
 Peranti teknologi
AI
Selepas 'kecerdasan ruang' Li Feifei, Universiti Jiao Tong Shanghai, Universiti Zhiyuan, Universiti Peking, dll. mencadangkan model spatial besar SpatialBot
Peranti teknologi
AI
Selepas 'kecerdasan ruang' Li Feifei, Universiti Jiao Tong Shanghai, Universiti Zhiyuan, Universiti Peking, dll. mencadangkan model spatial besar SpatialBot
Selepas 'kecerdasan ruang' Li Feifei, Universiti Jiao Tong Shanghai, Universiti Zhiyuan, Universiti Peking, dll. mencadangkan model spatial besar SpatialBot


Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

paper Tajuk: Spatialbot: Pemahaman kedalaman yang tepat dengan model bahasa penglihatan Link: https://arxiv.org/abs/2406.13642 project Homepage: https: // github. com/BAAI-DCAI/SpatialBot
Spatialbot demo adegan yang terkandung: 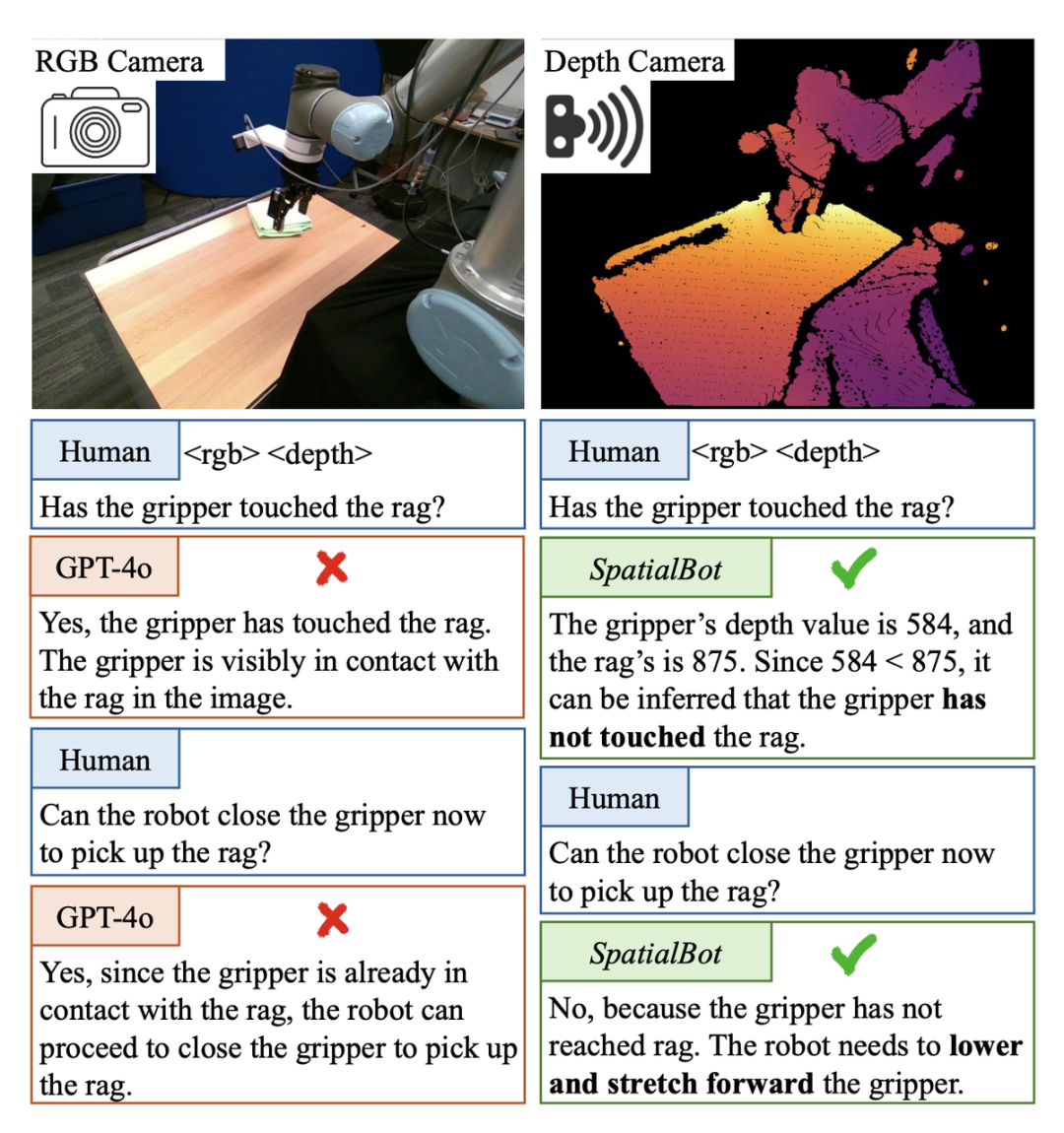
 Awan titik agak mahal, dan kamera binokular memerlukan penentukuran yang kerap semasa digunakan. Sebaliknya, kamera kedalaman adalah berpatutan dan digunakan secara meluas. Dalam senario umum, walaupun tanpa peralatan perkakasan sedemikian, model anggaran kedalaman latihan berskala besar tanpa pengawasan sudah boleh memberikan maklumat kedalaman yang agak tepat. Oleh itu, penulis mencadangkan untuk menggunakan RGBD sebagai input kepada model ruang yang besar.
