Pakar hibrid juga mempunyai pengkhususan dalam bidang pembedahan.
Untuk model asas mod campuran semasa, reka bentuk seni bina yang biasa adalah untuk menggabungkan pengekod atau penyahkod bagi modaliti tertentu, tetapi kaedah ini mempunyai had: ia tidak boleh menyepadukan maklumat daripada modaliti yang berbeza, dan ia sukar kepada output. Mengandungi kandungan dalam pelbagai modaliti. Untuk mengatasi had ini, pasukan Chameleon Meta FAIR mencadangkan seni bina Transformer tunggal baharu dalam karya terbaru "Chameleon: Model asas gabungan awal mod campuran", yang boleh berdasarkan token seterusnya. Matlamat ramalan adalah untuk memodelkan jujukan mod bercampur yang terdiri daripada imej diskret dan token teks, membolehkan inferens dan penjanaan yang lancar antara modaliti yang berbeza. 
Selepas melengkapkan pra-latihan mengenai kira-kira 10 trilion token modal campuran, Chameleon telah menunjukkan pelbagai keupayaan visual dan bahasa serta boleh mengendalikan pelbagai tugas hiliran yang berbeza dengan baik. Prestasi Chameleon sangat mengagumkan dalam tugas menjana jawapan panjang bercampur-campur Ia malah mengalahkan model komersial seperti Gemini 1.0 Pro dan GPT-4V. Walau bagaimanapun, untuk model seperti Chameleon di mana pelbagai modaliti dicampur pada peringkat awal latihan model, mengembangkan keupayaannya memerlukan pelaburan banyak kuasa pengkomputeran. Berdasarkan masalah di atas, pasukan Meta FAIR menjalankan beberapa penyelidikan dan penerokaan mengenai seni bina jarang yang dihalakan dan mencadangkan MoMa: Seni bina hibrid pakar yang menyedari Modaliti.
- 論文タイトル: MoMa: Mixture of Modality-Aware Expertsによる効率的な初期融合事前トレーニング
- 論文アドレス: https://arxiv.org/pdf/2407.21770
これまでの研究は、このタイプのアーキテクチャがシングルモーダル基本モデルの機能を効果的に拡張し、マルチモーダル対照学習モデルのパフォーマンスを向上できることを示しました。ただし、さまざまなモダリティを統合した初期モデルのトレーニングにこれを使用することは、依然として機会と課題の両方を伴うトピックであり、研究している人はほとんどいません。 チームの研究は、さまざまなモダリティは本質的に異種であるという洞察に基づいています。テキストと画像のトークンは異なる情報密度と冗長パターンを持っています。 これらのトークンを統合融合アーキテクチャに統合する一方で、チームは、特定のモダリティ用のモジュールを統合することでフレームワークをさらに最適化することも提案しました。チームは、この概念をモダリティ認識スパース性 (略して MaS) と呼びます。