


Editor |. ScienceAI
Baru-baru ini, usaha untuk meningkatkan keadilan telah memperkenalkan kaedah dan set data baharu. Walau bagaimanapun, isu keadilan telah diterokai sedikit dalam konteks pemindahan domain, walaupun klinik sering bergantung pada teknologi pengimejan yang berbeza (cth., modaliti pengimejan retina yang berbeza) untuk diagnosis pesakit.
Makalah ini mencadangkan FairDomain, yang merupakan kajian sistematik pertama tentang kesaksamaan algoritma di bawah pemindahan domain Kami menguji algoritma Penyesuaian Domain (DA) dan Generalisasi Domain (DG) yang terkini untuk pembahagian dan pengelasan imej perubatan. tugasan , direka untuk memahami cara bias dipindahkan antara domain yang berbeza.
Kami juga mencadangkan modul Perhatian Identiti Adil (FIA) plug-and-play baharu untuk meningkatkan kesaksamaan pelbagai algoritma DA dan DG dengan menggunakan mekanisme perhatian kendiri untuk melaraskan kepentingan ciri berdasarkan jantina atribut demografi.
Selain itu, kami telah menyusun dan mendedahkan set data anjakan domain pertama yang memfokuskan pada keadilan, yang mengandungi tugasan segmentasi dan pengelasan perubatan dua modaliti pengimejan yang berpasangan bagi populasi pesakit yang sama untuk menilai dengan teliti senario peralihan domain. Mengecualikan kesan mengelirukan perbezaan dalam taburan populasi antara sumber dan domain sasaran akan membolehkan kuantifikasi prestasi model pemindahan domain yang lebih jelas.
Penilaian meluas kami menunjukkan bahawa FIA yang dicadangkan meningkatkan kesaksamaan dan prestasi model dengan ketara di bawah ciri demografi yang berbeza dalam semua tugas pemindahan domain (iaitu, DA dan DG), mengatasi kaedah terkini dalam kedua-dua tugasan segmentasi dan pengelasan adalah satu cara.
Kongsi hasil kerja draf akhir ECCV 2024 di sini "
Domain Adil: Mencapai Kesaksamaan dalam Segmentasi dan Klasifikasi Imej Perubatan Merentas Domain"
 Alamat artikel:
Alamat artikel:
Alamat kod: https://github.com/Harvard-Ophthalmology-AI-Lab/FairDomain
Tapak web set data: https://ophai.hms.harvard.edu/datasets/harvard-fairdomain20k
Pautan muat turun set data:https://drive.google.com/drive/folders/1huH93JVeXMj9rK6p1OZRub868vv0UK0O?usp=sharing
Harvard-Ophthalmology-AI-Lab komited untuk menyediakan set data keadilan yang berkualiti tinggi dan lebih banyak set data keadilan klik pada halaman utama dataset makmal:https://ophai.hms.harvard.edu/datasets/
Latar Belakang
Dalam beberapa tahun kebelakangan ini, kemajuan pembelajaran mendalam dalam bidang pengimejan perubatan telah meningkatkan klasifikasi dan tugas pembahagian Kesan. Teknologi ini membantu meningkatkan ketepatan diagnostik, memudahkan perancangan rawatan dan akhirnya meningkatkan kesihatan pesakit. Walau bagaimanapun, cabaran penting apabila menggunakan model pembelajaran mendalam dalam tetapan perubatan yang berbeza ialah kecenderungan dan diskriminasi yang wujud algoritma terhadap kumpulan demografi tertentu, yang mungkin menjejaskan keadilan diagnosis dan rawatan perubatan.Beberapa penyelidikan baru-baru ini telah mula menyelesaikan masalah bias algoritma dalam pengimejan perubatan dan membangunkan beberapa kaedah untuk meningkatkan kesaksamaan model pembelajaran mendalam. Walau bagaimanapun, kaedah ini biasanya mengandaikan bahawa pengedaran data kekal tidak berubah semasa fasa latihan dan ujian, yang selalunya tidak benar dalam senario perubatan sebenar.
