



Atas dasar ini, NetEase Fuxi terus berinovasi berdasarkan model besar pemahaman imej dan teks, dan mencadangkan kaedah capaian silang modal berdasarkan pemilihan dan pembinaan semula maklumat tempatan utama untuk menyelesaikan masalah teks imej dalam bidang tertentu untuk ejen multi-modal isu-isu Interaksi meletakkan asas teknikal.
Berikut ialah ringkasan kertas yang dipilih:
"Pemilihan dan Pembinaan Semula Penduduk Utama: Kaedah Pengambilan Imej-Teks Domain Khusus Novel"
Pemilihan dan Pembinaan Semula Maklumat Tempatan Utama: Pengambilan Imej dan Teks Domain Khusus Novel Kaedah
Kata kunci: maklumat tempatan utama, terperinci, boleh ditafsir
Bidang yang terlibat: pra-latihan bahasa visual (VLP), imej rentas mod dan perolehan teks (CMITR)
Dalam beberapa tahun kebelakangan ini, dengan pra-latihan bahasa visual latihan (Vision- Dengan peningkatan model Language Pretraining (VLP), kemajuan ketara telah dicapai dalam bidang Cross-Modal Image-Text Retrieval (CMITR). Walaupun model VLP seperti CLIP berprestasi baik dalam tugas CMITR umum domain, prestasinya sering kali gagal dalam Pengambilan Teks Imej Domain Khusus (SDITR). Ini kerana domain khusus selalunya mempunyai ciri data unik yang membezakannya daripada domain umum.
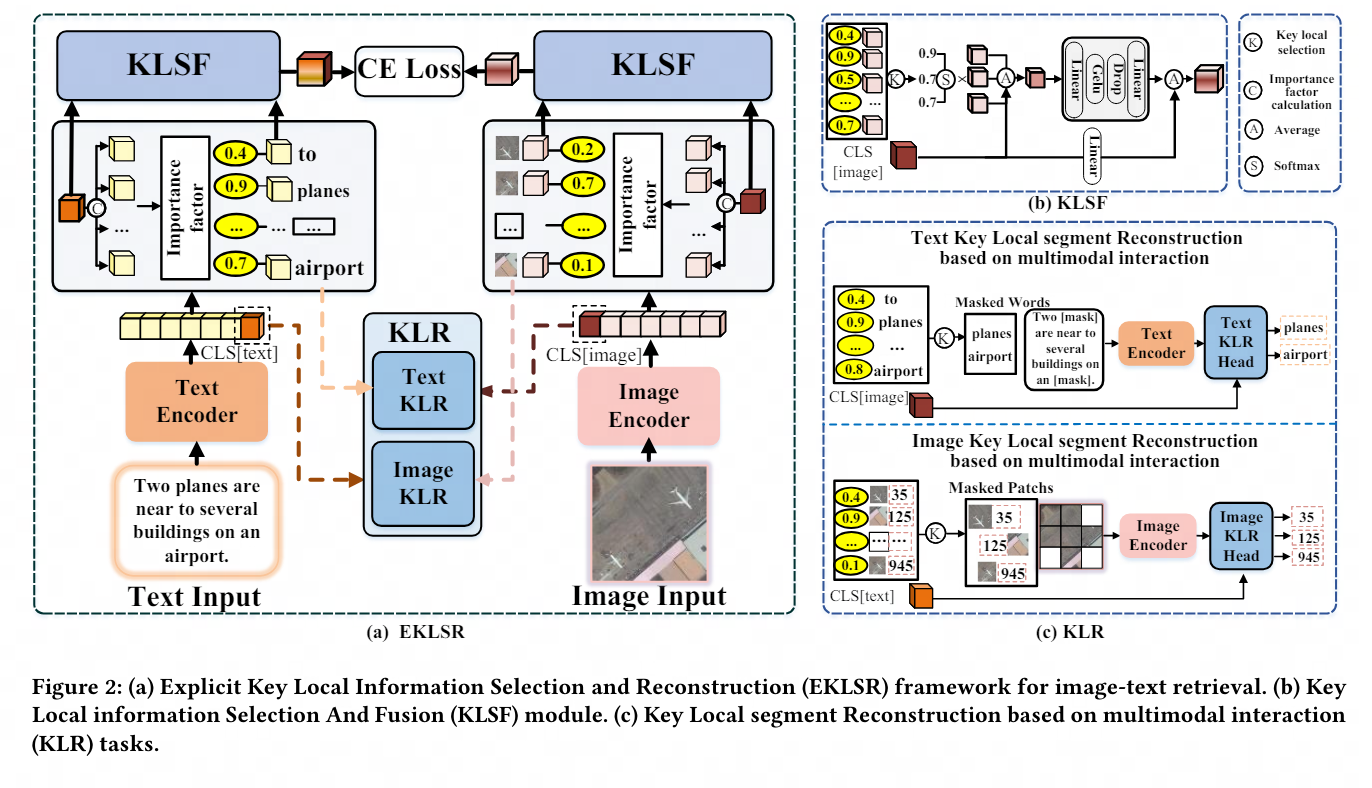
Dalam domain tertentu, imej mungkin mempamerkan tahap persamaan visual yang tinggi antara mereka, manakala perbezaan semantik cenderung menumpukan pada butiran tempatan utama, seperti kawasan objek tertentu dalam imej atau perkataan yang bermakna dalam teks. Malah perubahan kecil dalam segmen tempatan ini boleh memberi impak yang besar pada keseluruhan kandungan, menonjolkan kepentingan maklumat tempatan yang kritikal ini. Oleh itu, SDITR memerlukan model untuk memfokuskan pada serpihan maklumat tempatan utama untuk meningkatkan ekspresi imej dan ciri teks dalam ruang perwakilan dikongsi, dengan itu meningkatkan ketepatan penjajaran antara imej dan teks.