Awan titik agak mahal, dan kamera binokular memerlukan penentukuran yang kerap semasa digunakan. Sebaliknya, kamera kedalaman adalah berpatutan dan digunakan secara meluas. Dalam senario umum, walaupun tanpa peralatan perkakasan sedemikian, model anggaran kedalaman latihan berskala besar tanpa pengawasan sudah boleh memberikan maklumat kedalaman yang agak tepat. Oleh itu, penulis mencadangkan untuk menggunakan RGBD sebagai input kepada model ruang yang besar. 
- Di peringkat tengah, biarkan model sejajar dengan RGB. ;
- Reka bentuk kedalaman berbilang dalam tahap tinggi Untuk tugasan yang berkaitan, 50k data dianotasi, membolehkan model menggunakan maklumat kedalaman untuk menyelesaikan tugas berdasarkan pemahaman peta kedalaman. Tugas merangkumi: hubungan kedudukan spatial, saiz objek, sama ada objek bersentuhan, pemahaman adegan robot, dsb.
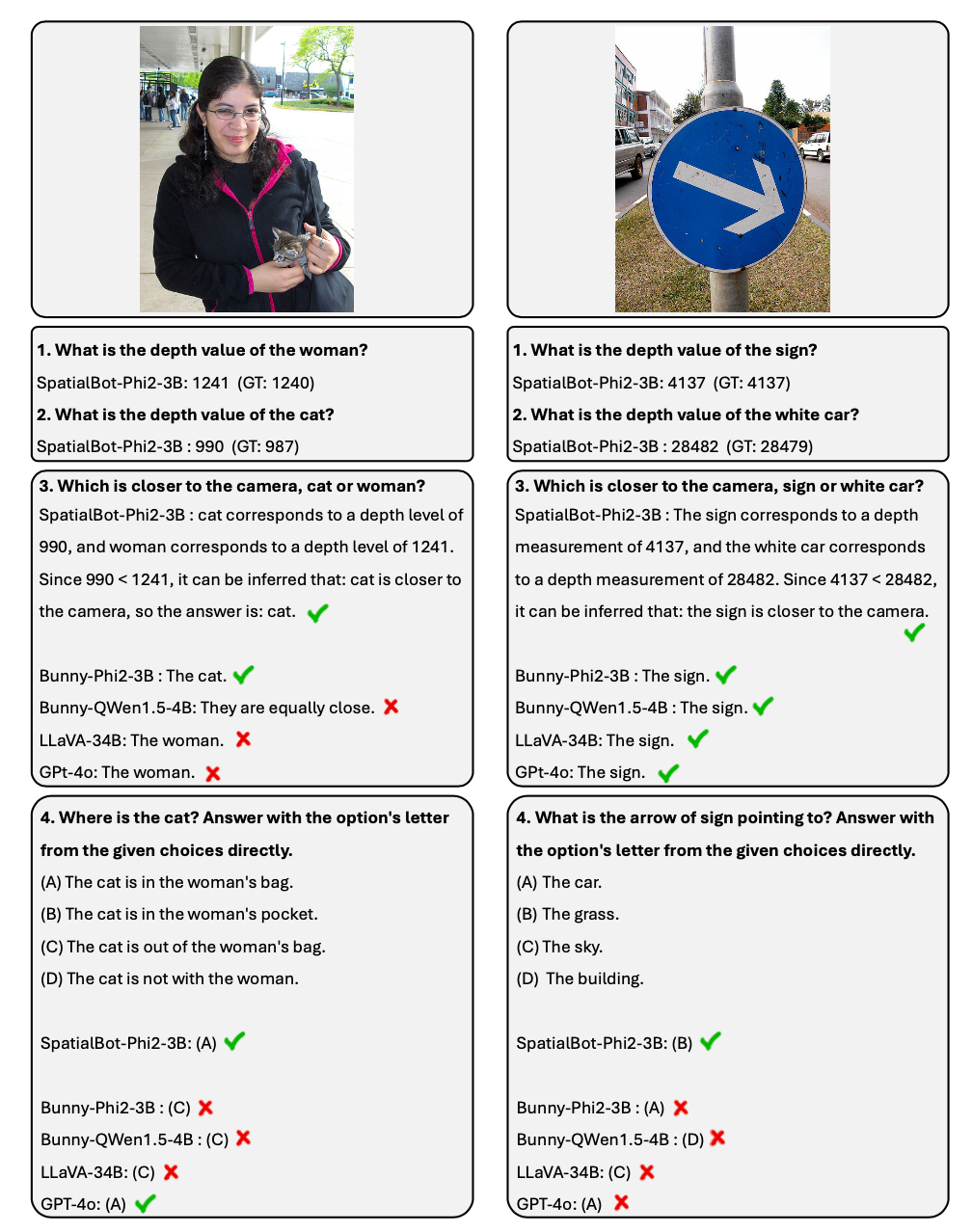
dalam.
2 SpatialBot juga menunjukkan hasil yang menakjubkan pada tugas tertentu seperti Open X-Embodiment dan data merangkak robot yang dikumpul oleh pengarang. 
데이터 표시 방법은 무엇입니까?
- 공간 관계 이해 및 추론
