
 Peranti teknologi
AI
Nvidia bermain dengan pemangkasan dan penyulingan: mengurangkan separuh parameter Llama 3.1 8B untuk mencapai prestasi yang lebih baik dengan saiz yang sama
Peranti teknologi
AI
Nvidia bermain dengan pemangkasan dan penyulingan: mengurangkan separuh parameter Llama 3.1 8B untuk mencapai prestasi yang lebih baik dengan saiz yang sama
Nvidia bermain dengan pemangkasan dan penyulingan: mengurangkan separuh parameter Llama 3.1 8B untuk mencapai prestasi yang lebih baik dengan saiz yang sama

L'essor des petits modèles.
Le mois dernier, Meta a lancé la série de modèles Llama 3.1, qui comprend le plus grand modèle 405B de Meta à ce jour, ainsi que deux modèles plus petits avec respectivement 70 milliards et 8 milliards de paramètres.
Llama 3.1 est considéré comme inaugurant une nouvelle ère de l'open source. Cependant, bien que les modèles de nouvelle génération soient puissants en termes de performances, ils nécessitent néanmoins une grande quantité de ressources informatiques lors de leur déploiement.
Par conséquent, une autre tendance est apparue dans l'industrie, qui consiste à développer des petits modèles de langage (SLM) qui fonctionnent assez bien dans de nombreuses tâches linguistiques et sont également très peu coûteux à déployer.
Récemment, des recherches de NVIDIA ont montré qu'un élagage structuré du poids combiné à une distillation des connaissances peut progressivement obtenir des modèles de langage plus petits à partir d'un modèle initialement plus grand. M Yann Lecun, lauréat du prix Turing et scientifique en chef en IA de Meta, a également salué la recherche.

Llama-3.1-Minitron 4B surpasse les modèles open source de pointe de taille similaire, notamment Minitron 4B, Phi-2 2.7B, Gemma2 2.6B et Qwen2-1.5B.
L'article pertinent sur cette recherche a été publié dès le mois dernier.

Lien de l'article : https://www.arxiv.org/pdf/2407.14679

- Élagage et distillation
-
Taille rend le modèle plus petit et plus mince, et peut être obtenu en supprimant des couches (élagage en profondeur) ou en supprimant des neurones et des têtes d'attention et en intégrant des canaux (élagage en largeur). L'élagage s'accompagne généralement d'un certain degré de recyclage pour restaurer la précision.
Il existe deux méthodes principales de distillation : la mise au point SDG et la distillation classique des connaissances. Ces deux méthodes de distillation sont complémentaires. Cet article se concentre sur les méthodes classiques de distillation des connaissances.
NVIDIA utilise une méthode qui combine l'élagage et la distillation des connaissances classiques pour construire de grands modèles. La figure ci-dessous montre le processus d'élagage et de distillation d'un seul modèle (en haut) et la chaîne d'élagage et de distillation du modèle (en bas). Le processus spécifique est le suivant : 1. NVIDIA commence avec un modèle 15B, évalue l'importance de chaque composant (couche, neurone, tête et canal d'intégration), puis trie et élague le modèle pour atteindre la taille cible : modèle 8B. 2. Utilisez ensuite la distillation du modèle pour une reconversion légère, avec le modèle original comme enseignant et le modèle élagué comme élève. 3. Après l'entraînement, prenez le petit modèle (8B) comme point de départ, taillez-le et distillez-le en un modèle 4B plus petit. Le processus de taille et de distillation du modèle 15B. Le point à noter est qu'avant d'élaguer le modèle, vous devez comprendre quelles parties du modèle sont importantes. NVIDIA propose une stratégie d'évaluation de l'importance pure basée sur l'activation qui calcule simultanément les informations dans toutes les dimensions pertinentes (profondeur, neurone, tête et canaux d'intégration), en utilisant un petit ensemble de données d'étalonnage de 1 024 échantillons, et seule la propagation vers l'avant est requise. Cette approche est plus simple et plus rentable que les stratégies qui reposent sur des informations sur les gradients et nécessitent une rétropropagation. Lors de l'élagage, vous pouvez alterner de manière itérative entre l'élagage et l'estimation de l'importance pour un axe ou une combinaison d'axes donnée. Des études empiriques montrent que l’utilisation d’une seule estimation de l’importance est suffisante et que les estimations itératives n’apportent pas d’avantages supplémentaires.
