
 Peranti teknologi
AI
1 Cemerlang, 5 Lisan! Adakah ACL ByteDance begitu sengit tahun ini? Datang dan bersembang dalam bilik siaran langsung!
Peranti teknologi
AI
1 Cemerlang, 5 Lisan! Adakah ACL ByteDance begitu sengit tahun ini? Datang dan bersembang dalam bilik siaran langsung!
1 Cemerlang, 5 Lisan! Adakah ACL ByteDance begitu sengit tahun ini? Datang dan bersembang dalam bilik siaran langsung!

Tumpuan kalangan akademik minggu ini sudah pasti adalah Sidang Kemuncak ACL 2024 yang diadakan di Bangkok, Thailand. Acara ini menarik ramai penyelidik cemerlang dari seluruh dunia, yang berkumpul bersama untuk membincangkan dan berkongsi keputusan akademik terkini.
Data rasmi menunjukkan bahawa ACL tahun ini menerima hampir 5,000 penyerahan kertas, 940 daripadanya telah diterima oleh persidangan utama, dan 168 karya telah dipilih untuk laporan lisan (Lisan) Kadar penerimaan adalah kurang daripada 3.4%. Antaranya, ByteDance mempunyai 5 keputusan dan Oral telah dipilih.
Dalam sesi Anugerah Kertas pada petang 14 Ogos, Pencapaian ByteDance "G-DIG: Towards Gradient-based Diverse and high-quality Instruction Data Selection for Machine Translation" telah diumumkan secara rasmi oleh penganjur sebagai Kertas Cemerlang ( 1/ 35).现 ACL 2024 di tapak foto
 Kembali ke ACL 2021, byte beating telah mengambil satu-satunya kertas terbaik dengan laurel Ini adalah kali kedua pasukan saintis China telah dipilih untuk kali kedua sejak penubuhan ACL. Hadiah utama!
Kembali ke ACL 2021, byte beating telah mengambil satu-satunya kertas terbaik dengan laurel Ini adalah kali kedua pasukan saintis China telah dipilih untuk kali kedua sejak penubuhan ACL. Hadiah utama!
Untuk mengadakan perbincangan mendalam tentang hasil penyelidikan termaju tahun ini, kami secara khas menjemput pekerja teras kertas kerja ByteDance untuk mentafsir dan berkongsi. Selasa depan, 20 Ogos, dari 19:00-21:00, "ByteDance ACL 2024 Sesi Perkongsian Kertas Termaju" akan disiarkan dalam talian!
Wang Mingxuan, ketua pasukan penyelidik model bahasa Doubao, akan berganding bahu dengan ramai penyelidik ByteDance
Huang Zhichao, Zheng Zaixiang, Li Chaowei, Zhang Xinbo, dan Outstanding Paper's Paper's's result misteri yang berkongsi beberapa tetamu yang menarikdan arahan penyelidikan ACL Ia melibatkan pemprosesan bahasa semula jadi, pemprosesan pertuturan, pembelajaran pelbagai mod, penaakulan model besar dan bidang lain Selamat datang untuk membuat temu janji!
