
 Peranti teknologi
AI
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Peranti teknologi
AI
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe

本届 ACL 大会,投稿者「收获满满」。


作者:Julie Kallini, Isabel Papadimitriou, Richard Futrell, Kyle Mahowald, Christopher Potts 机构:斯坦福大学、加州大学尔湾分校、得克萨斯大学奥斯汀分校 论文链接:https://arxiv.org/abs/2401.06416

저자: Michael Hahn, Mark Rofin 기관: 자를란트 대학교 논문 링크: https://arxiv.org /abs/2402.09963

저자: Haisu Guan, Huanxin Yang, Xinyu Wang, Shengwei Han 등 -
기관: 화중대학교 Science and Technology , A Adelaide University, Anyang Normal College, South China University of Technology 논문 링크: https://arxiv.org/pdf/2406.00684

저자: Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, Tiago Pimentel 기관: 캠브리지 대학교, ETH 취리히 Academy 논문 링크: https://arxiv.org/pdf/2406.04327
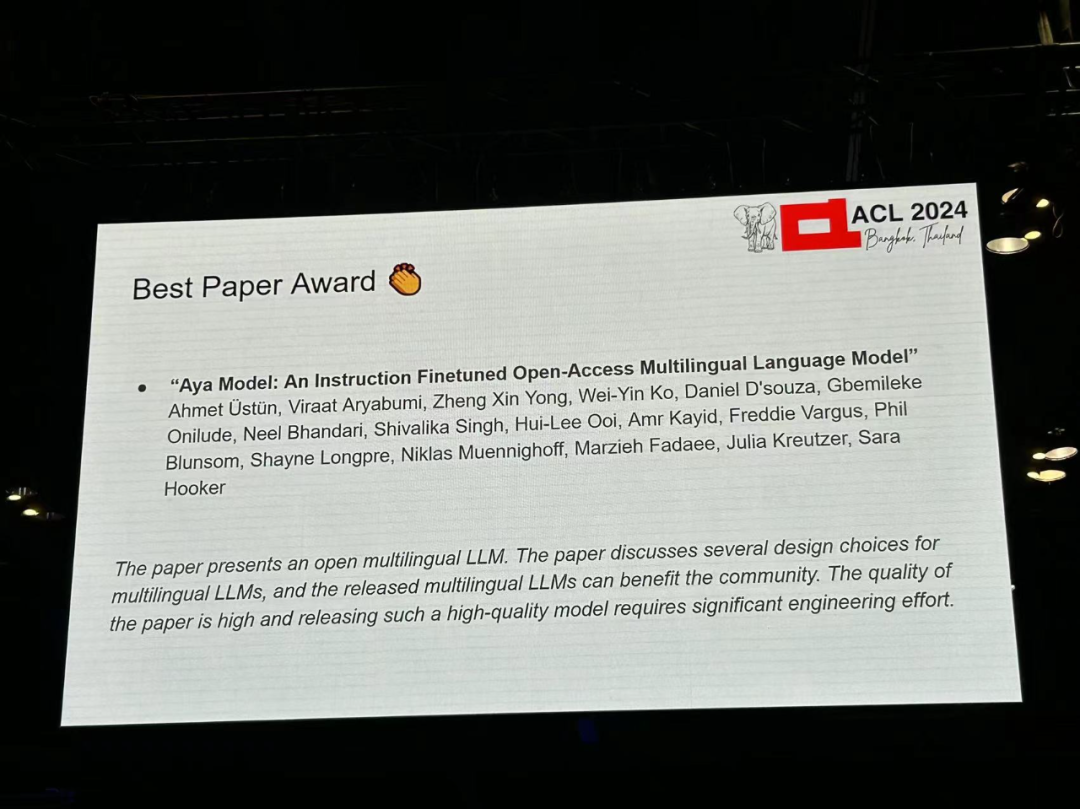
저자: Ahmet Üstün, Viraat Aryabumi, Zheng Xin Yong, Wei-Yin Ko 등 기관: Cohere, Brown University et al 논문 링크: https://arxiv.org/pdf/2402.07827