La figure 2 ci-dessous montre le processus de distillation, dans lequel le modèle étudiant en couche N (le modèle élagué) est distillé à partir du modèle enseignant en couche M (le modèle original non élagué). Le modèle étudiant est appris en minimisant une combinaison de perte de sortie intégrée, de perte logit et de pertes spécifiques au codeur du transformateur mappées aux blocs étudiant S et aux blocs enseignant T. Figure 2 : Perte de formation par distillation.

Meilleures pratiques pour l'élagage et la distillationBasé sur des recherches approfondies sur l'ablation sur l'élagage et la distillation des connaissances dans des modèles de langage compacts, NVIDIA résume ses résultats d'apprentissage dans les meilleures pratiques de compression structurées suivantes.
La première consiste à ajuster la taille.Pour former un ensemble de LLM, entraînez d'abord le plus grand, puis taillez et distillez de manière itérative pour obtenir des LLM plus petits. Si vous utilisez une stratégie d'entraînement en plusieurs étapes pour entraîner le plus grand modèle, il est préférable d'élaguer et de recycler le modèle obtenu lors de la dernière étape de l'entraînement.
- Élaguez le modèle source disponible le plus proche de la taille cible.
- La seconde est la taille.
- Priorisez la taille en largeur à la taille en profondeur, ce qui fonctionne bien pour les modèles de taille de paramètre inférieure à 15B.
- La troisième est de se reconvertir.
- Recyclage en utilisant uniquement la perte de distillation au lieu d'un entraînement régulier.
- Utilisez la distillation logit uniquement lorsque la profondeur ne diminue pas de manière significative.
- Llama-3.1-Minitron : Mettre les meilleures pratiques en action
- Meta a récemment lancé la puissante famille Llama 3.1 de modèles open source qui rivalisent avec les modèles fermés dans de nombreux benchmarks. Les paramètres de Llama 3.1 vont d'un énorme 405B à 70B et 8B.
Réglage précis par l'enseignant Taille en profondeur uniquement
- "Élagage en largeur uniquement" je suis d'abord a effectué un ensemble complet de tests sur leur ensemble de données (jeton 94B) et affiné le modèle 8B non élagué. Les expériences montrent que si le biais de distribution n’est pas corrigé, le modèle de l’enseignant fournit des conseils sous-optimaux pour l’ensemble de données lors de la distillation.
- Élagage en profondeur uniquement
Pour réduire de 8B à 4B, NVIDIA a élagué 16 couches (50%). Ils évaluent d’abord l’importance de chaque couche ou groupe de sous-couches consécutives en les supprimant du modèle et observent une augmentation de la perte de LM ou une diminution de la précision dans les tâches en aval.
La figure 5 ci-dessous montre les valeurs de perte LM sur l'ensemble de validation après avoir supprimé 1, 2, 8 ou 16 couches. Par exemple, le tracé rouge de la couche 16 indique la perte de LM qui se produit si les 16 premières couches sont supprimées. La couche 17 indique que la perte de LM se produit également si la première couche est conservée et que les couches 2 à 17 sont supprimées. Nvidia observe : Les couches de début et de fin sont les plus importantes. T Figure 5 : L’importance de la taille en profondeur uniquement. - Cependant, NVIDIA observe que cette perte de LM n'est pas forcément directement liée aux performances en aval.
La figure 6 ci-dessous montre la précision Winogrande de chaque modèle élagué. Elle montre qu'il est préférable de supprimer les 16e à 31e couches, la 31e couche étant l'avant-dernière couche. La précision à 5 coups du modèle élagué est nettement plus élevée. avec une précision aléatoire (0,5). Nvidia a pris en compte cette idée et a supprimé les couches 16 à 31. Figure 6 : Précision sur la tâche Winogrande lorsque 16 couches sont supprimées.
- Élagage en largeur uniquement
NVIDIA élague l'intégration (cachée) et les dimensions intermédiaires MLP le long de l'axe de largeur pour compresser Llama 3.1 8B. Plus précisément, ils utilisent la stratégie basée sur l'activation décrite précédemment pour calculer les scores d'importance pour chaque tête d'attention, canal d'intégration et dimension cachée du MLP. Après l'estimation de l'importance, NVIDIA a choisi
pour élaguer la dimension moyenne du MLP de 14336 à 9216.