Agenda Acara
Tafsiran Kertas Terpilih



Dengan perkembangan pesat model bahasa besar (LLM), tokenisasi pertuturan diskret memainkan peranan penting dalam menyuntik pertuturan ke dalam LLM. Walau bagaimanapun, pendiskretan ini membawa kepada kehilangan maklumat, sekali gus menjejaskan prestasi keseluruhan. Untuk meningkatkan prestasi token pertuturan diskret ini, kami mencadangkan RepCodec, codec perwakilan pertuturan baru untuk pendiskretan pertuturan semantik. Framework de RepCodec
Contrairement aux codecs audio qui reconstruisent l'audio d'origine, RepCodec apprend le livre de codes VQ en reconstruisant la représentation vocale à partir d'un encodeur vocal tel comme HuBERT ou data2vec. L'encodeur vocal, l'encodeur codec et le livre de codes VQ forment ensemble un processus qui convertit les formes d'onde vocales en jetons sémantiques. Des expériences approfondies montrent que RepCodec surpasse considérablement la méthode de clustering k-means largement utilisée en termes de compréhension et de génération de la parole en raison de ses capacités améliorées de rétention d'informations. De plus, cet avantage s'applique à une variété de codeurs vocaux et de langages, affirmant la robustesse de RepCodec. Cette approche peut faciliter la recherche à grande échelle de modèles linguistiques dans le traitement de la parole. DINOISER : Modèle de génération de séquence conditionnelle de diffusion amélioré par la manipulation du bruit Adresse papier : https://arxiv.org/pdf/2302.10025 Pendant la diffusion le modèle génère Un grand succès a été obtenu avec des signaux continus tels que des images et du son, mais des difficultés subsistent dans l'apprentissage de données de séquences discrètes comme le langage naturel. Bien qu’une série récente de modèles de diffusion de texte contourne ce défi de la discrétion en intégrant des états discrets dans un espace latent d’états continus, leur qualité de génération reste insatisfaisante.
Pour comprendre cela, nous analysons d'abord en profondeur le processus de formation des modèles de génération de séquences basés sur des modèles de diffusion et identifions trois problèmes sérieux avec eux : (1) l'échec d'apprentissage ; (2) le manque d'évolutivité ; (3) le signal de condition de négligence ; Nous pensons que ces problèmes peuvent être attribués à l'imperfection de la discrétion dans l'espace d'intégration, où l'ampleur du bruit joue un rôle décisif.
Dans ce travail, nous proposons DINOISER, qui améliore les modèles de diffusion pour la génération de séquences en manipulant le bruit. Nous déterminons de manière adaptative la plage de l'échelle de bruit échantillonnée pendant la phase d'entraînement d'une manière inspirée par la transmission optimale, et encourageons le modèle pendant la phase d'inférence à mieux exploiter le signal conditionnel en amplifiant l'échelle de bruit. Les expériences montrent que, sur la base de la stratégie efficace de formation et d'inférence proposée, DINOISER surpasse la ligne de base des modèles de génération de séquences de diffusion précédents sur plusieurs références de modélisation de séquences conditionnelles. Une analyse plus approfondie a également vérifié que DINOISER peut mieux utiliser les signaux conditionnels pour contrôler son processus de génération.
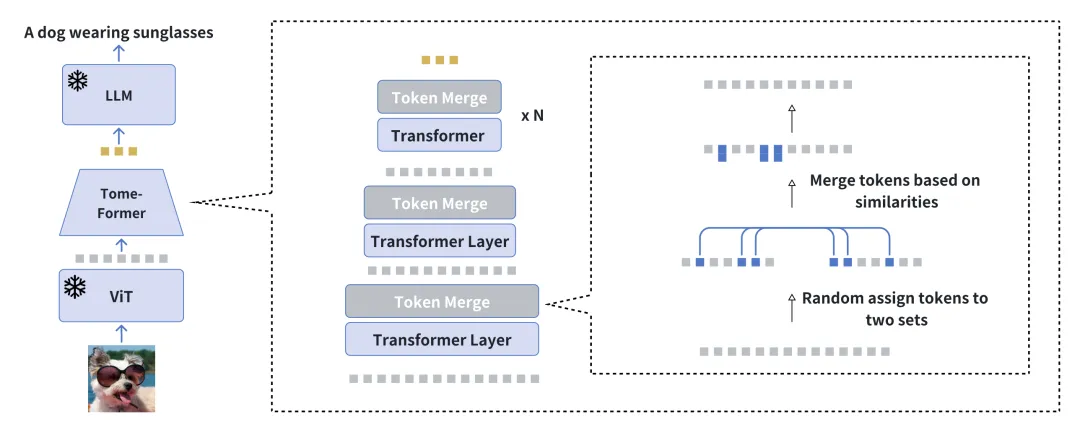
Accélérer la formation à la génération visuelle de langage conditionnel en réduisant la redondance Adresse papier : https://arxiv.org/pdf/2310.03291 Nous vous présentons EVLGen, un outil pour un langage simplifié cadre conçu pour la pré-formation de modèles de génération de langage visuellement conditionnels avec des exigences de calcul élevées, exploitant des grands modèles de langage (LLM) gelés et pré-entraînés. L'approche conventionnelle en pré-entraînement au langage visuel (VLP) implique généralement un processus d'optimisation en deux étapes : une étape initiale gourmande en ressources dédiée au langage