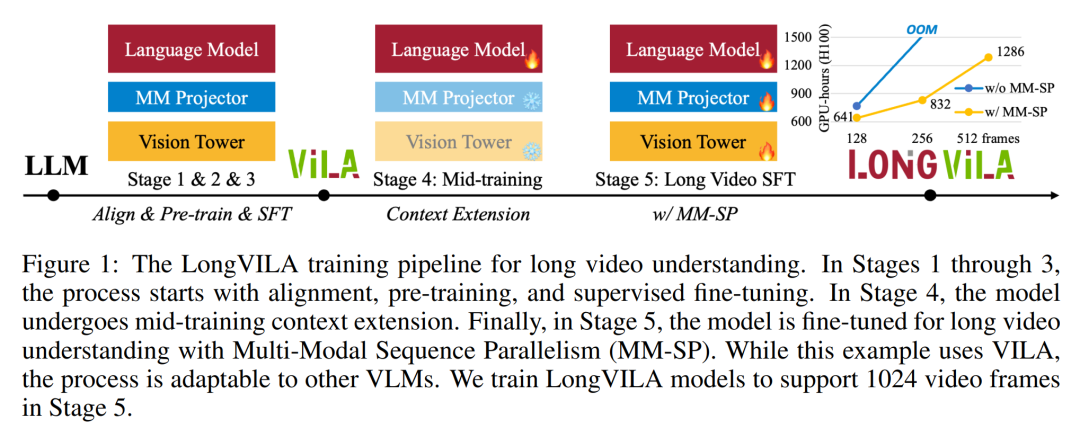
Jetzt verfügt Long Context Visual Language Model (VLM) über eine neue Full-Stack-Lösung – LongVILA, die System, Modelltraining und Datenentwicklung integriert in eins.
In dieser Phase ist es sehr wichtig, das multimodale Verständnis des Modells mit der Fähigkeit zum langen Kontext zu kombinieren. Das Basismodell, das mehr Modalitäten unterstützt, kann flexiblere Eingabesignale akzeptieren, sodass Menschen diversifizieren können Möglichkeiten zur Interaktion mit Modellen. Und ein längerer Kontext ermöglicht es dem Modell, mehr Informationen zu verarbeiten, z. B. lange Dokumente und lange Videos. Diese Fähigkeit bietet auch die Funktionalität, die für realere Anwendungen erforderlich ist. Das aktuelle Problem besteht jedoch darin, dass einige Arbeiten visuelle Sprachmodelle mit langem Kontext (VLM) ermöglicht haben, jedoch normalerweise in einem vereinfachten Ansatz, anstatt eine umfassende Lösung bereitzustellen. Full-Stack-Design ist für visuelle Sprachmodelle mit langem Kontext von entscheidender Bedeutung. Das Training großer Modelle ist in der Regel eine komplexe und systematische Aufgabe, die ein gemeinsames Design von Datentechnik und Systemsoftware erfordert. Im Gegensatz zu Nur-Text-LLMs erfordern VLMs (z. B. LLaVA) häufig einzigartige Modellarchitekturen und flexible verteilte Trainingsstrategien. Darüber hinaus erfordert die Langkontextmodellierung nicht nur Langkontextdaten, sondern auch eine Infrastruktur, die speicherintensives Langkontexttraining unterstützen kann. Daher ist ein gut geplantes Full-Stack-Design (das System, Daten und Pipeline abdeckt) für VLM mit langem Kontext unerlässlich. In diesem Artikel stellen Forscher von NVIDIA, MIT, UC Berkeley und der University of Texas in Austin LongVILA vor, eine Full-Stack-Lösung zum Trainieren und Bereitstellen von visuellen Sprachmodellen mit langem Kontext, einschließlich Systemdesign und Modelltraining Strategie und Datensatzkonstruktion.