Taille cachée de 4096 à 3072.
Retenez votre attention sur le nombre de têtes et de couches. 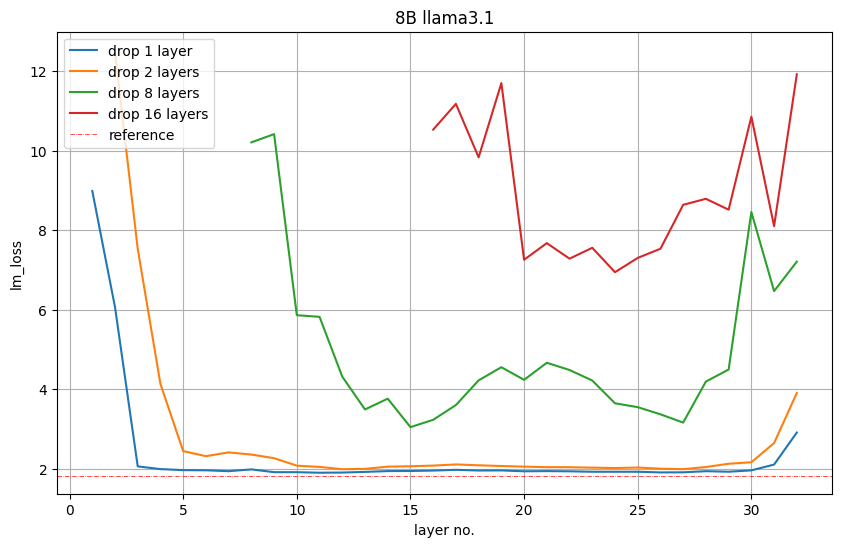
Perlu dinyatakan bahawa selepas pemangkasan sampel tunggal, kehilangan LM pemangkasan lebar adalah lebih tinggi daripada pemangkasan kedalaman. Walau bagaimanapun, selepas tempoh latihan semula yang singkat, arah aliran berubah.
Tanda Aras Ketepatan
NVIDIA menggunakan parameter berikut untuk menyuling model
#🎜##🎜🎜🎜🎜##🎜🎜 #Kadar pembelajaran puncak = 1e-4- Kadar pembelajaran minimum = 1e-5
#🎜🎜 linear Warmup
Cosine Decay Plan
-
Saiz kelompok global = ###saiz kelompok = 1152🎜🎜 🎜🎜#
Jadual 1 di bawah menunjukkan varian model Llama-3.1-Minitron 4B (pantasan lebar dan pemangkasan kedalaman) berbanding model asal Llama 3.1 8B dan model bersaiz serupa lain pada penanda aras merentas berbilang domain Perbandingan prestasi dalam ujian. Secara keseluruhan, NVIDIA sekali lagi mengesahkan keberkesanan strategi pemangkasan yang luas berbanding pemangkasan mendalam yang mengikut amalan terbaik.
untuk Bandingkan.

Mereka menggunakan data latihan Nemotron-4 340B dan menilai pada IFEval, MT-Bench, ChatRAG-Bench dan Berkeley Function Calling Leaderboard (BFCL) untuk menguji arahan mengikut, main peranan, RAG dan fungsi panggilan fungsi. Akhirnya, telah disahkan bahawa model Llama-3.1-Minitron 4B boleh menjadi model arahan yang boleh dipercayai dan mengatasi prestasi SLM asas yang lain. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Jadual 2: Jajarkan kadar tepat model penjajaran dengan model penjajaran skala yang serupa.
Tanda Aras Prestasi
NVIDIA memanfaatkan NVIDIA TensorRT-LLM, alat pengoptimuman LLM, alat sumber terbuka ) model Llama 3.1 8B dan Llama-3.1-Minitron 4B dioptimumkan. Dua angka seterusnya menunjukkan permintaan pemprosesan sesaat bagi model berbeza dengan ketepatan FP8 dan FP16 di bawah kes penggunaan yang berbeza, dinyatakan sebagai panjang jujukan input/panjang jujukan output model 8B dengan saiz kelompok sebanyak 32 (ISL/OSL) serta kombinasi panjang jujukan input/panjang jujukan output (ISL/OSL) dengan saiz kelompok 64 untuk model 4B, terima kasih kepada pemberat yang lebih kecil yang membenarkan saiz kelompok yang lebih besar pada NVIDIA H100 80GB GPU .