visuel général. Axes d'apprentissage de la représentation sur l’extraction et l’intégration de caractéristiques visuelles pertinentes. Ceci est suivi d'une phase de suivi mettant l'accent sur l'alignement de bout en bout entre les modalités visuelles et linguistiques. Notre nouveau cadre en une seule étape et à perte unique contourne la première étape de formation exigeante en termes de calcul en fusionnant progressivement des repères visuels similaires pendant la formation, tout en évitant les inconvénients du modèle causés par la formation en une seule étape de l'effondrement des modèles de type BLIP-2. Le processus de fusion progressif compresse efficacement les informations visuelles tout en conservant la richesse sémantique, permettant ainsi une convergence rapide sans affecter les performances. Les résultats expérimentaux montrent que notre méthode accélère de 5 fois la formation des modèles de langage visuel sans impact significatif sur les performances globales. De plus, notre modèle réduit considérablement l'écart de performances avec les modèles de langage visuel actuels en utilisant seulement 1/10ème des données. Enfin, nous montrons comment notre modèle image-texte peut être adapté de manière transparente aux tâches de génération de langage conditionnées par la vidéo grâce à un nouveau module de contexte étiqueté temporel et attentionnel doux.
StreamVoice : modélisation de langage contextuelle diffusable pour une conversion vocale en temps réel sans prise de vue
Adresse papier : https://arxiv.org/pdf/2401.11053
Streaming Streaming La conversion vocale sans tir fait référence à la capacité de convertir la parole d'entrée en parole de n'importe quel locuteur en temps réel, et ne nécessite qu'une seule phrase de la voix de l'orateur comme référence, et ne nécessite pas de mises à jour supplémentaires du modèle. Les méthodes existantes de conversion vocale à échantillon nul sont généralement conçues pour des systèmes hors ligne et sont difficiles à répondre aux exigences de capacité de diffusion en continu des applications de conversion vocale en temps réel. Les méthodes récentes basées sur un modèle de langage (LM) ont démontré d'excellentes performances en matière de génération de parole sans tir (y compris la conversion), mais nécessitent un traitement de phrases complètes et sont limitées à des scénarios hors ligne. L'architecture globale de StreamVoice G-DIG : Engagé en faveur d'une diversité de traduction automatique basée sur des gradients et d'une sélection de données d'instruction de haute qualité Adresse papier : https://arxiv.org/pdf/2405.12915 Large Les modèles de langage (LLM) ont démontré des capacités extraordinaires dans des scénarios généraux. Le réglage fin des instructions leur permet d'effectuer des tâches comparables à celles des humains. Cependant, la diversité et la qualité des données sur l’enseignement restent deux défis majeurs pour le réglage fin de l’enseignement. À cette fin, nous proposons une nouvelle approche basée sur le gradient pour sélectionner automatiquement des données de réglage fin d'instructions diversifiées et de haute qualité pour la traduction automatique. Notre innovation clé réside dans l'analyse de la manière dont les exemples de formation individuels affectent le modèle pendant la formation.
Présentation de G-DIG
Plus précisément, nous sélectionnons des exemples de formation qui ont un impact bénéfique sur le modèle en tant qu'exemples de haute qualité à l'aide de fonction d'influence et un petit ensemble de données de départ de haute qualité. De plus, pour améliorer la diversité des données d'entraînement, nous maximisons la diversité de leur influence sur le modèle en regroupant et en rééchantillonnant leurs gradients. Des expériences approfondies sur les tâches de traduction WMT22 et FLORES démontrent la supériorité de notre méthode, et une analyse approfondie valide en outre son efficacité et sa généralité.