これにより、モデルは部分的なパラメーター共有とアテンション メカニズムを使用して、強力なクロスモーダル統合パフォーマンスを維持できます。 VLMo、BEiT-3、VL-MoE などのこれまでの研究では、視覚言語エンコーダーとマスク言語構築モデルをトレーニングするために混合モダリティ エキスパート (MoME/mixture-of-modality-experts) 手法が採用されてきました。 FAIR の研究チームは、MoE の利用可能な範囲をさらに一歩進めました。 この記事で提案される新しいモデルは、画像とテキストを統一的に1つに表現するChameleonの初期融合アーキテクチャに基づいています。トランスフォーマー 一連の個別のトークン。 Chameleon の核心は、画像とテキストのトークンを組み合わせたシーケンスにセルフ アテンション メカニズムを適用する Transformer ベースのモデルです。これにより、モデルはモダリティ内およびモダリティ間の複雑な相関関係を捉えることができます。モデルは、次のトークンを予測することを目的としてトレーニングされ、自己回帰的にテキストと画像のトークンを生成します。 Chameleon では、画像のトークン化スキームは学習画像トークナイザーを使用し、サイズ 8192 のコードブックに基づいて 512 × 512 の画像を 1024 個の個別のトークンにエンコードします。テキストのセグメンテーションには、画像トークンを含む語彙サイズ 65,536 の BPE トークナイザーが使用されます。この統合された単語セグメンテーション手法により、モデルは絡み合った画像とテキストのトークンのあらゆるシーケンスをシームレスに処理できます。 この方法により、新しいモデルは、統一表現、優れた柔軟性、高いスケーラビリティ、およびエンドツーエンド学習のサポートという利点を継承します。 これに基づいて (図 1a)、初期融合モデルの効率とパフォーマンスをさらに向上させるために、チームはモダリティを意識したスパース技術も導入しました。 幅スケーリング:モダリティを意識したハイブリッドエキスパートチームは、幅スケーリング方法を提案しています:モダリティを意識したモジュールのスパース性をフォワードモジュールに統合し、それによって標準ハイブリッドエキスパート(MoE)アーキテクチャをスケーリングします。 。 この方法は、異なるモードのトークンには異なる特性と情報密度があるという洞察に基づいています。 モダリティごとに異なる専門家グループを構築することにより、モデルは、クロスモーダル情報統合機能を維持しながら、特殊な処理パスを開発できます。 図 1b は、このモダリティを意識した専門家の混合 (MoMa) の主要なコンポーネントを示しています。簡単に言うと、まず特定のモダリティごとの専門家がグループ化され、次に階層型ルーティングが実装され(モダリティを意識したルーティングとモーダル内ルーティングに分けられます)、最後に専門家が選択されます。詳細なプロセスについては元の論文を参照してください。 一般に、入力トークン x の場合、MoMa モジュールの正式な定義は次のとおりです: 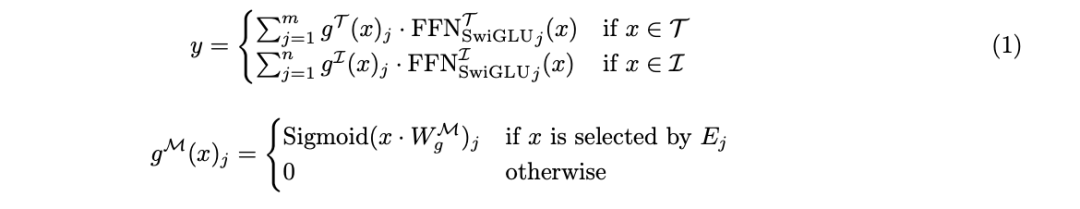
MoMa の計算後、チームはさらに残留接続と Swin Transformer の正規化を使用しました。 以前の研究者は、特定の層をランダムに破棄するか、利用可能な学習ルーターを使用するというアプローチで深度次元にスパース性を導入することも検討していました。 。 具体的には、以下の図に示すように、チームのアプローチは、ハイブリッド エキスパート (MoE) ルーティングの前に各 MoD レイヤーで MoD を統合し、それによってデータのバッチ全体が確実に MoD を使用できるようにすることです。 推論フェーズでは、top-k (上位 k の選択) がデータのバッチで実行されるため、MoE のエキスパート選択ルーティングや MoD のレイヤー選択ルーティングを直接使用することはできません。 ) 選択は因果関係を破壊します。 推論の因果関係を確実にするために、研究チームは、上記の国防省の論文に触発されて、トークンが特定の者によって選択されることを予測する役割を持つ補助ルーター(補助ルーター)を導入しました。トークンの可能性の隠された表現のみに基づくエキスパートまたはレイヤー。 表現空間とルーティングメカニズムの最適化という点で、ゼロからトレーニングされた MoE アーキテクチャには特有の困難があります。チームは、MoE ルーターが各専門家の表現スペースを分割する役割を担っていることを発見しました。ただし、モデル トレーニングの初期段階では、この表現空間は最適ではないため、トレーニングによって得られるルーティング関数が最適ではなくなります。 この制限を克服するために、彼らは小松崎らの論文「Sparse upcycling: Training mix-of-experts fromdensense Checkpoints」に基づいたアップグレード方法を提案しました。 