Dua angka seterusnya menunjukkan permintaan pemprosesan sesaat bagi model berbeza dengan ketepatan FP8 dan FP16 di bawah kes penggunaan yang berbeza, dinyatakan sebagai panjang jujukan input/panjang jujukan output model 8B dengan saiz kelompok sebanyak 32 (ISL/OSL) serta kombinasi panjang jujukan input/panjang jujukan output (ISL/OSL) dengan saiz kelompok 64 untuk model 4B, terima kasih kepada pemberat yang lebih kecil yang membenarkan saiz kelompok yang lebih besar pada NVIDIA H100 80GB GPU . Varian Llama-3.1-Minitron-4B-Depth-Base adalah yang terpantas, dengan daya pemprosesan purata kira-kira 2.7 kali ganda berbanding Llama 3.1 8B, manakala Llama-3.1-Minitron-4B-Width -Varian asas adalah yang terpantas Purata daya pemprosesan varian adalah kira-kira 1.8 kali ganda daripada Llama 3.1 8B. Penggunaan dalam FP8 juga meningkatkan prestasi ketiga-tiga model sebanyak lebih kurang 1.3x berbanding BF16.
Figur 3. .1 8B ialah BS =32, Llama-3.1-Minitron 4B model BS=64 1x H100 80GB GPU.
Kesimpulan
 Llama-3.1-Minitron 4B ialah percubaan pertama Nvidia menggunakan siri Llama 3.1 sumber terbuka terkini. Untuk menggunakan penalaan halus SDG Llama-3.1 dengan NVIDIA NeMo, lihat bahagian /sdg-law-title-generation di GitHub.
Llama-3.1-Minitron 4B ialah percubaan pertama Nvidia menggunakan siri Llama 3.1 sumber terbuka terkini. Untuk menggunakan penalaan halus SDG Llama-3.1 dengan NVIDIA NeMo, lihat bahagian /sdg-law-title-generation di GitHub. Untuk maklumat lanjut, sila lihat sumber berikut: https://arxiv.org/abs/2407.14679
# 🎜🎜#https://github.com/NVlabs/Minitron
https://huggingface.co/nvidia/Llama- 3.1-Minitron-4B-Width-Base https://huggingface.co/nvidia/Llama-3.1-Minitron-4B-Depth-Base#🎜🎜- Pautan rujukan:
- https://developer.nvidia.nvidia. /cara-memangkas-dan-menyuling-llama-3-1-8b-kepada-nvidia-llama-3-1-minitron-4b-model/
Atas ialah kandungan terperinci Nvidia bermain dengan pemangkasan dan penyulingan: mengurangkan separuh parameter Llama 3.1 8B untuk mencapai prestasi yang lebih baik dengan saiz yang sama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1666
1666
 14
1425
52
1328
25
1273
29
1253
24
14
1425
52
1328
25
1273
29
1253
24

 Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Ia juga merupakan video Tusheng, tetapi PaintsUndo telah mengambil laluan yang berbeza. Pengarang ControlNet LvminZhang mula hidup semula! Kali ini saya menyasarkan bidang lukisan. Projek baharu PaintsUndo telah menerima 1.4kstar (masih meningkat secara menggila) tidak lama selepas ia dilancarkan. Alamat projek: https://github.com/lllyasviel/Paints-UNDO Melalui projek ini, pengguna memasukkan imej statik, dan PaintsUndo secara automatik boleh membantu anda menjana video keseluruhan proses mengecat, daripada draf baris hingga produk siap . Semasa proses lukisan, perubahan garisan adalah menakjubkan Hasil akhir video sangat serupa dengan imej asal: Mari kita lihat lukisan lengkap.
 Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model yang cemerlang. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak bidang. Selain model umum, beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, dan InternVL untuk tugasan bahasa visual.
 Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Semua pengarang kertas kerja ini adalah daripada pasukan guru Zhang Lingming di Universiti Illinois di Urbana-Champaign (UIUC), termasuk: Steven Code repair; pelajar kedoktoran tahun empat, penyelidik
 Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
sorakan! Bagaimana rasanya apabila perbincangan kertas adalah perkataan? Baru-baru ini, pelajar di Universiti Stanford mencipta alphaXiv, forum perbincangan terbuka untuk kertas arXiv yang membenarkan soalan dan ulasan disiarkan terus pada mana-mana kertas arXiv. Pautan laman web: https://alphaxiv.org/ Malah, tidak perlu melawati tapak web ini secara khusus. Hanya tukar arXiv dalam mana-mana URL kepada alphaXiv untuk terus membuka kertas yang sepadan di forum alphaXiv: anda boleh mencari perenggan dengan tepat dalam. kertas itu, Ayat: Dalam ruang perbincangan di sebelah kanan, pengguna boleh menyiarkan soalan untuk bertanya kepada pengarang tentang idea dan butiran kertas tersebut Sebagai contoh, mereka juga boleh mengulas kandungan kertas tersebut, seperti: "Diberikan kepada
 Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Baru-baru ini, Hipotesis Riemann, yang dikenali sebagai salah satu daripada tujuh masalah utama milenium, telah mencapai kejayaan baharu. Hipotesis Riemann ialah masalah yang tidak dapat diselesaikan yang sangat penting dalam matematik, berkaitan dengan sifat tepat taburan nombor perdana (nombor perdana ialah nombor yang hanya boleh dibahagikan dengan 1 dan dirinya sendiri, dan ia memainkan peranan asas dalam teori nombor). Dalam kesusasteraan matematik hari ini, terdapat lebih daripada seribu proposisi matematik berdasarkan penubuhan Hipotesis Riemann (atau bentuk umumnya). Dalam erti kata lain, sebaik sahaja Hipotesis Riemann dan bentuk umumnya dibuktikan, lebih daripada seribu proposisi ini akan ditetapkan sebagai teorem, yang akan memberi kesan yang mendalam terhadap bidang matematik dan jika Hipotesis Riemann terbukti salah, maka antara cadangan ini sebahagian daripadanya juga akan kehilangan keberkesanannya. Kejayaan baharu datang daripada profesor matematik MIT Larry Guth dan Universiti Oxford
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 LLM sememangnya tidak bagus untuk ramalan siri masa Ia bahkan tidak menggunakan keupayaan penaakulannya.
Jul 15, 2024 pm 03:59 PM
LLM sememangnya tidak bagus untuk ramalan siri masa Ia bahkan tidak menggunakan keupayaan penaakulannya.
Jul 15, 2024 pm 03:59 PM
Bolehkah model bahasa benar-benar digunakan untuk ramalan siri masa? Menurut Undang-undang Tajuk Berita Betteridge (sebarang tajuk berita yang berakhir dengan tanda soal boleh dijawab dengan "tidak"), jawapannya mestilah tidak. Fakta nampaknya benar: LLM yang begitu berkuasa tidak dapat mengendalikan data siri masa dengan baik. Siri masa, iaitu, siri masa, seperti namanya, merujuk kepada satu set jujukan titik data yang disusun mengikut urutan masa. Analisis siri masa adalah kritikal dalam banyak bidang, termasuk ramalan penyebaran penyakit, analisis runcit, penjagaan kesihatan dan kewangan. Dalam bidang analisis siri masa, ramai penyelidik baru-baru ini mengkaji cara menggunakan model bahasa besar (LLM) untuk mengelas, meramal dan mengesan anomali dalam siri masa. Makalah ini menganggap bahawa model bahasa yang pandai mengendalikan kebergantungan berjujukan dalam teks juga boleh digeneralisasikan kepada siri masa.
 MLLM berasaskan Mamba yang pertama ada di sini! Berat model, kod latihan, dsb. semuanya telah menjadi sumber terbuka
Jul 17, 2024 am 02:46 AM
MLLM berasaskan Mamba yang pertama ada di sini! Berat model, kod latihan, dsb. semuanya telah menjadi sumber terbuka
Jul 17, 2024 am 02:46 AM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Pengenalan Dalam beberapa tahun kebelakangan ini, aplikasi model bahasa besar multimodal (MLLM) dalam pelbagai bidang telah mencapai kejayaan yang luar biasa. Walau bagaimanapun, sebagai model asas untuk banyak tugas hiliran, MLLM semasa terdiri daripada rangkaian Transformer yang terkenal, yang
