

Muatkan Data Ke dalam Neo4j

Dalam blog sebelum ini kami melihat cara memasang dan menyediakan neo4j secara setempat dengan 2 pemalam APOC dan Perpustakaan Sains Data Graf - GDS. Dalam blog ini saya akan mengambil set data mainan(produk dalam tapak web e-dagang) dan menyimpannya dalam Neo4j.
Memperuntukkan Memori yang Mencukupi Untuk Neo4j
Sebelum mula memuatkan data jika dalam kes penggunaan anda, anda mempunyai data yang besar pastikan jumlah memori yang mencukupi diperuntukkan kepada neo4j. Untuk melakukannya:
- Klik pada tiga titik di sebelah kanan buka

- Klik pada Buka folder -> Tatarajah

- Klik pada neo4j.conf
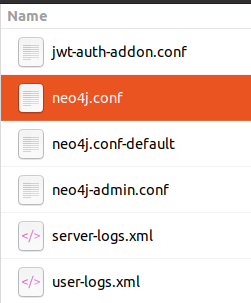
- Cari timbunan dalam neo4j.conf, nyahkomen baris 77, 78 dan tukar 256m kepada 2048m, ini memastikan 2048mb diperuntukkan untuk storan data dalam neo4j .

Mencipta Nod
Graf mempunyai dua komponen utama nod dan perhubungan, mari kita buat nod dahulu dan kemudian wujudkan perhubungan.
Data yang saya gunakan ada di sini - data
Gunakan requirements.txt yang terdapat di sini untuk mencipta persekitaran maya python - requirements.txt
Mari kita tentukan pelbagai fungsi untuk menolak data.
Mengimport perpustakaan yang diperlukan
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI
- Kami akan menggunakan openai untuk menjana benam
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
- Untuk menjana benam
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
- Mengikut set data kami, kami boleh mempunyai dua label nod unik, Kategori : Kategori produk, Produk: Nama produk. Mari buat label kategori, neo4j menawarkan sesuatu yang dipanggil harta, anda boleh bayangkan ini sebagai metadata untuk nod tertentu. Di sini nama dan benam ialah sifatnya. Jadi kami menyimpan nama kategori dan pembenamannya yang sepadan dalam DB.
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
- Begitu juga kita boleh membuat nod produk, di sini sifatnya ialah nama, penerangan, harga, tempoh_waranty, available_stock, review_rating, product_release_date, embedding
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
- Sekarang mari kita cipta satu lagi fungsi untuk melaksanakan pertanyaan yang dijana oleh 2 fungsi di atas. Kemas kini nama pengguna dan kata laluan anda dengan sewajarnya.
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
- Kod lengkap
import pandas as pd
from neo4j import GraphDatabase
from openai import OpenAI
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CREATE CATEGORY
query_list = create_category(product_data_df)
execute_bulk_query(query_list)
# CREATE PRODUCT
query_list = create_product(product_data_df)
execute_bulk_query(query_list)
Mewujudkan Perhubungan
- Kami akan mewujudkan hubungan antara Kategori dan Produk dan nama perhubungan itu ialah KATEGORI_CONTAINS_PRODUCT
from neo4j import GraphDatabase
import pandas as pd
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def create_category_food_relationship_query(product_data_df):
"""
Used to create relationship between category and products
:param product_data_df: dataframe - data
:return: query_list: list - cypher queries
"""
query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)"""
query_list = []
for idx, row in product_data_df.iterrows():
query_list.append(query % (row['Category'], row['Product Name']))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CATEGORY - FOOD RELATIONSHIP
query_list = create_category_food_relationship_query(product_data_df)
execute_bulk_query(query_list)
- Dengan menggunakan pertanyaan MATCH untuk memadankan nod yang telah dibuat, kami mewujudkan hubungan antara masa itu.
Memvisualisasikan Nod Yang Dicipta
Tuding pada ikon buka dan klik pada pelayar neo4j untuk memvisualisasikan nod yang telah kami buat.
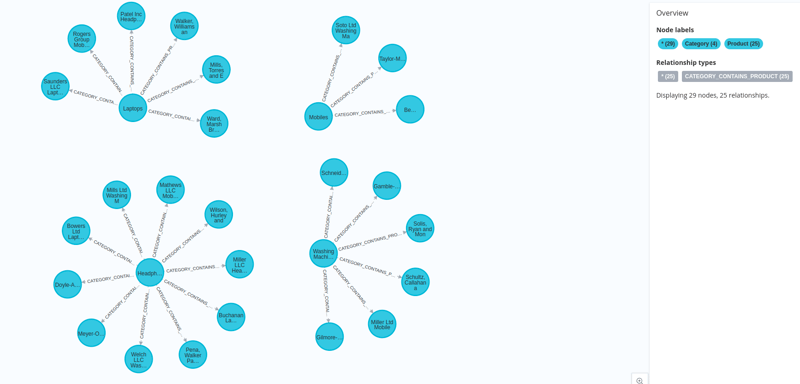
Dan data kami dimuatkan ke dalam neo4j bersama-sama dengan benamnya.
Dalam blog yang akan datang, kita akan melihat cara membina enjin pertanyaan graf menggunakan python dan menggunakan data yang diambil untuk melakukan penjanaan tambahan.
Semoga ini membantu... Jumpa anda !!!
LinkedIn - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/tree/main/push_data_to_db
