
 Peranti teknologi
AI
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Peranti teknologi
AI
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.

Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu.
Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Simou Technology telah membangunkan set data "Spektrum Kecacatan" secara inovatif, yang menyediakan anotasi berskala besar yang terperinci dan kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "Spektrum Kecacatan" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan), klasifikasi kecacatan paling terperinci (125 kategori kecacatan), dan menyediakan pelbagai jenis kecacatan menyediakan label terperinci tahap piksel. Selain itu, set data juga menyediakan penerangan linguistik terperinci untuk setiap sampel kecacatan. Perbandingan anotasi khusus ditunjukkan dalam Rajah 1.

Rajah 1: Berbanding dengan set data industri lain, Defect Spectrum mempunyai ketepatan yang lebih tinggi dan anotasi yang lebih kaya
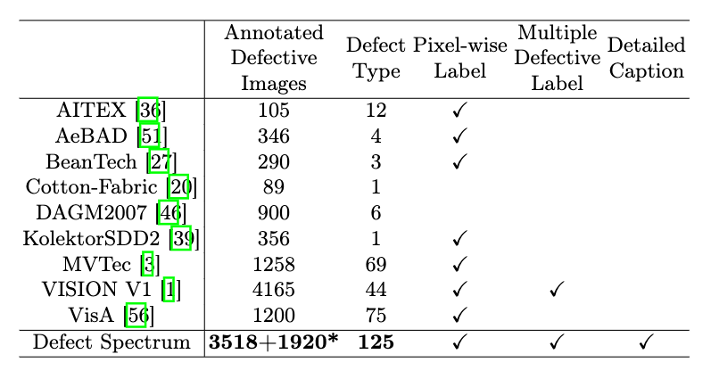
Jadual 1: Perbandingan kuantiti dan sifat Spektrum Kecacatan
"set data sedia ada yang lain " memperkenalkan pendekatan revolusioner - "DefectGen" - berdasarkan model penyebaran terkini. Dengan menggunakan sejumlah kecil data kecacatan industri untuk menjana imej dan label kecacatan tahap piksel, kaedah ini meningkatkan prestasi model pengesanan kecacatan industri dengan ketara dan dilaksanakan pada beberapa set data standard industri (seperti MVTec AD, VISION, DAGM2007 dan Cotton-Fabric) Satu kejayaan prestasi yang tidak pernah berlaku sebelum ini.
Penyelidikan terobosan ini bukan sahaja meningkatkan ketepatan pengesanan kecacatan, tetapi juga membuka kemungkinan baharu untuk aplikasi AI dalam persekitaran industri yang kompleks. Kod dan model projek telah menjadi sumber terbuka sepenuhnya. . pautan ject: https : //envision-research.github.io/Defect_Spectrum/
Github Repo: https://github.com/EnVision-Research/Defect_Spectrum 
- Memecahkan had pengesanan kecacatan tradisional dan mendekati pengeluaran sebenar
- Rajah 2: Pengeluaran industri sebenar, gelung tertutup pengesanan dan analisis kecacatan
- Dalam pengeluaran industri sebenar, keperluan kami untuk pengesanan kecacatan adalah lebih terperinci. . Kilang perlu memastikan keuntungan semasa mengawal bahagian yang rosak, seperti yang ditunjukkan dalam Rajah 2. Walau bagaimanapun, set data pengesanan kecacatan sedia ada sering kekurangan ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal Contohnya, jika terdapat kawasan pengelupasan cat yang besar pada permukaan plat logam, walaupun kawasan kecacatan adalah besar, ia akan. tidak mempunyai kesan fungsi pada plat logam Mungkin sangat sedikit. Walau bagaimanapun, jika terdapat retakan kecil di dalam plat logam, walaupun retak ini sekecil rambut, ia boleh menyebabkan plat logam pecah serta-merta apabila ia berada di bawah tekanan, menjejaskan prestasinya dengan ketara, malah menyebabkan bahaya keselamatan yang serius.