- Papieradresse: https://arxiv.org/pdf/2408.10188
- Codeadresse: https://github.com/NVlabs/VILA/blob/main/LongVILA.md
- Titel des Papiers: LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
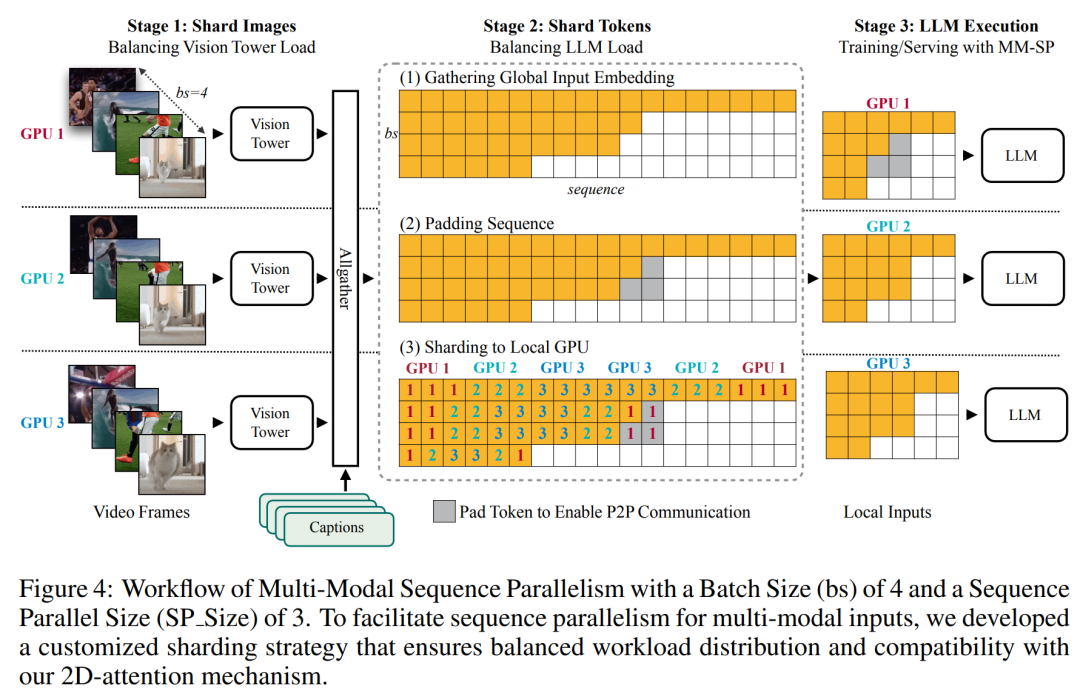
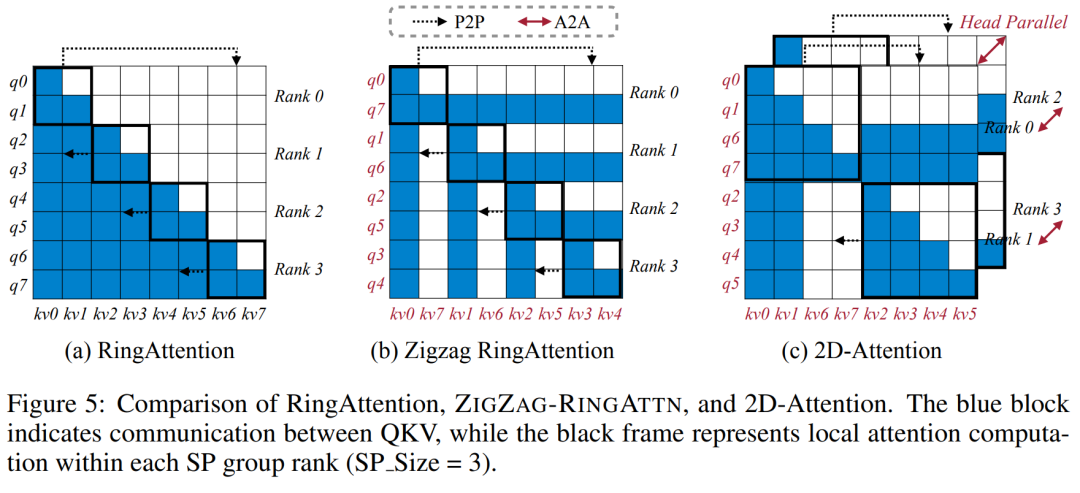
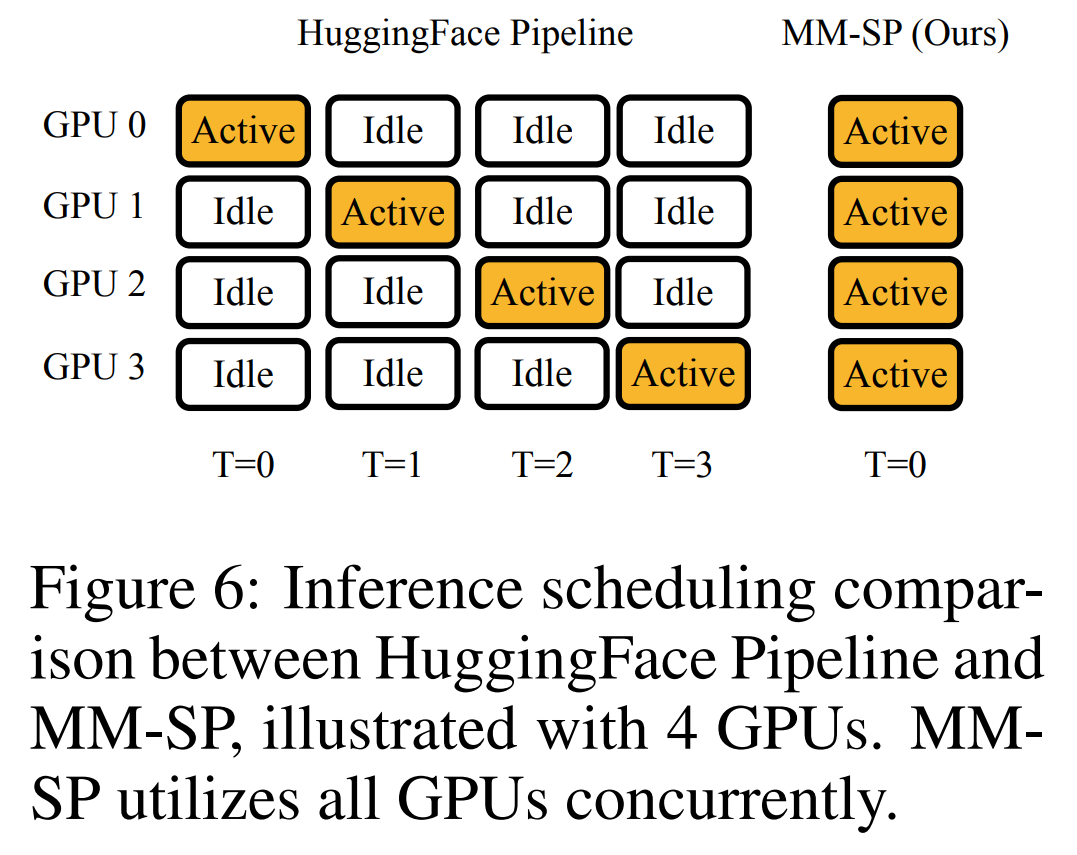
Für die Trainingsinfrastruktur etablierte die Studie ein effizientes und benutzerfreundliches Framework, nämlich Multimodal Sequence Parallel (MM-SP). ), das das Training von Memory-Dense Long Context VLM unterstützt. Für die Trainingspipeline implementierten die Forscher einen fünfstufigen Trainingsprozess, wie in Abbildung 1 dargestellt: nämlich (1) multimodale Ausrichtung, (2) groß angelegtes Vortraining, (3) Kurz- überwachte Feinabstimmung, (4) kontextuelle Erweiterung von LLM und (5) lang überwachte Feinabstimmung. Zur Inferenz löst MM-SP das Problem der KV-Cache-Speichernutzung, die bei der Verarbeitung sehr langer Sequenzen zu einem Engpass werden kann. Durch die Verwendung von LongVILA zur Erhöhung der Anzahl von Videobildern zeigen experimentelle Ergebnisse, dass sich die Leistung dieser Studie bei VideoMME- und langen Video-Untertitelaufgaben weiter verbessert (Abbildung 2). Das auf 1024 Frames trainierte LongVILA-Modell erreichte im Nadel-im-Heuhaufen-Experiment mit 1400 Frames eine Genauigkeit von 99,5 %, was einer Kontextlänge von 274.000 Token entspricht. Darüber hinaus kann das MM-SP-System die Kontextlänge ohne Gradientenprüfpunkte effektiv auf 2 Millionen Token erweitern und so eine 2,1- bis 5,7-fache Beschleunigung im Vergleich zur Ringsequenzparallelität und Megatron-Kontextparallelität erreichen. Die Tensor-Parallelität erreicht eine 1,1- bis 1,4-fache Beschleunigung im Vergleich zu Tensor Parallel. 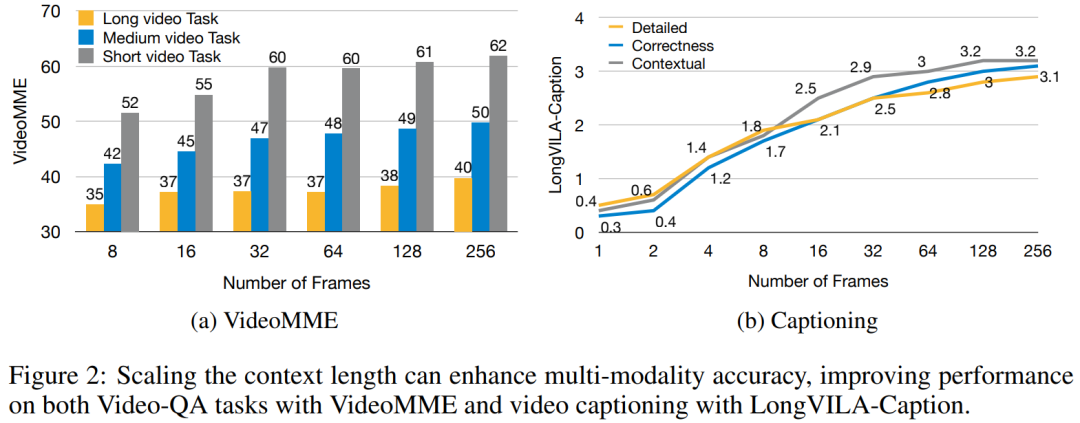 Das Bild unten ist ein Beispiel für die LongVILA-Technologie bei der Verarbeitung langer Videountertitel: Zu Beginn der Untertitel beschreibt das 8-Frame-Basismodell nur ein statisches Bild und zwei Autos. Im Vergleich dazu zeigen 256 Bilder von LongVILA ein Auto auf Schnee, einschließlich Vorder-, Rück- und Seitenansichten des Fahrzeugs. In Bezug auf die Details zeigt das 256-Frame-LongVILA