- 로봇 장면 이해: Open X-Embodiment의 장면, 포함된 개체 및 가능한 작업과 이 기사에서 수집된 로봇 데이터를 설명하고 개체 및 경계 상자에 수동으로 레이블을 지정합니다. 로봇의. ㅋㅋ 열기 GPT를 사용하여 데이터의 이 부분에 주석을 추가할 때 GPT는 먼저 깊이 맵을 보고 깊이 맵에 포함될 수 있는 장면과 객체에 대한 이유를 설명합니다. 그런 다음 RGB 맵을 보고 올바른 설명과 추론을 필터링합니다. .
Atas ialah kandungan terperinci Selepas 'kecerdasan ruang' Li Feifei, Universiti Jiao Tong Shanghai, Universiti Zhiyuan, Universiti Peking, dll. mencadangkan model spatial besar SpatialBot. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
 Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
 Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
 Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
 Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
 Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
 Model UI besar pertama di China dikeluarkan! Model besar Motiff mencipta pembantu terbaik untuk pereka bentuk dan mengoptimumkan aliran kerja reka bentuk UI
Aug 19, 2024 pm 04:48 PM
Model UI besar pertama di China dikeluarkan! Model besar Motiff mencipta pembantu terbaik untuk pereka bentuk dan mengoptimumkan aliran kerja reka bentuk UI
Aug 19, 2024 pm 04:48 PM
Model UI besar pertama di China dikeluarkan! Model besar Motiff mencipta pembantu terbaik untuk pereka bentuk dan mengoptimumkan aliran kerja reka bentuk UI