저자: Liang Lu, Peirong Xie, David R. Mortensen -
기관: CMU, Southern California -
논문 링크: https://arxiv.org/pdf/2406.05930

-
저자: Tharindu Madusanka, Ian Pratt-Hartmann, Riza Batista-Navarro

Auteurs : Jeffrey Pennington, Richard Socher, Christopher D. Manning Institution : Université de Stanford Lien de l'article : https:/ / /aclanthology.org/D14-1162.pdf

Auteur : Lillian Lee Institution : Cornell University -
Lien papier : https://aclanthology .org /P99-1004.pdf


论文 1:Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models 作者:Zhengxin Zhang, Dan Zhao, Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Qing Li, Yong Jiang, Zhihao Jia 机构:CMU、清华大学、鹏城实验室等 论文链接:https://arxiv.org/pdf/2401.07159
论文 2:L-Eval: Instituting Standardized Evaluation for Long Context Language Models 作者:Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, Xipeng Qiu 机构:复旦大学、香港大学、伊利诺伊大学厄巴纳 - 香槟分校、上海 AI Lab 论文链接:https://arxiv.org/abs/2307.11088
论文 3:Causal-Guided Active Learning for Debiasing Large Language Models 论文链接:https://openreview.net/forum?id=idp_1Q6F-lC
论文 4:CausalGym: Benchmarking causal interpretability methods on linguistic tasks 作者:Aryaman Arora, Dan Jurafsky, Christopher Potts 机构:斯坦福大学 论文链接:https://arxiv.org/abs/2402.12560
论文 5:Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration 作者:Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov 机构:华盛顿大学、加州大学伯克利分校、香港科技大学、CMU 论文链接:https://arxiv.org/abs/2402.00367
论文 6:Speech Translation with Speech Foundation Models and Large Language Models: What is There and What is Missing? 作者:Marco Gaido, Sara Papi, Matteo Negri, Luisa Bentivogli 机构:意大利布鲁诺・凯斯勒基金会 论文链接:https://arxiv.org/abs/2402.12025
论文 7:Must NLP be Extractive? 作者:Steven Bird 机构:查尔斯达尔文大学 论文链接:https://drive.google.com/file/d/1hvF7_WQrou6CWZydhymYFTYHnd3ZIljV/view
论文 8:IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators 作者:Indraneil Paul、Goran Glavaš、Iryna Gurevych 机构:达姆施塔特工业大学等 -
论文链接:https://arxiv.org/abs/2403.03894 论文 9:MultiLegalPile: A 689GB Multilingual Legal Corpus 作者:Matthias Stürmer 、 Veton Matoshi 等 机构:伯尔尼大学、斯坦福大学等 论文链接:https://arxiv.org/pdf/2306.02069
论文 10:PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety 作者: Zaibin Zhang 、 Yongting Zhang 、 Lijun Li 、 Hongzhi Gao 、 Lijun Wang 、 Huchuan Lu 、 Feng Zhao 、 Yu Qiao、Jing Shao 机构:上海人工智能实验室、大连理工大学、中国科学技术大学 论文链接:https://arxiv.org/pdf/2401.11880
论文 11:Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation 作者:Dongjin Kang、Sunghwan Kim 等 机构:延世大学等 论文链接:https://arxiv.org/pdf/2402.13211
论文 12:Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models 作者:Paul Röttger 、 Valentin Hofmann 等 机构:博科尼大学、艾伦人工智能研究院等 论文链接:https://arxiv.org/pdf/2402.16786 . Universiti Elan, Institut Allen untuk Kecerdasan Buatan
- Kertas 14: Adakah Llamas dalam Bahasa Inggeris? Transformers
- Pengarang: Chris Wendler, Veniamin Veselovsky, dsb.
- Institusi: EPFL
Kertas 15: Menjadi Serius tentang Humor: Mencipta Model Humor
- duri: Zachary Horvitz, Jingru Chen, dsb.
- Institusi: Columbia University, EPFL