GroundingGPT : langage amélioré Multimodal Modèle de mise à la terre Adresse papier : https://arxiv.org/pdf/2401.06071 Grand langage multimodal Le modèle démontre d’excellentes performances dans diverses tâches selon différentes modalités. Cependant, les modèles précédents mettent principalement l'accent sur la capture d'informations globales sur les entrées multimodales. Par conséquent, ces modèles n'ont pas la capacité de comprendre efficacement les détails des données d'entrée et fonctionnent mal dans les tâches qui nécessitent en même temps une compréhension détaillée de l'entrée. de ces modèles souffrent de graves problèmes d'hallucinations, limitant son utilisation généralisée.
Afin de résoudre ce problème et d'améliorer la polyvalence des grands modèles multimodaux dans un plus large éventail de tâches, nous proposons GroundingGPT, un modèle multimodal capable d'obtenir différentes compréhensions granulaires des images, des vidéos et des audios. En plus de capturer des informations globales, le modèle proposé est également efficace pour gérer des tâches qui nécessitent une compréhension plus fine, telles que la capacité du modèle à identifier des régions spécifiques dans une image ou des moments spécifiques dans une vidéo. Afin d'atteindre cet objectif, nous avons conçu un processus de construction d'ensembles de données diversifié pour construire un ensemble de données de formation multimodal et multigranulaire. Des expériences sur plusieurs benchmarks publics démontrent la polyvalence et l’efficacité de notre modèle.
ReFT : Inférence basée sur un réglage fin du renforcement Adresse papier : https://arxiv.org/pdf/2401.08967 Un renforcement commun pour les grands modèles de langage (LLM) inférence L'approche capable est le réglage fin supervisé (SFT) à l'aide de données annotées de chaîne de pensée (CoT). Cependant, cette méthode ne montre pas une capacité de généralisation suffisamment forte car la formation repose uniquement sur les données CoT fournies. Plus précisément, dans les ensembles de données liés à des problèmes mathématiques, il n'existe généralement qu'un seul chemin de raisonnement annoté pour chaque problème dans les données d'entraînement. Pour l’algorithme, s’il peut apprendre plusieurs chemins de raisonnement étiquetés pour un problème, il aura de plus fortes capacités de généralisation.
Untuk menyelesaikan cabaran ini, dengan mengambil masalah matematik sebagai contoh, kami mencadangkan kaedah mudah dan berkesan yang dipanggil Reinforced Fine-Tuning (ReFT) untuk meningkatkan keupayaan generalisasi LLM semasa inferens. ReFT mula-mula menggunakan SFT untuk memanaskan model, dan kemudian menggunakan pembelajaran pengukuhan dalam talian (khususnya algoritma PPO dalam kerja ini) untuk pengoptimuman, yang secara automatik mengambil sampel sejumlah besar laluan penaakulan untuk masalah tertentu dan memperoleh ganjaran berdasarkan jawapan sebenar untuk penalaan halus lagi. Percubaan meluas pada set data GSM8K, MathQA dan SVAMP menunjukkan bahawa ReFT mengatasi prestasi SFT dengan ketara, dan prestasi model boleh dipertingkatkan lagi dengan menggabungkan strategi seperti pengundian majoriti dan penyusunan semula. Perlu diingat bahawa di sini ReFT hanya bergantung pada masalah latihan yang sama seperti SFT dan tidak bergantung pada masalah latihan tambahan atau dipertingkatkan. Ini menunjukkan bahawa ReFT mempunyai keupayaan generalisasi yang unggul. Nantikan soalan interaktif anda
Masa siaran langsung: 20 Ogos 2024 (Selasa) 19:00-21:00 Akaun siaran langsung Pasukan Doubhat: Nombor Buku Merah Xiao [Penyelidik Doubao] Anda dialu-alukan untuk mengisi soal selidik dan beritahu kami tentang soalan yang anda minati tentang kertas ACL 2024, dan berbual dengan berbilang penyelidik dalam talian! Pasukan model Beanbao terus direkrut dengan hangat Sila klik pautan ini untuk mengetahui maklumat berkaitan pengambilan pasukan.