auch Nahaufnahmen des Zündknopfs, des Schalthebels und des Kombiinstruments, die beim 8-Frame-Basismodell fehlen. Multimodale Sequenzparallelität Das Training von Long-Context-Visual-Language-Modellen (VLM) führt zu erheblichen Speicheranforderungen. Im langen Videotraining der Stufe 5 in Abbildung 1 unten enthält beispielsweise eine einzelne Sequenz 200.000 Token, die 1024 Videobilder generieren, was die Speicherkapazität einer einzelnen GPU übersteigt. Forscher haben ein maßgeschneidertes System entwickelt, das auf Sequenzparallelität basiert. Sequentielle Parallelität ist eine Technik, die häufig in aktuellen Basismodellsystemen verwendet wird, um das Nur-Text-LLM-Training zu optimieren. Allerdings stellten Forscher fest, dass bestehende Systeme weder effizient noch skalierbar genug sind, um VLM-Workloads mit langen Kontexten zu bewältigen.Selepas mengenal pasti batasan sistem sedia ada, penyelidik membuat kesimpulan bahawa pendekatan selari jujukan pelbagai mod yang ideal harus menyelesaikan kepelbagaian modal dan rangkaian untuk mengutamakan kecekapan dan kebolehskalaan, dan kebolehskalaan tidak seharusnya dihadkan oleh bilangan ketua perhatian. MM-SP aliran kerja. Untuk menangani cabaran heterogeniti modal, penyelidik mencadangkan strategi sharding dua peringkat untuk mengoptimumkan beban kerja pengiraan dalam peringkat pengekodan imej dan pemodelan bahasa. Seperti yang ditunjukkan dalam Rajah 4 di bawah, peringkat pertama mula-mula mengedarkan imej (seperti bingkai video) secara sama rata antara peranti dalam kumpulan proses selari jujukan. , dengan itu mencapai pengimbangan beban semasa peringkat pengekodan imej. Pada peringkat kedua, penyelidik mengagregatkan input visual dan tekstual global untuk perpecahan peringkat token. 2D keselarian perhatian. Untuk menyelesaikan kepelbagaian rangkaian dan mencapai kebolehskalaan, penyelidik menggabungkan kelebihan selari jujukan Cincin dan selari jujukan Ulysses. Secara khususnya, mereka menganggap keselarian merentas dimensi jujukan atau dimensi kepala perhatian sebagai "1D SP". Kaedah menskalakan melalui pengiraan selari merentas kepala perhatian dan dimensi jujukan, menukarkan SP 1D kepada grid 2D yang terdiri