- Pautan kertas: https://arxiv.org/pdf/2403.00794
- Tahap 1 Dialek Meramalkan Perjanjian Inter-annotator dalam Set Data Arab Berbilang dialek
- Institusi: University of Edinburgh
- Pautan kertas: https://arxiv.org /2405.11282
- Kertas 17: G-DlG: Ke Arah Dlverse berasaskan Gradien dan Pemilihan Data Arahan berkualiti tinggi untuk Terjemahan Mesin
u , Yu Lu, Shanbo Cheng Institusi: ByteDance Research Pautan kertas: https: https://arxiv.org/pdf/2405.12915 - Pautan kertas semakan: https://openreview.net id=9AV_zM56pwj
- Kertas 19: SPZ: Kaedah Pembesaran Data Berasaskan Gangguan Semantik dengan Pencampuran Zon untuk Pengesanan Penyakit Alzheimer
hen Su, Jie Yin - paper 20: keserakahan adalah semua yang anda perlukan: Penilaian kaedah Inference Tokenizer: Ben Guri, Negev Ann University, Mit
Authors: Omri Uzan, Craig W. Schmidt, Chris Tanner, Yuval Pinter
Pautan kertas: https://arxiv.org/abs/2403.01289 - Kerumitan Bahasa Ortografik 2. Kekompleksan Resmi 2 Kerumitan Tidak
Institusi: Universiti Notre Dame (AS)
Pengarang: Chihiro Taquchi, David Chiang Pautan kertas : https://arxiv.org26.
- Kertas 22: Pemanduan Llama 2 melalui Penambahan Pengaktifan Kontrastif
- Institusi: Anthropic, Universiti Harvard, Universiti Göttingen (Jerman), Pusat AI Serasi Manusia, Nicky Rimsky, Pengarang Nicky Nick Julian Schulz, Meg Tong, Evan J Hubinger, Alexander Matt Turner
- Pautan kertas: https://arxiv.org/abs/2312.06681
- power Empower-Bahasa Empower: Empower Empower: Empower-Bahasa Empower: Empower-2: Empower 2: Empower Em 2 Agen untuk Mensimulasikan Aktiviti Makroekonomi
- Institusi: Universiti Tsinghua - Sekolah Siswazah Antarabangsa Shenzhen, Universiti Tsinghua
- : https://pautan. //arxiv.org/abs/2310.10436
- Kertas 24: M4LE: A Multi-Ability Multi-Julat Pelbagai Tugas Multi-Domain Penanda Aras Penilaian Konteks Panjang Model Bahasa
: Universiti China Hong Kong, Makmal Huawei Noah's Ark, Universiti Sains dan Teknologi Hong Kong
- Pautan kertas: https://arxiv.org/abs/2310.19240
Kertas 25: Argumen CHECKWHY: Pengesahan Fakta Bersebab🜎 : Jiasheng Si, Yibo Zhao, Yingjie Zhu, Haiyang Zhu, Wenpeng Lu, Deyu Zhou Zu Papier 26: Über EFFIZIENT und Statistik. U darmstadt, Apple Inc für große Sprachmodelle kann nach hinten losgehen!
- Institution: Shanghai Artificial Intelligence Laboratory
- Link zum Papier: https://arxiv.org/PDF/2402.12343 Khan, Priyam Mehta, Ananth Sankar usw.
-
- Link zum Papier: https://arxiv.org/pdf/ 2403.06350
- Papierlink: https://assets.amazon.science/08/83/9b686f424c89b08e8fa0a6e1d020/multipico-multilingual-perspectivist-irony-corpus.pdf
- Aufsatz 30: MMToM-QA: Multimodale Theorie der Beantwortung von Geistesfragen
- Autoren: Chuanyang Jin, Yutong Wu, Jing Cao, jiannan Xiang usw.
- Link zum Papier: https://arxiv.org/pdf/2401.08743
- Papier 31: MAP nicht Noch tot: Aufdeckung wahrer Sprachmodellmodi durch Wegkonditionierung der Degeneration
- Autor: Davis Yoshida, Kartik Goyal, Kevin Gimpel
- Link zum Papier: https https://arxiv.org/pdf/2311.08817