Atas ialah kandungan terperinci Muatkan Data Ke dalam Neo4j. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Python vs C: Lengkung pembelajaran dan kemudahan penggunaan
Apr 19, 2025 am 12:20 AM
Python vs C: Lengkung pembelajaran dan kemudahan penggunaan
Apr 19, 2025 am 12:20 AM
Python lebih mudah dipelajari dan digunakan, manakala C lebih kuat tetapi kompleks. 1. Sintaks Python adalah ringkas dan sesuai untuk pemula. Penaipan dinamik dan pengurusan memori automatik menjadikannya mudah digunakan, tetapi boleh menyebabkan kesilapan runtime. 2.C menyediakan kawalan peringkat rendah dan ciri-ciri canggih, sesuai untuk aplikasi berprestasi tinggi, tetapi mempunyai ambang pembelajaran yang tinggi dan memerlukan memori manual dan pengurusan keselamatan jenis.
 Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Untuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Python vs C: Meneroka Prestasi dan Kecekapan
Apr 18, 2025 am 12:20 AM
Python vs C: Meneroka Prestasi dan Kecekapan
Apr 18, 2025 am 12:20 AM
Python lebih baik daripada C dalam kecekapan pembangunan, tetapi C lebih tinggi dalam prestasi pelaksanaan. 1. Sintaks ringkas Python dan perpustakaan yang kaya meningkatkan kecekapan pembangunan. 2. Ciri-ciri jenis kompilasi dan kawalan perkakasan meningkatkan prestasi pelaksanaan. Apabila membuat pilihan, anda perlu menimbang kelajuan pembangunan dan kecekapan pelaksanaan berdasarkan keperluan projek.
 Pembelajaran Python: Adakah 2 jam kajian harian mencukupi?
Apr 18, 2025 am 12:22 AM
Pembelajaran Python: Adakah 2 jam kajian harian mencukupi?
Apr 18, 2025 am 12:22 AM
Adakah cukup untuk belajar Python selama dua jam sehari? Ia bergantung pada matlamat dan kaedah pembelajaran anda. 1) Membangunkan pelan pembelajaran yang jelas, 2) Pilih sumber dan kaedah pembelajaran yang sesuai, 3) mengamalkan dan mengkaji semula dan menyatukan amalan tangan dan mengkaji semula dan menyatukan, dan anda secara beransur-ansur boleh menguasai pengetahuan asas dan fungsi lanjutan Python dalam tempoh ini.
 Python vs C: Memahami perbezaan utama
Apr 21, 2025 am 12:18 AM
Python vs C: Memahami perbezaan utama
Apr 21, 2025 am 12:18 AM
Python dan C masing -masing mempunyai kelebihan sendiri, dan pilihannya harus berdasarkan keperluan projek. 1) Python sesuai untuk pembangunan pesat dan pemprosesan data kerana sintaks ringkas dan menaip dinamik. 2) C sesuai untuk prestasi tinggi dan pengaturcaraan sistem kerana menaip statik dan pengurusan memori manual.
 Yang merupakan sebahagian daripada Perpustakaan Standard Python: Senarai atau Array?
Apr 27, 2025 am 12:03 AM
Yang merupakan sebahagian daripada Perpustakaan Standard Python: Senarai atau Array?
Apr 27, 2025 am 12:03 AM
Pythonlistsarepartofthestandardlibrary, sementara
 Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python cemerlang dalam automasi, skrip, dan pengurusan tugas. 1) Automasi: Sandaran fail direalisasikan melalui perpustakaan standard seperti OS dan Shutil. 2) Penulisan Skrip: Gunakan Perpustakaan Psutil untuk memantau sumber sistem. 3) Pengurusan Tugas: Gunakan perpustakaan jadual untuk menjadualkan tugas. Kemudahan penggunaan Python dan sokongan perpustakaan yang kaya menjadikannya alat pilihan di kawasan ini.
 Python untuk Pembangunan Web: Aplikasi Utama
Apr 18, 2025 am 12:20 AM
Python untuk Pembangunan Web: Aplikasi Utama
Apr 18, 2025 am 12:20 AM
Aplikasi utama Python dalam pembangunan web termasuk penggunaan kerangka Django dan Flask, pembangunan API, analisis data dan visualisasi, pembelajaran mesin dan AI, dan pengoptimuman prestasi. 1. Rangka Kerja Django dan Flask: Django sesuai untuk perkembangan pesat aplikasi kompleks, dan Flask sesuai untuk projek kecil atau sangat disesuaikan. 2. Pembangunan API: Gunakan Flask atau DjangorestFramework untuk membina Restfulapi. 3. Analisis Data dan Visualisasi: Gunakan Python untuk memproses data dan memaparkannya melalui antara muka web. 4. Pembelajaran Mesin dan AI: Python digunakan untuk membina aplikasi web pintar. 5. Pengoptimuman Prestasi: Dioptimumkan melalui pengaturcaraan, caching dan kod tak segerak