Sebagai contoh, klinik penjagaan primer dan hospital khusus yang berbeza mungkin bergantung pada teknologi pengimejan yang berbeza (cth., modaliti pengimejan retina yang berbeza) untuk diagnosis, mengakibatkan peralihan domain yang ketara, yang seterusnya menjejaskan prestasi dan keadilan model. Oleh itu, dalam penggunaan sebenar, pemindahan domain mesti dipertimbangkan dan model yang boleh mengekalkan keadilan dalam senario merentas domain mesti dipelajari. Walaupun penyesuaian domain dan generalisasi domain telah diterokai secara meluas dalam literatur, kajian ini tertumpu terutamanya pada meningkatkan ketepatan model, mengabaikan kritikal untuk memastikan model memberikan ramalan yang adil merentas kumpulan populasi yang berbeza. Terutamanya dalam bidang perubatan, model membuat keputusan secara langsung mempengaruhi kesihatan dan keselamatan manusia, jadi mengkaji keadilan merentas domain adalah sangat penting. Walau bagaimanapun, hanya beberapa kajian telah mula meneroka isu keadilan merentas domain, dan kajian ini tidak mempunyai penyiasatan yang sistematik dan komprehensif, biasanya hanya memfokuskan pada penyesuaian atau generalisasi domain, tetapi jarang pada kedua-duanya. Di samping itu, penyelidikan sedia ada terutamanya menyelesaikan masalah klasifikasi perubatan, sambil mengabaikan tugas pembahagian perubatan yang sama penting di bawah pemindahan domain. Untuk menyelesaikan masalah ini, kami memperkenalkan FairDomain, yang merupakan kajian pertama dalam bidang pengimejan perubatan untuk meneroka secara sistematik keadilan algoritma di bawah pemindahan domain.Kami menjalankan eksperimen yang meluas dengan berbilang penyesuaian domain terkini dan algoritma generalisasi untuk menilai ketepatan dan kesaksamaannya di bawah atribut demografi yang berbeza dan memahami cara pemindahan keadilan merentas domain yang berbeza.
Pemerhatian kami mendedahkan bahawa perbezaan prestasi kumpulan antara domain sumber dan sasaran diburukkan dengan ketara dalam tugas klasifikasi dan pembahagian perubatan yang berbeza. Ini menunjukkan keperluan untuk mereka bentuk algoritma berorientasikan keadilan untuk menangani isu mendesak ini dengan berkesan.

Untuk mengimbangi kelemahan usaha pengurangan berat sebelah sedia ada, kami memperkenalkan mekanisme Perhatian Identiti Adil (FIA) serba boleh baharu yang direka untuk disepadukan dengan lancar ke dalam pelbagai strategi penyesuaian dan generalisasi domain, kepentingan ciri diselaraskan dengan perhatian diri yang diperolehi daripada atribut demografi (cth., kumpulan kaum) untuk menggalakkan keadilan.
Cabaran utama dalam pembangunan penanda aras FairDomain ialah kekurangan set data pengimejan perubatan yang benar-benar mencerminkan peralihan domain dalam domain perubatan dunia sebenar, yang sering disebabkan oleh teknologi pengimejan yang berbeza.
Dalam set data perubatan sedia ada, perbezaan dalam demografi pesakit antara domain sumber dan sasaran menimbulkan kekeliruan, menjadikannya sukar untuk membezakan sama ada bias algoritma yang diperhatikan adalah disebabkan oleh perubahan pengedaran demografi atau peralihan domain yang wujud.
Untuk menangani isu ini, kami menyusun set data unik yang terdiri daripada imej fundus retina berpasangan bagi kohort pesakit yang sama, menggunakan dua modaliti pengimejan yang berbeza (gambar En face dan SLO fundus), khusus untuk menganalisis senario pemindahan domain bias algoritma.
Ringkasan sumbangan kami:
2. Teknologi perhatian identiti yang adil diperkenalkan untuk meningkatkan ketepatan dan kesaksamaan dalam penyesuaian dan generalisasi domain.
3 Mencipta set data segmentasi dan klasifikasi perubatan berskala besar untuk penyelidikan keadilan, khususnya mengkaji isu keadilan di bawah pemindahan domain.