- Sebaiknya dikatakan, andaikan gigi zip sehelai pakaian tidak sejajar Walaupun kecacatan ini mungkin tidak kelihatan besar atau mudah dikesan, ia menjejaskan fungsi pakaian dan menyebabkan zip tidak berfungsi dengan baik. Pengguna terpaksa mengembalikannya ke kilang untuk dibaiki. Walau bagaimanapun, jika kecacatan berlaku pada fabrik pakaian, seperti sedikit tersangkut atau sedikit perbezaan warna, saiz dan kesannya perlu ditimbang dengan teliti. Kecacatan fabrik berskala kecil boleh diklasifikasikan dalam had yang boleh diterima, membolehkan produk ini dijual melalui strategi pengedaran yang berbeza, seperti menjual pada harga diskaun, sekali gus mengekalkan produk dalam edaran tanpa menjejaskan standard kualiti keseluruhan.
Di sebalik semua ini, set data "Spektrum Kecacatan" adalah seperti detektif yang maha kuasa dengan wawasan tentang segala-galanya. Ia bukan sahaja merangkumi pelbagai jenis kecacatan industri, tetapi juga menyediakan penerangan terperinci dan kaya untuk setiap kecacatan. Melalui alat berkuasa ini, sistem pengesan kecacatan dapat mengenal pasti dan mengklasifikasikan pelbagai kecacatan dengan lebih tepat tanpa kehilangan sebarang butiran. 想象一下,在实际的生产线上,通过“Defect Spectrum”数据集的帮助,检测系统能够迅速识别出这个至关重要的缺陷,立即标记并返回工厂进行修复。同时,对于那些面料上轻微的缺陷或颜色差异,系统可以根据缺陷的详细标注,判断其是否在可接受范围内,决定是否以打折价格销售。这种灵活的处理方式,不仅提高了产品的质量,还保证了生产的高效和成本的控制。 传统数据集如MVTEC和AeBAD尽管提供了像素级的标注,但常常局限于二元遮罩,无法细致区分缺陷类型和位置。《Defect Spectrum》数据集通过与工业界四大基准的合作,重新评估并精细化已有的缺陷标注。例如,对细微的划痕和凹坑进行了更精确的轮廓绘制,且通过专家的辅助填补了遗漏的缺陷,确保了标注的全面性和精确性。 