具体的には、まずモダリティごとに 1 人の FFN エキスパートを使用してアーキテクチャをトレーニングします。いくつかの事前設定されたステップの後、モデルはアップグレードされ、変換されます。具体的な方法は、各特定のモダリティの FFN を専門家が選択した MoE モジュールに変換し、各エキスパートをトレーニングの第 1 段階に初期化することです。これにより、前のステージのデータ ローダーの状態を保持しながら学習率スケジューラがリセットされ、更新されたデータがトレーニングの第 2 ステージで使用できるようになります。 エキスパートの専門化を促進するために、チームはガンベル ノイズを使用して MoE ルーティング機能を強化し、新しいルーターが微分可能な方法でエキスパートをサンプリングできるようにしました。 このアップグレード方法と Gumbel-Sigmoid テクノロジーを組み合わせることで、学習済みルーターの制限を克服でき、それによって新しく提案されたモダリティ認識スパース アーキテクチャのパフォーマンスが向上します。 MoMa の分散トレーニングを促進するために、チームは完全シャーディング データ並列 (FSDP/完全シャーディング データ並列) を採用しました。ただし、従来の MoE と比較すると、この方法には負荷分散の問題やエキスパート実行の効率の問題など、効率に関する特有の課題がいくつかあります。 負荷分散の問題について、チームは、各 GPU でのテキストと画像のデータ比率をエキスパート比率と一致させるバランスのとれたデータ混合方法を開発しました。 エキスパート実行の効率に関して、チームは、さまざまなモダリティでのエキスパートの実行効率を向上させるのに役立ついくつかの戦略を検討しました:
- 各モダリティのエキスパートを同種のエキスパートに制限し、次のことを禁止します。テキスト トークンを画像エキスパートにルーティングする、またはその逆。
- ブロック スパース性を使用して実行効率を向上させます。
- モダリティの数が制限されている場合は、シーケンス エキスパートで異なるモダリティを実行します。
実験の各 GPU は十分なトークンを処理したため、複数のバッチ行列乗算が使用された場合でも、ハードウェア使用率は大きな問題になりません。したがって、チームは、現在の規模の実験環境では逐次実行方法がより良い選択であると考えています。 スループットをさらに向上させるために、チームは他の最適化手法も採用しました。 これには、勾配通信量の削減や自動 GPU コア融合などの一般的な最適化操作も含まれます。研究チームは、torch.compile を介してグラフの最適化も実装しました。 さらに、CPU と GPU 間でデバイスを最も効率的に同期するために、さまざまなレイヤー間でモーダル トークン インデックスを再利用するなど、MoMa 用のいくつかの最適化手法を開発しました。 実験で使用される事前学習データセットと前処理プロセスはChameleonと同じです。スケーリングのパフォーマンスを評価するために、1 兆を超えるトークンを使用してモデルをトレーニングしました。 表 1 に、密モデルと疎モデルの詳細な構成を示します。 さまざまなコンピューティングレベルでのスケーリングパフォーマンスチームは、さまざまなコンピューティングレベルでのさまざまなモデルのスケーリングパフォーマンスを分析しました。これらのコンピューティングレベル (FLOP) は、90M、435M の 3 つのサイズの高密度モデルに相当します。そして1.4B。 実験結果は、疎モデルが合計 FLOP の 1/η のみを使用して、同等の FLOP を持つ密モデルの事前トレーニング損失と一致できることを示しています (η は事前トレーニング加速係数を表します)。 モダリティ固有のエキスパートグループ化を導入すると、さまざまなサイズのモデルの事前トレーニング効率を向上させることができ、これは画像モダリティにとって特に有益です。図 3 に示すように、1 つの画像エキスパートと 1 つのテキスト エキスパートを使用する moe_1t1i 構成は、対応する高密度モデルよりも大幅に優れています。 各モーダル グループのエキスパートの数を増やすと、モデルのパフォーマンスをさらに向上させることができます。 チームは、MoE と MoD、およびそれらを組み合わせた形式を使用すると、トレーニング損失の収束速度が向上することを観察しました。