Pengumpulan Data dan Kawalan Kualiti
Subjek dipilih daripada hospital mata akademik yang besar di Sekolah Perubatan Harvard antara 2010 dan 2021. Dua tugas silang domain diterokai dalam kajian ini, iaitu tugasan segmentasi perubatan dan klasifikasi perubatan. Untuk tugas segmentasi perubatan, data termasuk lima jenis:
;
5. Anotasi topeng cawan dan pinggan.
Secara khusus, anotasi piksel bagi kawasan cawan-cakera pertama kali diperoleh melalui peranti OCT, dan perisian pengeluar OCT membahagikan tepi cakera dalam OCT 3D ke dalam bukaan membran Bruch, dan mengesan tepi cawan sebagai membran pengehad dalaman (ILM). ) bersilang dengan satah Titik persilangan luas permukaan minimum.
Disebabkan kontras tinggi bukaan membran Bruch dan membran had dalaman dengan latar belakang, sempadan ini boleh dibahagikan dengan mudah. Oleh kerana perisian pengilang OCT menggunakan maklumat 3D, pembahagian cawan-cakera secara amnya boleh dipercayai.
Memandangkan ketersediaan terhad dan kos tinggi peralatan OCT dalam penjagaan primer, kami mencadangkan kaedah untuk memindahkan anotasi OCT 3D kepada imej fundus SLO 2D untuk meningkatkan kecekapan saringan glaukoma awal.
Kami menggunakan alat NiftyReg untuk menjajarkan imej fundus SLO dengan tepat dengan anotasi piksel terbitan OCT, menghasilkan sejumlah besar anotasi topeng fundus SLO berkualiti tinggi.
Proses ini telah disahkan oleh pasukan pakar perubatan dengan kadar kejayaan pendaftaran 80%, memperkemas proses anotasi untuk kegunaan yang lebih meluas dalam tetapan penjagaan primer. Kami memanfaatkan anotasi yang diselaraskan dan diperiksa secara manual ini, digabungkan dengan imej fundus muka SLO dan En, untuk mengkaji keadilan algoritma model segmentasi di bawah peralihan domain.
Untuk tugas klasifikasi perubatan, data termasuk empat jenis berikut:
1. Imbasan imej fundus muka
2 .
Dataset segmentasi perubatan mengandungi 10,000 sampel daripada 10,000 subjek. Kami membahagikan data kepada set latihan 8000 sampel dan set ujian 2000 sampel. Purata umur pesakit ialah 60.3 ± 16.5 tahun.
Dataset mengandungi enam atribut demografi termasuk umur, jantina, bangsa, etnik, bahasa pilihan dan status perkahwinan. Taburan demografi adalah seperti berikut:
Jantina: 58.5% perempuan, 41.5% lelaki; Kaum: 9.2% Asia, 14.7% hitam, 76.1% putih
Etnik: 90.6% bukan Hispanik; , tidak diketahui menyumbang 5.7%; %, bujang 27.1%, bercerai 6.8%, berpisah secara sah 0.8%, balu 5.2%, tidak diketahui 2.4%.
Begitu juga, set data klasifikasi perubatan mengandungi 10,000 sampel 10,000 subjek dengan purata umur 60.9 ± 16.1 tahun. Kami membahagikan data kepada set latihan 8000 sampel dan set ujian 2000 sampel. Taburan demografi adalah seperti berikut:
Kaum: 8.7% Asia, 14.5% hitam, 76.8% putih; ;
Bahasa pilihan: 92.6% Inggeris, 1.7% Sepanyol, 3.6% bahasa lain, 2.1% tidak diketahui;
Status perkahwinan: 58.5% berkahwin atau berpasangan, 26.1% bujang, 6.9% bercerai, Perpisahan sah menyumbang 0.8% 1.9%, dan tidak diketahui menyumbang 5.8%.
Maklumat demografi terperinci ini menyediakan asas data yang kaya untuk penyelidikan mendalam tentang keadilan dalam tugas merentas domain.
Kaedah yang digunakan untuk meningkatkan kesaksamaan model AI merentas domain Perhatian Identiti Adil (FIA)

Takrifan masalah
Penyesuaian Domain (DA) dan Teknik Pengitlak Domain (DG) Ia adalah Generalisasi Domain pembangunan model pembelajaran mesin dan direka bentuk untuk mengatasi kebolehubahan yang mungkin timbul apabila model digunakan dari satu domain tertentu ke domain yang lain.