创新的缺陷生成模型“Defect-Gen” 图三:Defect-Gen两阶段生成流程示意图 面对当前数据集中缺陷样本不足的问题,我们提出了“Defect-Gen”,一个两阶段的扩散式生成器。这个生成器在样本数量有限的情况下,通过两个关键方法提高了图像的多样性和质量:第一,使用Patch级建模;第二,限制感受野。 传统的扩散模型在训练样本少时,容易过拟合,生成的结果缺乏多样性,往往只是记住了训练样本。而我们的模型通过降低数据维度和增加样本量,有效地减少了这种过拟合现象。 为了弥补Patch级建模在表达整个图像结构上的不足,我们提出了两阶段的扩散过程。首先,在早期步骤中使用大感受野模型捕捉几何结构,然后在后续步骤中切换到小感受野模型生成局部Patch。这样做在保持图像质量的同时,显著提升了生成的多样性。通过调整两个模型的接入点和感受野,我们的模型在保真度和多样性之间实现了良好的平衡。 通过“Defect-Gen”,我们为工业缺陷检测提供了更丰富和多样的训练样本,推动了自动化检测技术的发展 全面评估与未来的研究方向 表三:Defect Spectrum数据集上的实际评估标准 我们对Defect Spectrum数据集进行了全面的评估,标注如表三所示。这个实验验证了Defect Spectrum在各种工业缺陷检测挑战中的适用性和优越性。表四表明,比起原有的数据集,在我们数据集上训练的模型提升了10.74%的召回率(recall),降低了33.1%的过杀率(False Positive Rate)。此外,数据集的构建和评估过程不仅提供了一个坚实的研究基础,也为工业界和学术界的研究人员提供了一个评估和开发针对工业缺陷检测复杂需求的先进模型的平台。 Defect Spectrum数据集的引入,犹如为工业生产注入了一剂强心针。它让缺陷检测系统更加贴近实际生产需求,实现了高效、精准的缺陷管理。同时,它也为未来的预测性维护提供了宝贵的数据支持,通过记录每个缺陷的类别和位置,工厂可以不断优化生产流程,改进产品修复方法,最终实现更高的生产效益和产品质量。 总结 我们发布了Defect Spectrum数据集以及DefectGen缺陷生成器,提供了实际工业检测中所需的高精确度和丰富缺陷语义,解决了模型无法识别缺陷类别或位置的问题。 我们对Defect Spectrum数据集进行了全面的评估,验证了其在各种工业缺陷检测挑战中的适用性和优越性,比起原有的数据集,在我们数据集上训练的模型提升了10.74%的召回率(recall),降低了33.1%的过杀率(False Positive Rate)。 参考资料: 1. Bai, H., Mou, S., Likhomanenko, T., Cinbis, R.G., Tuzel, O., Huang, P., Shan, J., Shi, J., Cao, M.:视觉数据集:视觉数据集的基准基于视觉的工业检测。 arXiv 预印本 arXiv:2306.07890 (2023) 2. Silvestre-Blanes, J.、Albero-Albero, T.、Miralles, I.、Pérez-Llorens, R.、Moreno, J.:用于缺陷检测方法和结果的公共织物数据库。 Autex 研究杂志19(4), 363–374 (2019)。 https://doi.org/doi:10.2478/aut-2019-0035,https://doi.org/10.2478/aut-2019-0035 3. 张Z.,赵Z.,张X.,孙C.,陈X.:具有域转移的工业异常检测:真实世界数据集和屏蔽多尺度重建。 