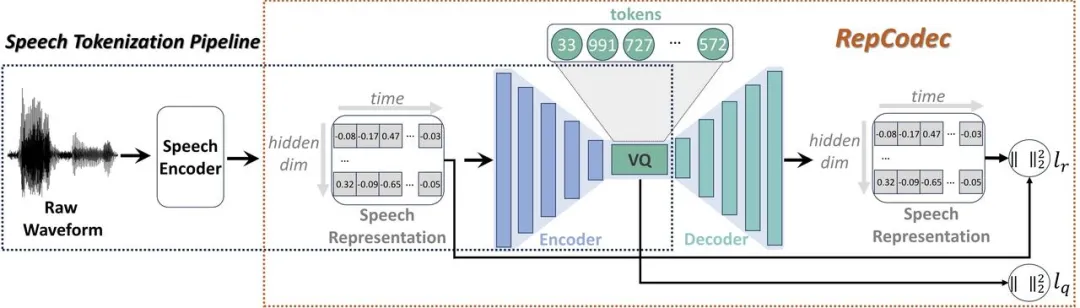 Framework de RepCodec
Framework de RepCodec 


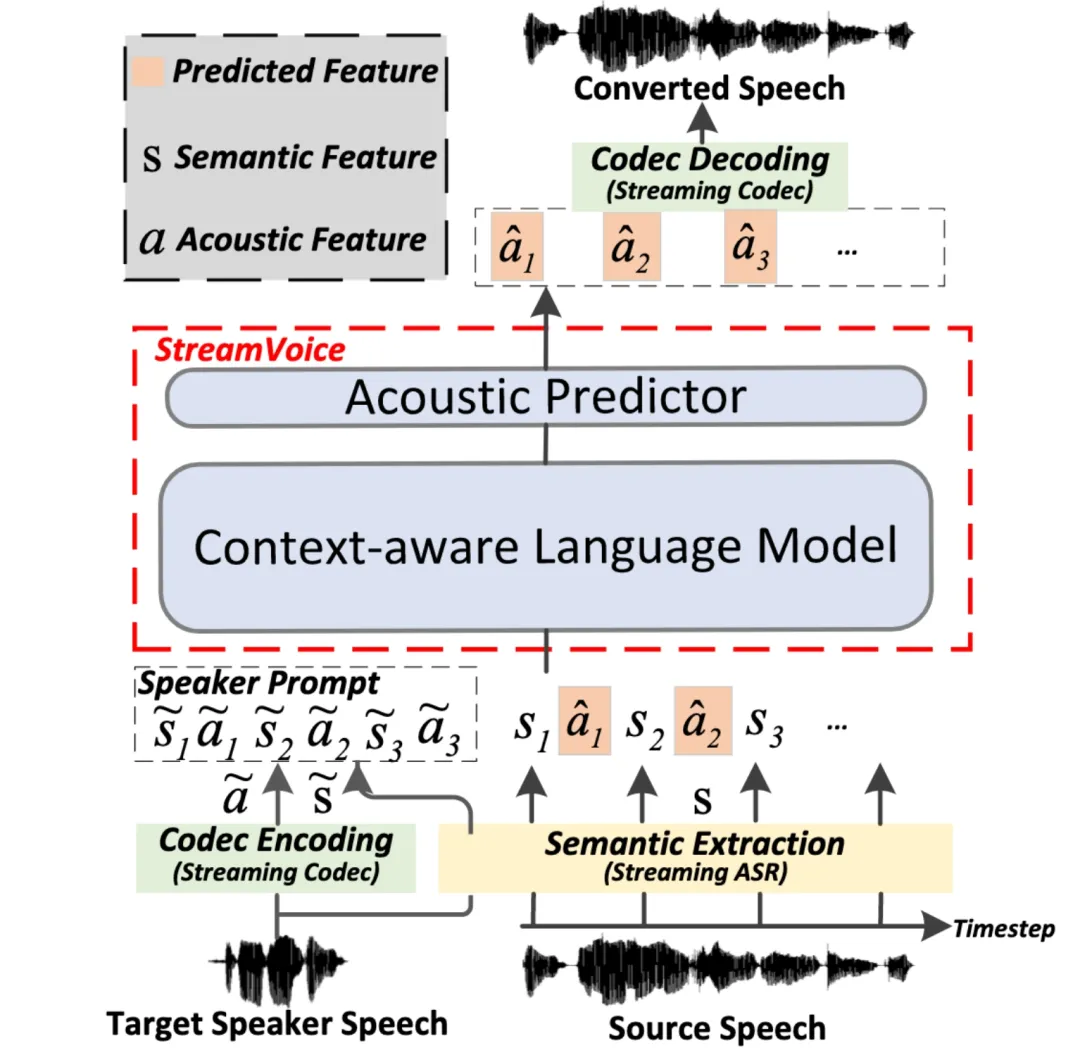 Dans ce travail, nous proposons StreamVoice, un nouveau modèle de conversion vocale sans tir basé sur le streaming LM, pour réaliser une conversion en temps réel pour des locuteurs arbitraires et la parole d'entrée. Plus précisément, pour obtenir des capacités de streaming, StreamVoice utilise un LM entièrement causal et sensible au contexte ainsi qu'un prédicteur acoustique indépendant du timing, tandis que le traitement alterné des caractéristiques sémantiques et acoustiques dans un processus autorégressif élimine la dépendance à l'égard de la parole source complète. Afin de résoudre la dégradation des performances causée par un contexte incomplet dans les scénarios de streaming, deux stratégies sont utilisées pour améliorer la conscience contextuelle du futur et de l'histoire de LM : 1) la prospective contextuelle guidée par l'enseignant, grâce à la prospective contextuelle guidée par l'enseignant. une sémantique précise actuelle et future pour guider le modèle dans la prédiction du contexte manquant ; 2) La stratégie de masquage sémantique encourage le modèle à réaliser une prédiction acoustique à partir d'une entrée sémantique précédemment endommagée et à améliorer la capacité d'apprentissage du contexte historique. Les expériences montrent que StreamVoice possède des capacités de conversion en streaming tout en atteignant des performances zéro-shot proches des systèmes VC sans streaming.