Dalam bidang pengimejan perubatan, teknik DA dan DG adalah penting untuk mencipta model yang boleh mengendalikan kebolehubahan antara institusi perubatan yang berbeza, peranti pengimejan dan populasi pesakit. Kertas kerja ini bertujuan untuk meneroka dinamik keadilan dalam konteks pemindahan domain dan membangunkan kaedah untuk memastikan model kekal adil dan boleh dipercayai apabila menyesuaikan atau menggeneralisasikan kepada domain baharu.
Kami berhasrat untuk membangunkan fungsi kaedah f yang mengurangkan kemerosotan kesaksamaan biasa apabila model dipindahkan daripada domain sumber ke domain sasaran. Keterukan seperti itu terutamanya disebabkan oleh potensi peralihan domain untuk menguatkan bias sedia ada dalam set data, terutamanya yang berkaitan dengan atribut demografi seperti jantina, bangsa atau etnik.
Untuk menangani masalah ini, kami mencadangkan pendekatan berasaskan mekanisme perhatian yang bertujuan untuk mengenal pasti dan mengeksploitasi ciri imej yang berkaitan dengan tugas hiliran seperti pembahagian dan pengelasan sambil mengambil kira atribut demografi.
Rajah 3 menunjukkan seni bina modul perhatian identiti adil yang dicadangkan. Modul ini mula-mula mendapatkan pemasukan imej input E_i dan pembenaman atribut E_a dengan memproses imej input dan label atribut statistik input. Pembenaman ini kemudiannya ditambah pada pembenaman kedudukan E_p. Formula pengiraan terperinci adalah seperti berikut:
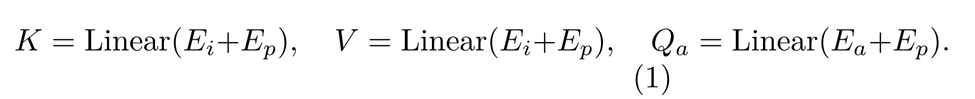
Dengan mengira hasil darab titik pertanyaan dan kunci, kami mengekstrak matriks persamaan yang berkaitan dengan atribut ciri semasa. Hasil darab titik matriks dan nilai ini kemudiannya digunakan untuk mengekstrak ciri yang penting dalam tugasan hiliran untuk setiap atribut ciri. Proses ini diwakili oleh formula berikut:

di mana D ialah faktor penskalaan untuk mengelakkan nilai yang terlalu besar dalam fungsi softmax.
Seterusnya, sambungan baki menambah E_i pada output perhatian untuk mengekalkan integriti maklumat input. Akhir sekali, lapisan normalisasi dan lapisan perceptron berbilang lapisan (MLP) mengekstrak ciri selanjutnya. Selepas operasi baki lain pada output kedua-dua lapisan ini, kami mendapat output akhir modul perhatian saksama.
Mekanisme Perhatian Identiti Adil ialah alat yang berkuasa dan serba boleh yang direka untuk meningkatkan prestasi model sambil menyelesaikan isu keadilan. Dengan mengambil kira secara eksplisit atribut demografi seperti jantina, bangsa atau etnik, ia memastikan bahawa perwakilan yang dipelajari tidak secara tidak sengaja menguatkan bias yang terdapat dalam data.
Seni binanya membolehkan ia disepadukan dengan lancar ke dalam mana-mana rangkaian sedia ada sebagai komponen pemalam. Sifat modular ini membolehkan penyelidik dan pengamal menyepadukan perhatian identiti yang adil ke dalam model mereka tanpa memerlukan pengubahsuaian yang meluas pada seni bina asas.
Oleh itu, modul perhatian identiti adil bukan sahaja membantu meningkatkan ketepatan dan keadilan model dalam tugasan pembahagian dan pengelasan, tetapi juga menggalakkan pelaksanaan AI yang boleh dipercayai dengan mempromosikan layanan adil terhadap kumpulan berbeza dalam set data. . Segmentasi cawan ke cakera merujuk kepada proses penggarisan tepat cawan optik dan cakera dalam imej fundus, yang penting untuk mengira nisbah cawan kepada cakera (CDR), parameter utama dalam menilai perkembangan dan risiko glaukoma.