- Aufsatz 33: Die Erde ist flach, weil... der Glaube von LLMs an Fehlinformationen durch überzeugende Gespräche untersucht wird
- Autoren: Rongwu Xu, Brian S. Lin, Shujian Yang, Tiangi Zhang usw.
- Papierlink: https://arxiv.org/pdf/2312.09085
- Papier.3 4: Let's Go Real Talk: Gesprochenes Dialogmodell für persönliche Gespräche
- Autor: Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim usw.
- Papierlink: https://arxiv.org/pdf/2406.07867
- Papier 35: Worteinbettungen sind Steuerelemente für Sprachmodelle
- Autoren: Chi Han, Ji Aliang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek F. Abdelzaher, Heng Ji
- Link zum Papier: https://arxiv.org/pdf /2305.12798
- Best Theme Paper Award
Autoren: Dirk Groeneveld, Iz Beltagy usw. Institution: Allen Institute for Artificial Intelligence, University of Washington usw. Link zum Papier: https://arxiv.org/pdf/2402.00838 - Grund für die Auszeichnung: Dieses Papier zeigt die Bedeutung des Datenmanagements bei der Vorbereitung Datensätze zum Training großer Sprachmodelle. Dies liefert sehr wertvolle Erkenntnisse für ein breites Spektrum von Menschen innerhalb der Community.
- Link: https://arxiv.org/abs/2407.18901
- Gründe für die Auszeichnung: Diese Forschung ist sehr wichtig und erstaunlich beim Aufbau interaktiver Umgebungssimulations- und Bewertungsarbeiten. Es wird alle dazu ermutigen, anspruchsvollere dynamische Benchmarks für die Community zu erstellen.
- Autoren: Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang usw .
- Institutionen: Virginia Tech, Renmin University of China, University of California, Davis, Stanford University
Aufsatz 3: Nach dem Gebet ein Bier trinken? Kulturelle Voreingenommenheit in großen Sprachmodellen messen
- Link: https://arxiv.org/abs/2402.00159
- Autoren: Harsh Trivedi, Tushar Khot usw.
- Aufsatz 1: Wie Johnny LLMs davon überzeugen kann, sie zu jailbreaken: Überzeugungsarbeit überdenken, um die KI-Sicherheit durch Humanisierung von LLMs herauszufordern
- Institutionen: George Mason University, University of Washington, University of Notre Dame, RC Athena ist ein wichtiger Bereich in NLP und künstlicher Intelligenz. Ein wenig erforschtes Phänomen. Aus sprachlicher und gesellschaftlicher Sicht ist seine Forschung jedoch von äußerst hohem Wert und hat wichtige Implikationen für die Anwendung. Dieses Papier schlägt einen sehr neuartigen Maßstab zur Untersuchung dieses Problems in der LLM-Ära vor.
- Grund für die Auszeichnung: Dieser Artikel verdeutlicht ein wichtiges Thema in der LLM-Ära: kulturelle Voreingenommenheit.Cet article examine la culture et le contexte arabe et montre que nous devons prendre en compte les différences culturelles lors de la conception des LLM. Par conséquent, la même étude peut être reproduite dans d’autres cultures pour généraliser et évaluer si d’autres cultures sont également affectées par ce problème.
Atas ialah kandungan terperinci Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1671
1671
 14
1428
52
1329
25
1276
29
1256
24
14
1428
52
1329
25
1276
29
1256
24

 Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Tetapi mungkin dia tidak dapat mengalahkan lelaki tua di taman itu? Sukan Olimpik Paris sedang rancak berlangsung, dan pingpong telah menarik perhatian ramai. Pada masa yang sama, robot juga telah membuat penemuan baru dalam bermain pingpong. Sebentar tadi, DeepMind mencadangkan ejen robot pembelajaran pertama yang boleh mencapai tahap pemain amatur manusia dalam pingpong yang kompetitif. Alamat kertas: https://arxiv.org/pdf/2408.03906 Sejauh manakah robot DeepMind bermain pingpong? Mungkin setanding dengan pemain amatur manusia: kedua-dua pukulan depan dan pukulan kilas: pihak lawan menggunakan pelbagai gaya permainan, dan robot juga boleh bertahan: servis menerima dengan putaran yang berbeza: Walau bagaimanapun, keamatan permainan nampaknya tidak begitu sengit seperti lelaki tua di taman itu. Untuk robot, pingpong
 Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Pada 21 Ogos, Persidangan Robot Dunia 2024 telah diadakan dengan megah di Beijing. Jenama robot rumah SenseTime "Yuanluobot SenseRobot" telah memperkenalkan seluruh keluarga produknya, dan baru-baru ini mengeluarkan robot permainan catur AI Yuanluobot - Edisi Profesional Catur (selepas ini dirujuk sebagai "Yuanluobot SenseRobot"), menjadi robot catur A pertama di dunia untuk rumah. Sebagai produk robot permainan catur ketiga Yuanluobo, robot Guoxiang baharu telah melalui sejumlah besar peningkatan teknikal khas dan inovasi dalam AI dan jentera kejuruteraan Buat pertama kalinya, ia telah menyedari keupayaan untuk mengambil buah catur tiga dimensi melalui cakar mekanikal pada robot rumah, dan melaksanakan Fungsi mesin manusia seperti bermain catur, semua orang bermain catur, semakan notasi, dsb.
 Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Permulaan sekolah akan bermula, dan bukan hanya pelajar yang akan memulakan semester baharu yang harus menjaga diri mereka sendiri, tetapi juga model AI yang besar. Beberapa ketika dahulu, Reddit dipenuhi oleh netizen yang mengadu Claude semakin malas. "Tahapnya telah banyak menurun, ia sering berhenti seketika, malah output menjadi sangat singkat. Pada minggu pertama keluaran, ia boleh menterjemah dokumen penuh 4 halaman sekaligus, tetapi kini ia tidak dapat mengeluarkan separuh halaman pun. !" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dalam siaran bertajuk "Totally disappointed with Claude", penuh dengan
 Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Dunia yang diadakan di Beijing, paparan robot humanoid telah menjadi tumpuan mutlak di gerai Stardust Intelligent, pembantu robot AI S1 mempersembahkan tiga persembahan utama dulcimer, seni mempertahankan diri dan kaligrafi dalam. satu kawasan pameran, berkebolehan kedua-dua sastera dan seni mempertahankan diri, menarik sejumlah besar khalayak profesional dan media. Permainan elegan pada rentetan elastik membolehkan S1 menunjukkan operasi halus dan kawalan mutlak dengan kelajuan, kekuatan dan ketepatan. CCTV News menjalankan laporan khas mengenai pembelajaran tiruan dan kawalan pintar di sebalik "Kaligrafi Pengasas Syarikat Lai Jie menjelaskan bahawa di sebalik pergerakan sutera, bahagian perkakasan mengejar kawalan daya terbaik dan penunjuk badan yang paling menyerupai manusia (kelajuan, beban). dll.), tetapi di sisi AI, data pergerakan sebenar orang dikumpulkan, membolehkan robot menjadi lebih kuat apabila ia menghadapi situasi yang kuat dan belajar untuk berkembang dengan cepat. Dan tangkas
 Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Pada persidangan ACL ini, para penyumbang telah mendapat banyak keuntungan. ACL2024 selama enam hari diadakan di Bangkok, Thailand. ACL ialah persidangan antarabangsa teratas dalam bidang linguistik pengiraan dan pemprosesan bahasa semula jadi Ia dianjurkan oleh Persatuan Antarabangsa untuk Linguistik Pengiraan dan diadakan setiap tahun. ACL sentiasa menduduki tempat pertama dalam pengaruh akademik dalam bidang NLP, dan ia juga merupakan persidangan yang disyorkan CCF-A. Persidangan ACL tahun ini adalah yang ke-62 dan telah menerima lebih daripada 400 karya termaju dalam bidang NLP. Petang semalam, persidangan itu mengumumkan kertas kerja terbaik dan anugerah lain. Kali ini, terdapat 7 Anugerah Kertas Terbaik (dua tidak diterbitkan), 1 Anugerah Kertas Tema Terbaik, dan 35 Anugerah Kertas Cemerlang. Persidangan itu turut menganugerahkan 3 Anugerah Kertas Sumber (ResourceAward) dan Anugerah Impak Sosial (
 Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Penyepaduan mendalam penglihatan dan pembelajaran robot. Apabila dua tangan robot bekerja bersama-sama dengan lancar untuk melipat pakaian, menuang teh dan mengemas kasut, ditambah pula dengan 1X robot humanoid NEO yang telah menjadi tajuk berita baru-baru ini, anda mungkin mempunyai perasaan: kita seolah-olah memasuki zaman robot. Malah, pergerakan sutera ini adalah hasil teknologi robotik canggih + reka bentuk bingkai yang indah + model besar berbilang modal. Kami tahu bahawa robot yang berguna sering memerlukan interaksi yang kompleks dan indah dengan alam sekitar, dan persekitaran boleh diwakili sebagai kekangan dalam domain spatial dan temporal. Sebagai contoh, jika anda ingin robot menuang teh, robot terlebih dahulu perlu menggenggam pemegang teko dan memastikannya tegak tanpa menumpahkan teh, kemudian gerakkannya dengan lancar sehingga mulut periuk sejajar dengan mulut cawan. , dan kemudian condongkan teko pada sudut tertentu. ini
 Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Persidangan Kecerdasan Buatan Teragih DAI 2024 Call for Papers: Hari Agen, Richard Sutton, bapa pembelajaran pengukuhan, akan hadir! Yan Shuicheng, Sergey Levine dan saintis DeepMind akan memberikan ucaptama
Aug 22, 2024 pm 08:02 PM
Pengenalan Persidangan Dengan perkembangan pesat sains dan teknologi, kecerdasan buatan telah menjadi kuasa penting dalam menggalakkan kemajuan sosial. Dalam era ini, kami bertuah untuk menyaksikan dan mengambil bahagian dalam inovasi dan aplikasi Kecerdasan Buatan Teragih (DAI). Kecerdasan buatan yang diedarkan adalah cabang penting dalam bidang kecerdasan buatan, yang telah menarik lebih banyak perhatian dalam beberapa tahun kebelakangan ini. Agen berdasarkan model bahasa besar (LLM) tiba-tiba muncul Dengan menggabungkan pemahaman bahasa yang kuat dan keupayaan penjanaan model besar, mereka telah menunjukkan potensi besar dalam interaksi bahasa semula jadi, penaakulan pengetahuan, perancangan tugas, dsb. AIAgent mengambil alih model bahasa besar dan telah menjadi topik hangat dalam kalangan AI semasa. Au
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Petang ini, Hongmeng Zhixing secara rasmi mengalu-alukan jenama baharu dan kereta baharu. Pada 6 Ogos, Huawei mengadakan persidangan pelancaran produk baharu Hongmeng Smart Xingxing S9 dan senario penuh Huawei, membawakan sedan perdana pintar panoramik Xiangjie S9, M7Pro dan Huawei novaFlip baharu, MatePad Pro 12.2 inci, MatePad Air baharu, Huawei Bisheng With banyak produk pintar semua senario baharu termasuk pencetak laser siri X1, FreeBuds6i, WATCHFIT3 dan skrin pintar S5Pro, daripada perjalanan pintar, pejabat pintar kepada pakaian pintar, Huawei terus membina ekosistem pintar senario penuh untuk membawa pengguna pengalaman pintar Internet Segala-galanya. Hongmeng Zhixing: Pemerkasaan mendalam untuk menggalakkan peningkatan industri kereta pintar Huawei berganding bahu dengan rakan industri automotif China untuk menyediakan