Dans ce travail, nous proposons StreamVoice, un nouveau modèle de conversion vocale sans tir basé sur le streaming LM, pour réaliser une conversion en temps réel pour des locuteurs arbitraires et la parole d'entrée. Plus précisément, pour obtenir des capacités de streaming, StreamVoice utilise un LM entièrement causal et sensible au contexte ainsi qu'un prédicteur acoustique indépendant du timing, tandis que le traitement alterné des caractéristiques sémantiques et acoustiques dans un processus autorégressif élimine la dépendance à l'égard de la parole source complète. Afin de résoudre la dégradation des performances causée par un contexte incomplet dans les scénarios de streaming, deux stratégies sont utilisées pour améliorer la conscience contextuelle du futur et de l'histoire de LM : 1) la prospective contextuelle guidée par l'enseignant, grâce à la prospective contextuelle guidée par l'enseignant. une sémantique précise actuelle et future pour guider le modèle dans la prédiction du contexte manquant ; 2) La stratégie de masquage sémantique encourage le modèle à réaliser une prédiction acoustique à partir d'une entrée sémantique précédemment endommagée et à améliorer la capacité d'apprentissage du contexte historique. Les expériences montrent que StreamVoice possède des capacités de conversion en streaming tout en atteignant des performances zéro-shot proches des systèmes VC sans streaming. 