Topik ini meneroka aplikasi model pra-latihan bahasa visual dalam tugas mendapatkan semula teks imej dalam bidang tertentu, dan mengkaji isu penggunaan ciri tempatan dalam tugas mendapatkan semula teks imej dalam bidang tertentu. Sumbangan utama adalah untuk mencadangkan kaedah untuk mengeksploitasi maklumat tempatan yang diskriminatif untuk mengoptimumkan penjajaran imej dan teks dalam ruang perwakilan yang dikongsi.
Untuk tujuan ini, kami mereka bentuk rangka kerja pemilihan dan pembinaan semula maklumat tempatan utama yang eksplisit dan strategi pembinaan semula segmen tempatan yang utama berdasarkan interaksi pelbagai mod Kaedah ini menggunakan maklumat tempatan yang diskriminatif secara berkesan, dengan itu meningkatkan imej dan meluas dan mencukupi dengan ketara. eksperimen tentang kualiti penjajaran teks dalam ruang kongsi menunjukkan kemajuan dan keberkesanan strategi yang dicadangkan.
Terima kasih kepada Makmal IPIU Universiti Sains dan Teknologi Elektronik Xi'an atas sokongan padu dan sumbangan penyelidikan yang penting kepada kertas kerja ini.

Atas ialah kandungan terperinci Penyelidikan multimodal ACM MM2024 |. NetEase Fuxi mendapat pengiktirafan antarabangsa sekali lagi, mempromosikan penemuan baharu dalam pemahaman merentas mod dalam bidang tertentu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 apa itu adobe flash player
apa itu adobe flash player
 Apakah had pemindahan Alipay?
Apakah had pemindahan Alipay?
 nilai mutlak python
nilai mutlak python
 Bagaimana untuk melaraskan sensitiviti tetikus
Bagaimana untuk melaraskan sensitiviti tetikus
 Penyelesaian kepada memori pelayan hos awan yang tidak mencukupi
Penyelesaian kepada memori pelayan hos awan yang tidak mencukupi
 Bagaimana untuk menyelesaikan ralat ralat pertanyaan mysql
Bagaimana untuk menyelesaikan ralat ralat pertanyaan mysql








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