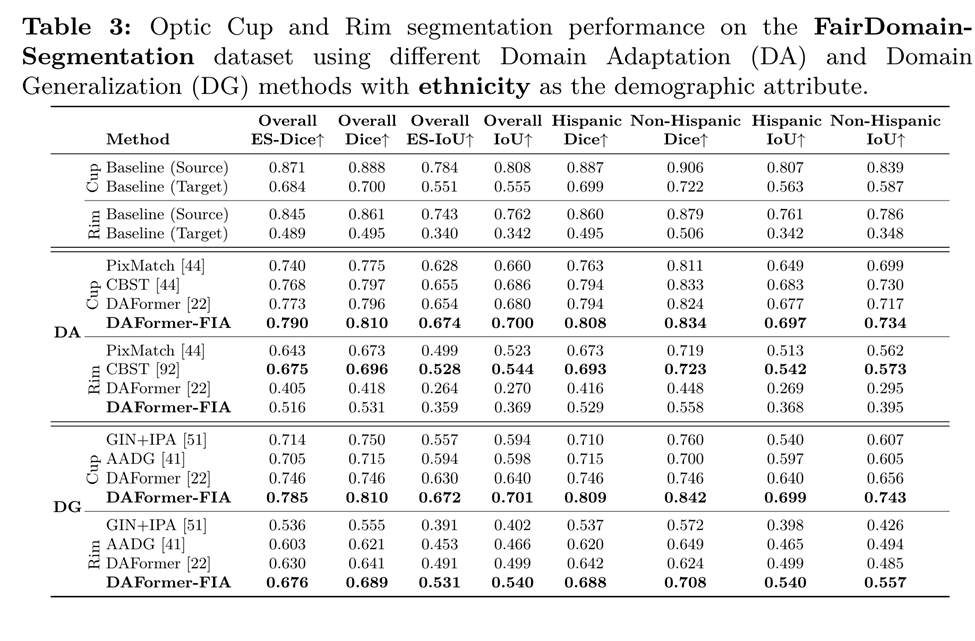
Tugas ini amat penting dalam bidang pengimejan perubatan, terutamanya semasa mendiagnosis dan menguruskan penyakit mata seperti glaukoma. Memandangkan cawan optik ialah subkawasan penting bagi cakera optik, kami merangka semula tugas pembahagian sebagai pembahagian cawan dan rim (kawasan tisu antara cawan optik dan rim cakera optik) untuk mengelakkan ralat disebabkan pertindihan besar antara cawan optik dan cakera optik Mengakibatkan herotan prestasi. Kami mengkaji prestasi kesaksamaan merentas tiga demografi berbeza (jantina, bangsa dan etnik) dalam dua bidang berbeza: Imej fundus en face yang diperoleh daripada tomografi koheren optik (OCT) dan Imej fundus laser mengimbas (SLO).
따라서 우리는 En 얼굴 안저 이미지를 소스 도메인으로 사용하고 SLO 안저 이미지를 대상 도메인으로 사용하기로 결정했습니다. 분류 작업을 위해 우리는 이 두 영역의 안저 이미지를 소스 및 대상 영역으로 사용하고 정상 및 녹내장이라는 두 가지 범주로 분류합니다.
평가 지표
Dice 및 IoU 지표를 사용하여 세분화 성능을 평가하고 AUC를 사용하여 분류 작업 성능을 평가합니다. 이러한 전통적인 세분화 및 분류 측정항목은 모델 성능을 반영하지만 본질적으로 인구통계학적 그룹 전체의 공정성을 설명하지 않습니다.
의료 영상에서 모델 성능과 공정성 간의 잠재적인 균형을 해결하기 위해 새로운 ESP(Equity Scaled Performance) 측정항목을 사용하여 세분화 및 분류 작업의 성능과 공정성을 평가합니다.