 Comparaison entre SFT et ReFT sur la présence d'alternatives CoT
Comparaison entre SFT et ReFT sur la présence d'alternatives CoT
Atas ialah kandungan terperinci 1 Cemerlang, 5 Lisan! Adakah ACL ByteDance begitu sengit tahun ini? Datang dan bersembang dalam bilik siaran langsung!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Tetapi mungkin dia tidak dapat mengalahkan lelaki tua di taman itu? Sukan Olimpik Paris sedang rancak berlangsung, dan pingpong telah menarik perhatian ramai. Pada masa yang sama, robot juga telah membuat penemuan baru dalam bermain pingpong. Sebentar tadi, DeepMind mencadangkan ejen robot pembelajaran pertama yang boleh mencapai tahap pemain amatur manusia dalam pingpong yang kompetitif. Alamat kertas: https://arxiv.org/pdf/2408.03906 Sejauh manakah robot DeepMind bermain pingpong? Mungkin setanding dengan pemain amatur manusia: kedua-dua pukulan depan dan pukulan kilas: pihak lawan menggunakan pelbagai gaya permainan, dan robot juga boleh bertahan: servis menerima dengan putaran yang berbeza: Walau bagaimanapun, keamatan permainan nampaknya tidak begitu sengit seperti lelaki tua di taman itu. Untuk robot, pingpong
 Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Pada 21 Ogos, Persidangan Robot Dunia 2024 telah diadakan dengan megah di Beijing. Jenama robot rumah SenseTime "Yuanluobot SenseRobot" telah memperkenalkan seluruh keluarga produknya, dan baru-baru ini mengeluarkan robot permainan catur AI Yuanluobot - Edisi Profesional Catur (selepas ini dirujuk sebagai "Yuanluobot SenseRobot"), menjadi robot catur A pertama di dunia untuk rumah. Sebagai produk robot permainan catur ketiga Yuanluobo, robot Guoxiang baharu telah melalui sejumlah besar peningkatan teknikal khas dan inovasi dalam AI dan jentera kejuruteraan Buat pertama kalinya, ia telah menyedari keupayaan untuk mengambil buah catur tiga dimensi melalui cakar mekanikal pada robot rumah, dan melaksanakan Fungsi mesin manusia seperti bermain catur, semua orang bermain catur, semakan notasi, dsb.
 Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Permulaan sekolah akan bermula, dan bukan hanya pelajar yang akan memulakan semester baharu yang harus menjaga diri mereka sendiri, tetapi juga model AI yang besar. Beberapa ketika dahulu, Reddit dipenuhi oleh netizen yang mengadu Claude semakin malas. "Tahapnya telah banyak menurun, ia sering berhenti seketika, malah output menjadi sangat singkat. Pada minggu pertama keluaran, ia boleh menterjemah dokumen penuh 4 halaman sekaligus, tetapi kini ia tidak dapat mengeluarkan separuh halaman pun. !" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dalam siaran bertajuk "Totally disappointed with Claude", penuh dengan
 Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Dunia yang diadakan di Beijing, paparan robot humanoid telah menjadi tumpuan mutlak di gerai Stardust Intelligent, pembantu robot AI S1 mempersembahkan tiga persembahan utama dulcimer, seni mempertahankan diri dan kaligrafi dalam. satu kawasan pameran, berkebolehan kedua-dua sastera dan seni mempertahankan diri, menarik sejumlah besar khalayak profesional dan media. Permainan elegan pada rentetan elastik membolehkan S1 menunjukkan operasi halus dan kawalan mutlak dengan kelajuan, kekuatan dan ketepatan. CCTV News menjalankan laporan khas mengenai pembelajaran tiruan dan kawalan pintar di sebalik "Kaligrafi Pengasas Syarikat Lai Jie menjelaskan bahawa di sebalik pergerakan sutera, bahagian perkakasan mengejar kawalan daya terbaik dan penunjuk badan yang paling menyerupai manusia (kelajuan, beban). dll.), tetapi di sisi AI, data pergerakan sebenar orang dikumpulkan, membolehkan robot menjadi lebih kuat apabila ia menghadapi situasi yang kuat dan belajar untuk berkembang dengan cepat. Dan tangkas
 Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Pada persidangan ACL ini, para penyumbang telah mendapat banyak keuntungan. ACL2024 selama enam hari diadakan di Bangkok, Thailand. ACL ialah persidangan antarabangsa teratas dalam bidang linguistik pengiraan dan pemprosesan bahasa semula jadi Ia dianjurkan oleh Persatuan Antarabangsa untuk Linguistik Pengiraan dan diadakan setiap tahun. ACL sentiasa menduduki tempat pertama dalam pengaruh akademik dalam bidang NLP, dan ia juga merupakan persidangan yang disyorkan CCF-A. Persidangan ACL tahun ini adalah yang ke-62 dan telah menerima lebih daripada 400 karya termaju dalam bidang NLP. Petang semalam, persidangan itu mengumumkan kertas kerja terbaik dan anugerah lain. Kali ini, terdapat 7 Anugerah Kertas Terbaik (dua tidak diterbitkan), 1 Anugerah Kertas Tema Terbaik, dan 35 Anugerah Kertas Cemerlang. Persidangan itu turut menganugerahkan 3 Anugerah Kertas Sumber (ResourceAward) dan Anugerah Impak Sosial (
 Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Penyepaduan mendalam penglihatan dan pembelajaran robot. Apabila dua tangan robot bekerja bersama-sama dengan lancar untuk melipat pakaian, menuang teh dan mengemas kasut, ditambah pula dengan 1X robot humanoid NEO yang telah menjadi tajuk berita baru-baru ini, anda mungkin mempunyai perasaan: kita seolah-olah memasuki zaman robot. Malah, pergerakan sutera ini adalah hasil teknologi robotik canggih + reka bentuk bingkai yang indah + model besar berbilang modal. Kami tahu bahawa robot yang berguna sering memerlukan interaksi yang kompleks dan indah dengan alam sekitar, dan persekitaran boleh diwakili sebagai kekangan dalam domain spatial dan temporal. Sebagai contoh, jika anda ingin robot menuang teh, robot terlebih dahulu perlu menggenggam pemegang teko dan memastikannya tegak tanpa menumpahkan teh, kemudian gerakkannya dengan lancar sehingga mulut periuk sejajar dengan mulut cawan. , dan kemudian condongkan teko pada sudut tertentu. ini
 Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Pengenalan Persidangan Dengan perkembangan pesat sains dan teknologi, kecerdasan buatan telah menjadi kuasa penting dalam menggalakkan kemajuan sosial. Dalam era ini, kami bertuah untuk menyaksikan dan mengambil bahagian dalam inovasi dan aplikasi Kecerdasan Buatan Teragih (DAI). Kecerdasan buatan yang diedarkan adalah cabang penting dalam bidang kecerdasan buatan, yang telah menarik lebih banyak perhatian dalam beberapa tahun kebelakangan ini. Agen berdasarkan model bahasa besar (LLM) tiba-tiba muncul Dengan menggabungkan pemahaman bahasa yang kuat dan keupayaan penjanaan model besar, mereka telah menunjukkan potensi besar dalam interaksi bahasa semula jadi, penaakulan pengetahuan, perancangan tugas, dsb. AIAgent mengambil alih model bahasa besar dan telah menjadi topik hangat dalam kalangan AI semasa. Au
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Petang ini, Hongmeng Zhixing secara rasmi mengalu-alukan jenama baharu dan kereta baharu. Pada 6 Ogos, Huawei mengadakan persidangan pelancaran produk baharu Hongmeng Smart Xingxing S9 dan senario penuh Huawei, membawakan sedan perdana pintar panoramik Xiangjie S9, M7Pro dan Huawei novaFlip baharu, MatePad Pro 12.2 inci, MatePad Air baharu, Huawei Bisheng With banyak produk pintar semua senario baharu termasuk pencetak laser siri X1, FreeBuds6i, WATCHFIT3 dan skrin pintar S5Pro, daripada perjalanan pintar, pejabat pintar kepada pakaian pintar, Huawei terus membina ekosistem pintar senario penuh untuk membawa pengguna pengalaman pintar Internet Segala-galanya. Hongmeng Zhixing: Pemerkasaan mendalam untuk menggalakkan peningkatan industri kereta pintar Huawei berganding bahu dengan rakan industri automotif China untuk menyediakan