図 4 に示すように、MoD (mod_moe_1t1i) を moe_1t1i アーキテクチャに追加すると、さまざまなモデル サイズにわたってモデルのパフォーマンスが大幅に向上します。 さらに、mod_moe_1t1i は、さまざまなモデル サイズやモードで moe_4t4i に匹敵するか、さらに上回ることができます。これは、深さ次元にスパース性を導入することによってトレーニング効率も効果的に向上できることを示しています。 その一方で、MoDとMoEを重ねるメリットが徐々に減っていくこともわかります。 専門家の数の拡大の影響を研究するために、チームはさらなるアブレーション実験を実施しました。彼らは、各モダリティに同数の専門家を割り当てる (バランスがとれた) 場合と、各モダリティに異なる数の専門家を割り当てる (アンバランスがとれた) という 2 つのシナリオを検討しました。結果を図 5 に示します。 バランスの取れた設定では、エキスパートの数が増加するにつれて、トレーニング損失が大幅に減少することが図 5a からわかります。ただし、テキストと画像の損失は異なるスケーリング パターンを示します。これは、各モダリティの固有の特性が異なるスパース モデリング動作につながることを示唆しています。 アンバランス設定の場合、図 5b は、エキスパートの総数が同等 (8 人) の 3 つの異なる構成を比較しています。モダリティ内の専門家が多いほど、一般にそのモダリティでのモデルのパフォーマンスが向上することがわかります。 チームは当然ながら、前述のアップグレードと変革の効果を検証しました。図 6 は、さまざまなモデル バリアントのトレーニング カーブを比較しています。 この結果は、アップグレードによって実際にモデルのトレーニングがさらに改善されることを示しています。最初のステージのステップ数が 10k の場合、アップグレードにより FLOP は 1.2 倍になり、ステップ数が 20k の場合は 1.16 倍になります。 FLOP が返されます。
さらに、トレーニングが進むにつれて、アップグレードされたモデルと最初からトレーニングされたモデルとの間のパフォーマンスの差が拡大し続けることが観察できます。
疎モデルはダイナミクスとそれに関連するデータバランシングの問題を増大させるため、多くの場合、すぐにはパフォーマンスが向上しません。新しく提案された方法がトレーニング効率に及ぼす影響を定量化するために、チームは、通常制御される変数を使用した実験で、さまざまなアーキテクチャのトレーニング スループットを比較しました。結果を表2に示す。
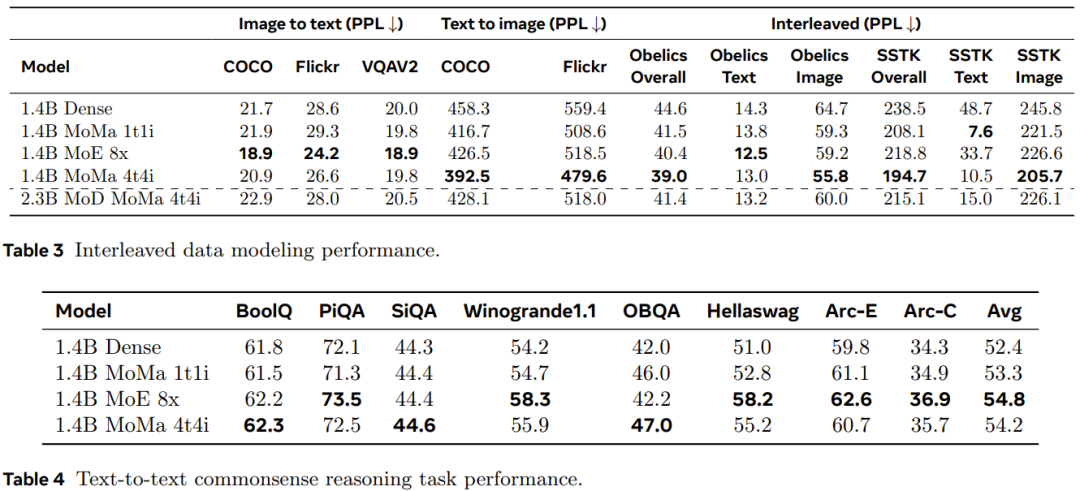
密モデルと比較して、モーダルベースのスパース パフォーマンスは、より優れた品質とスループットのトレードオフを達成し、エキスパートの数が増加するにつれて妥当なスケーラビリティを示すことができることがわかります。一方、MoD バリアントは最高の絶対損失を実現しますが、追加のダイナミクスと不均衡により計算コストが高くなる傾向もあります。 チームはまた、保持された言語モデリングデータと下流タスクにおけるモデルのパフォーマンスも評価しました。結果を表3および表4に示す。 表 3 に示すように、複数の画像エキスパートを使用することにより、1.4B MoMa 1t1i モデルは、COCO および Flickr の例外における画像からテキストへの条件付きパープレキシティ メトリクスを除き、ほとんどのメトリクスで対応する高密度モデルよりも優れています。エキスパートの数をさらに増やすことでパフォーマンスも向上し、14 億 MoE 8x で最高の画像からテキストへのパフォーマンスを実現します。 さらに、表 4 に示すように、1.4B MoE 8x モデルはテキスト間のタスクにも非常に優れています。 1.4B MoMa 4t4i は、すべての条件付き画像パープレキシティ メトリクスで最高のパフォーマンスを発揮しますが、ほとんどのベンチマークでのテキストパープレキシティも 1.4B MoE 8x に非常に近いです。 全体として、1.4B MoMa 4t4i モデルは、テキストと画像の混合モダリティで最高のモデリング結果をもたらします。 Atas ialah kandungan terperinci Pakar hibrid lebih tegas dan boleh melihat pelbagai modaliti dan bertindak mengikut situasi Meta mencadangkan hibrid pakar yang sedar modaliti. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