{Dice,IoU,AUC,...}M in {Dice,IoU,AUC, .}M∈{Dice,IoU,AUC,...}는 분할 또는 분류 지수에 적합한 일반 성능을 나타냅니다. . 기존 평가에서는 인구통계학적 신원 속성을 무시하는 경우가 많아 중요한 공정성 평가가 누락됩니다. 공정성을 통합하기 위해 먼저 전체 성과에서 각 인구통계 그룹의 지표의 집합적 편차로 정의되는 성과 차이 Δ를 계산합니다. 이는 다음과 같이 공식화됩니다.

그룹 간 성과 공정성이 달성되면 Δ는 0에 가깝습니다. , 가장 작은 차이를 반영합니다. 그런 다음 ESP 메트릭은 다음과 같이 공식화될 수 있습니다.
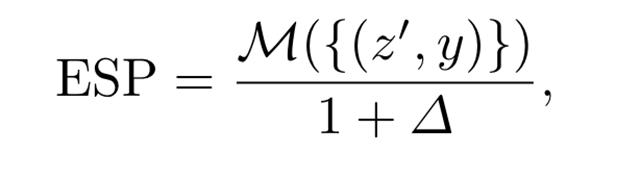
이 통합 메트릭은 딥 러닝 모델을 종합적으로 평가하는 데 도움이 되며 정확성(예: Dice, IoU 및 AUC와 같은 측정을 통해)에 중점을 둘 뿐만 아니라 또한 인구 그룹 간의 서로 다른 형평성에서의 성과에 대해서도 설명합니다.
도메인 이동에 따른 컵림 분할 결과


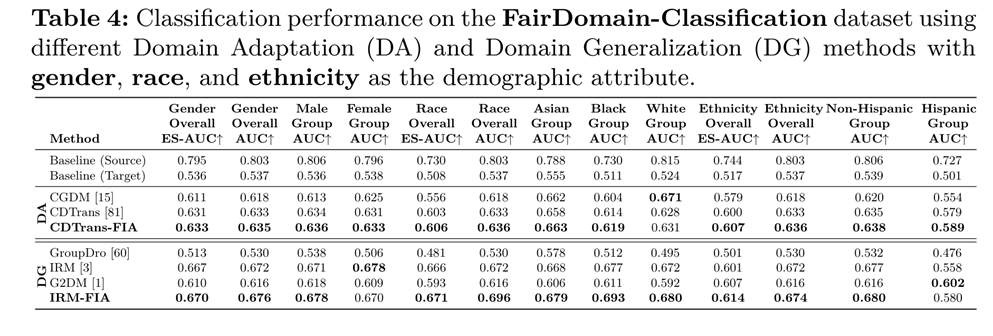
도메인 이동에 따른 녹내장 분류 결과
요약
이 글은 인공지능(특히 의료 AI의 공정성 문제)는 공평한 의료를 달성하는 데 핵심입니다.
클리닉에서는 다양한 이미징 기술을 사용할 수 있으므로 도메인 이전의 공정성 문제는 아직 해결되지 않은 상태로 남아 있습니다. 우리의 작업은 의료 분할 및 분류라는 두 가지 공통 작업을 포함하는 도메인 적응 및 일반화를 포함한 도메인 이전 작업의 알고리즘 공정성에 대한 포괄적인 연구인 FairDomain을 소개합니다.
우리는 도메인 이전 작업의 공정성을 높이기 위해 주의 메커니즘을 통해 인구통계학적 속성을 기반으로 특징 상관관계를 학습하는 새로운 플러그 앤 플레이 FIA(Fair Identity Attention) 모듈을 제안합니다.
또한 모델 공정성에 대한 인구통계학적 분포 변화의 교란 효과를 배제하기 위해 동일한 환자 코호트의 두 쌍의 이미징 이미지가 포함된 최초의 공정성 중심 교차 도메인 데이터 세트를 생성하여 도메인 이전이 모델 공정성에 미치는 영향을 정확하게 평가할 수 있습니다.
우리의 공정한 ID 관심 모델은 기존 도메인 적응 및 일반화 방법을 개선하여 공정성을 염두에 두고 모델 성능을 향상시킬 수 있습니다.
참고: 표지 이미지는 AI에 의해 생성됩니다.
Atas ialah kandungan terperinci ECCV2024 |. Pasukan Harvard membangunkan FairDomain untuk mencapai keadilan dalam pembahagian dan pengelasan imej perubatan merentas domain. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