daripada kumpulan bebas proses Ring (P2P) dan Ulysses (A2A). Seperti yang ditunjukkan di sebelah kiri dalam Rajah 3 di bawah, untuk mencapai keselarian jujukan 8 darjah merentas 2 nod, penyelidik menggunakan 2D-SP untuk membina grid komunikasi 4 × 2. Selain itu, dalam Rajah 5 di bawah, untuk menerangkan lebih lanjut bagaimana ZIGZAG-RINGATTN mengimbangi pengiraan dan bagaimana mekanisme 2D-Attention beroperasi, penyelidik terangkan penggunaan Kaedah yang berbeza untuk Skim Pengiraan Perhatian. Berbanding dengan strategi selari saluran paip asli HuggingFace, mod inferens artikel ini adalah lebih cekap kerana semua peranti mengambil bahagian dalam pengiraan pada masa yang sama, oleh itu berkadar dengan bilangan mesin Proses ini dipercepatkan berbanding dengan tanah, seperti yang ditunjukkan dalam Rajah 6 di bawah. Pada masa yang sama, mod inferens ini boleh berskala, dengan memori teragih sama rata merentas peranti untuk menggunakan lebih banyak mesin untuk menyokong jujukan yang lebih panjang. #🎜🎜 #Proses latihan LongVILA
Das Bild unten ist ein Beispiel für die LongVILA-Technologie bei der Verarbeitung langer Videountertitel: Zu Beginn der Untertitel beschreibt das 8-Frame-Basismodell nur ein statisches Bild und zwei Autos. Im Vergleich dazu zeigen 256 Bilder von LongVILA ein Auto auf Schnee, einschließlich Vorder-, Rück- und Seitenansichten des Fahrzeugs. In Bezug auf die Details zeigt das 256-Frame-LongVILA auch Nahaufnahmen des Zündknopfs, des Schalthebels und des Kombiinstruments, die beim 8-Frame-Basismodell fehlen. Multimodale Sequenzparallelität Das Training von Long-Context-Visual-Language-Modellen (VLM) führt zu erheblichen Speicheranforderungen. Im langen Videotraining der Stufe 5 in Abbildung 1 unten enthält beispielsweise eine einzelne Sequenz 200.000 Token, die 1024 Videobilder generieren, was die Speicherkapazität einer einzelnen GPU übersteigt. Forscher haben ein maßgeschneidertes System entwickelt, das auf Sequenzparallelität basiert. Sequentielle Parallelität ist eine Technik, die häufig in aktuellen Basismodellsystemen verwendet wird, um das Nur-Text-LLM-Training zu optimieren. Allerdings stellten Forscher fest, dass bestehende Systeme weder