arXiv 预印本 arXiv:2304.02216 (2023) 4。 Mishra, P.、Verk, R.、Fornasier, D.、Piciarelli, C.、Foresti, G.L.:VT-ADL:用于图像异常检测和定位的视觉变换器网络。见:第 30 届 IEEE/IES 国际工业电子研讨会 (ISIE)(2021 年 6 月) 5。 Incorporated, C.:标准织物缺陷术语表 (2023),网址:https://www.棉花公司com / 质量 - 产品 / 纺织品 - 资源 / 面料 - 缺陷 - 术语表 6。 Wieler, M., Hahn, T.:工业光学检测的弱监督学习。见:DAGM 研讨会。卷。 6(2007) 7。 Tabernik, D.、Šela, S.、Skvarč, J.、Skočaj, D.:基于分割的深度学习表面缺陷检测方法。智能制造杂志31(3), 759–776 (2020) 8. Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.:Mvtec ad——用于无监督异常检测的综合现实世界数据集。见:IEEE/CVF 计算机视觉和模式识别会议论文集。第 9592–9600 页(2019) 9。 Zou, Y.、Jeong, J.、Pemula, L.、Zhang, D.、Dabeer, O.:用于异常检测和分割的找出差异自监督预训练(2022)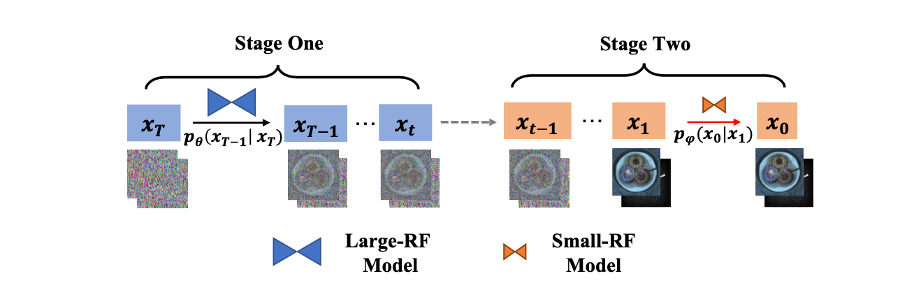
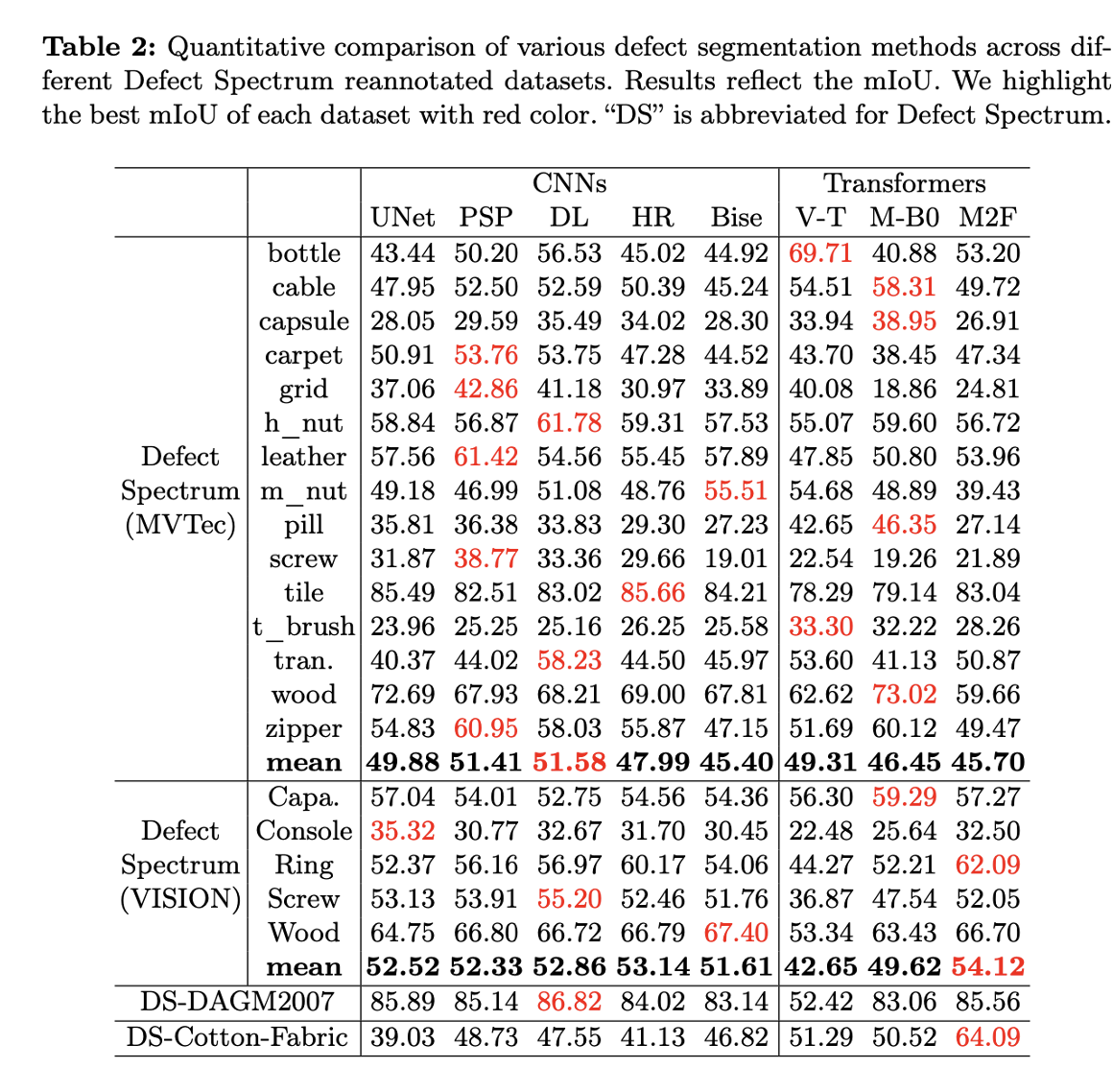 表二:部分缺陷检测网络在Defect Spectrum数据集上的测评结果
表二:部分缺陷检测网络在Defect Spectrum数据集上的测评结果
 表四:Defect Spectrum在实际评估中的优异表现
表四:Defect Spectrum在实际评估中的优异表现
Atas ialah kandungan terperinci Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Teknologi Simou telah membangunkan set data "DefectSpectrum" secara inovatif, yang menyediakan anotasi berskala besar yang kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "DefectSpectrum" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan) dan klasifikasi kecacatan yang paling terperinci (125 kategori kecacatan
 Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model yang cemerlang. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak bidang. Selain model umum, beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, dan InternVL untuk tugasan bahasa visual.
 Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Editor |. ScienceAI Berdasarkan data klinikal yang terhad, beratus-ratus algoritma perubatan telah diluluskan. Para saintis sedang membahaskan siapa yang harus menguji alat dan cara terbaik untuk melakukannya. Devin Singh menyaksikan seorang pesakit kanak-kanak di bilik kecemasan mengalami serangan jantung semasa menunggu rawatan untuk masa yang lama, yang mendorongnya untuk meneroka aplikasi AI untuk memendekkan masa menunggu. Menggunakan data triage daripada bilik kecemasan SickKids, Singh dan rakan sekerja membina satu siri model AI untuk menyediakan potensi diagnosis dan mengesyorkan ujian. Satu kajian menunjukkan bahawa model ini boleh mempercepatkan lawatan doktor sebanyak 22.3%, mempercepatkan pemprosesan keputusan hampir 3 jam bagi setiap pesakit yang memerlukan ujian perubatan. Walau bagaimanapun, kejayaan algoritma kecerdasan buatan dalam penyelidikan hanya mengesahkan perkara ini
 Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Bagi AI, Olimpik Matematik tidak lagi menjadi masalah. Pada hari Khamis, kecerdasan buatan Google DeepMind menyelesaikan satu kejayaan: menggunakan AI untuk menyelesaikan soalan sebenar IMO Olimpik Matematik Antarabangsa tahun ini, dan ia hanya selangkah lagi untuk memenangi pingat emas. Pertandingan IMO yang baru berakhir minggu lalu mempunyai enam soalan melibatkan algebra, kombinatorik, geometri dan teori nombor. Sistem AI hibrid yang dicadangkan oleh Google mendapat empat soalan dengan betul dan memperoleh 28 mata, mencapai tahap pingat perak. Awal bulan ini, profesor UCLA, Terence Tao baru sahaja mempromosikan Olimpik Matematik AI (Anugerah Kemajuan AIMO) dengan hadiah berjuta-juta dolar Tanpa diduga, tahap penyelesaian masalah AI telah meningkat ke tahap ini sebelum Julai. Lakukan soalan secara serentak pada IMO Perkara yang paling sukar untuk dilakukan dengan betul ialah IMO, yang mempunyai sejarah terpanjang, skala terbesar dan paling negatif
 Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Editor |KX Sehingga hari ini, perincian dan ketepatan struktur yang ditentukan oleh kristalografi, daripada logam ringkas kepada protein membran yang besar, tidak dapat ditandingi oleh mana-mana kaedah lain. Walau bagaimanapun, cabaran terbesar, yang dipanggil masalah fasa, kekal mendapatkan maklumat fasa daripada amplitud yang ditentukan secara eksperimen. Penyelidik di Universiti Copenhagen di Denmark telah membangunkan kaedah pembelajaran mendalam yang dipanggil PhAI untuk menyelesaikan masalah fasa kristal Rangkaian saraf pembelajaran mendalam yang dilatih menggunakan berjuta-juta struktur kristal tiruan dan data pembelauan sintetik yang sepadan boleh menghasilkan peta ketumpatan elektron yang tepat. Kajian menunjukkan bahawa kaedah penyelesaian struktur ab initio berasaskan pembelajaran mendalam ini boleh menyelesaikan masalah fasa pada resolusi hanya 2 Angstrom, yang bersamaan dengan hanya 10% hingga 20% daripada data yang tersedia pada resolusi atom, manakala Pengiraan ab initio tradisional
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Mengenal pasti molekul terbaik secara automatik dan mengurangkan kos sintesis MIT membangunkan rangka kerja algoritma pembuatan keputusan reka bentuk molekul
Jun 22, 2024 am 06:43 AM
Mengenal pasti molekul terbaik secara automatik dan mengurangkan kos sintesis MIT membangunkan rangka kerja algoritma pembuatan keputusan reka bentuk molekul
Jun 22, 2024 am 06:43 AM
Editor |. Penggunaan Ziluo AI dalam memperkemas penemuan dadah semakin meletup. Skrin berbilion molekul calon untuk mereka yang mungkin mempunyai sifat yang diperlukan untuk membangunkan ubat baharu. Terdapat begitu banyak pembolehubah untuk dipertimbangkan, daripada harga material kepada risiko kesilapan, sehingga menimbang kos mensintesis molekul calon terbaik bukanlah tugas yang mudah, walaupun saintis menggunakan AI. Di sini, penyelidik MIT membangunkan SPARROW, rangka kerja algoritma membuat keputusan kuantitatif, untuk mengenal pasti calon molekul terbaik secara automatik, dengan itu meminimumkan kos sintesis sambil memaksimumkan kemungkinan calon mempunyai sifat yang diingini. Algoritma juga menentukan bahan dan langkah eksperimen yang diperlukan untuk mensintesis molekul ini. SPARROW mengambil kira kos mensintesis sekumpulan molekul sekaligus, memandangkan berbilang molekul calon selalunya tersedia
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
