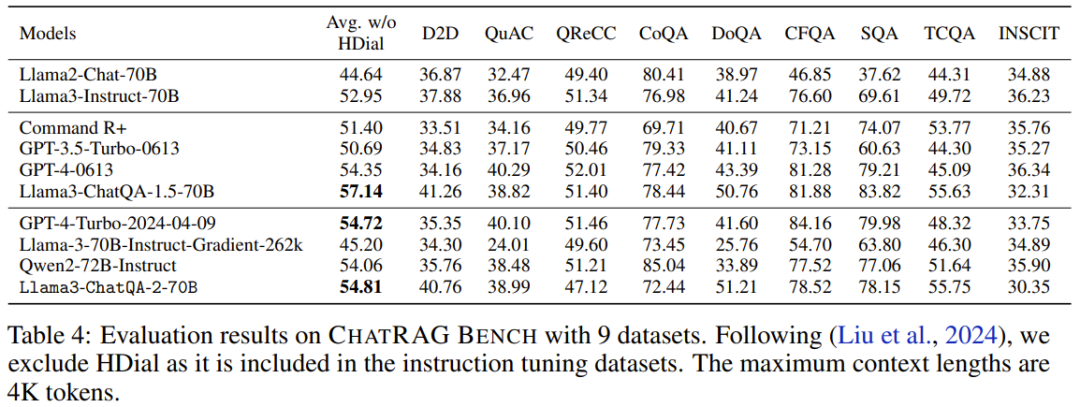
La note moyenne du nouveau modèle est de 54,81. Bien que ce résultat ne soit pas aussi bon que Llama3-ChatQA-1.5-70B, il est toujours meilleur que GPT-4-Turbo-2024-04-09 et Qwen2-72B-Instruct. Cela prouve le point : l’extension de modèles de contexte courts à des modèles de contexte longs a un coût. Cela conduit également à une direction de recherche qui mérite d'être explorée : comment élargir davantage la fenêtre contextuelle sans affecter ses performances sur des tâches contextuelles courtes ?
5. Comparaison de RAG avec un contexte long
Les tableaux 5 et 6 comparent les performances de RAG avec des solutions à contexte long lors de l'utilisation de différentes longueurs de contexte. Lorsque la longueur de la séquence dépasse 100 Ko, seuls les scores moyens pour En.QA et En.MC sont signalés car les paramètres RAG ne sont pas directement disponibles pour En.Sum et En.Dia.
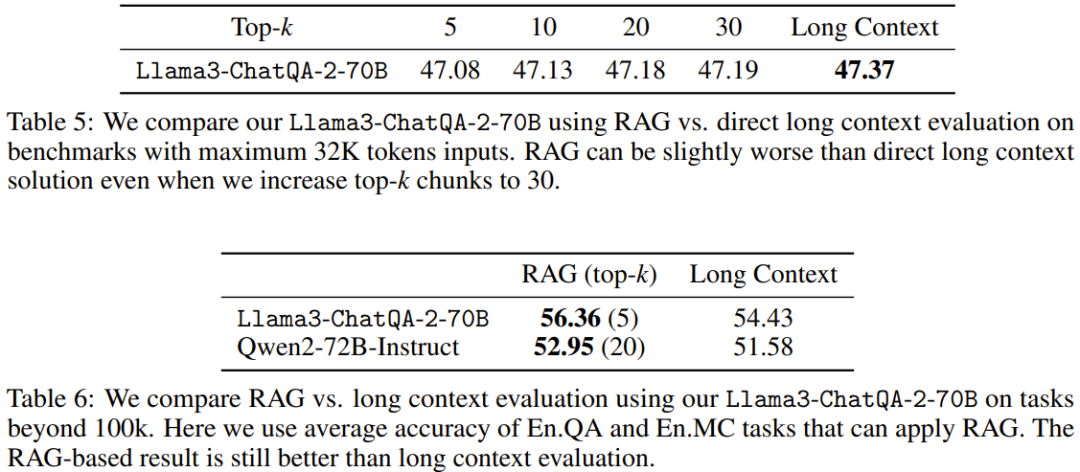
On peut voir que la solution de contexte long nouvellement proposée surpasse RAG lorsque la longueur de séquence de la tâche en aval est inférieure à 32 Ko. Cela signifie que l'utilisation de RAG entraîne des économies de coûts, mais au détriment de la précision.
D'un autre côté, RAG (top-5 pour Llama3-ChatQA-2-70B et top-20 pour Qwen2-72B-Instruct) surpasse la solution de contexte long lorsque la longueur du contexte dépasse 100K. Cela signifie que lorsque le nombre de jetons dépasse 128 000, même le meilleur LLM à contexte long actuel peut avoir des difficultés à parvenir à une compréhension et à un raisonnement efficaces. L'équipe recommande dans ce cas d'utiliser RAG autant que possible, car cela peut apporter une plus grande précision et un coût d'inférence inférieur.
Atas ialah kandungan terperinci Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyelesaikan ralat pengecam mysql yang tidak sah
Bagaimana untuk menyelesaikan ralat pengecam mysql yang tidak sah
 arahan penutupan berjadual linux
arahan penutupan berjadual linux
 Apakah yang dimaksudkan dengan lebar penuh dan separuh lebar?
Apakah yang dimaksudkan dengan lebar penuh dan separuh lebar?
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Bagaimana untuk memasang chatgpt pada telefon bimbit
 Apa itu e-mel
Apa itu e-mel
 Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
 Apakah antara muka audio?
Apakah antara muka audio?
 Perbezaan antara vscode dan visual studio
Perbezaan antara vscode dan visual studio








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