effizient noch skalierbar genug sind, um VLM-Workloads mit langen Kontexten zu bewältigen.Selepas mengenal pasti batasan sistem sedia ada, penyelidik membuat kesimpulan bahawa pendekatan selari jujukan pelbagai mod yang ideal harus menyelesaikan kepelbagaian modal dan rangkaian untuk mengutamakan kecekapan dan kebolehskalaan, dan kebolehskalaan tidak seharusnya dihadkan oleh bilangan ketua perhatian. MM-SP aliran kerja. Untuk menangani cabaran heterogeniti modal, penyelidik mencadangkan strategi sharding dua peringkat untuk mengoptimumkan beban kerja pengiraan dalam peringkat pengekodan imej dan pemodelan bahasa. Seperti yang ditunjukkan dalam Rajah 4 di bawah, peringkat pertama mula-mula mengedarkan imej (seperti bingkai video) secara sama rata antara peranti dalam kumpulan proses selari jujukan. , dengan itu mencapai pengimbangan beban semasa peringkat pengekodan imej. Pada peringkat kedua, penyelidik mengagregatkan input visual dan tekstual global untuk perpecahan peringkat token. 2D keselarian perhatian. Untuk menyelesaikan kepelbagaian rangkaian dan mencapai kebolehskalaan, penyelidik menggabungkan kelebihan selari jujukan Cincin dan selari jujukan Ulysses. Secara khususnya, mereka menganggap keselarian merentas dimensi jujukan atau dimensi kepala perhatian sebagai "1D SP". Kaedah menskalakan melalui pengiraan selari merentas kepala perhatian dan dimensi jujukan, menukarkan SP 1D kepada grid 2D yang terdiri daripada kumpulan bebas proses Ring (P2P) dan Ulysses (A2A). Seperti yang ditunjukkan di sebelah kiri dalam Rajah 3 di bawah, untuk mencapai keselarian jujukan 8 darjah merentas 2 nod, penyelidik menggunakan 2D-SP untuk membina grid komunikasi 4 × 2. Selain itu, dalam Rajah 5 di bawah, untuk menerangkan lebih lanjut bagaimana ZIGZAG-RINGATTN mengimbangi pengiraan dan bagaimana mekanisme 2D-Attention beroperasi, penyelidik terangkan penggunaan Kaedah yang berbeza untuk Skim Pengiraan Perhatian. Berbanding dengan strategi selari saluran paip asli HuggingFace, mod inferens artikel ini adalah lebih cekap kerana semua peranti mengambil bahagian dalam pengiraan pada masa yang sama, oleh itu berkadar dengan bilangan mesin Proses ini dipercepatkan berbanding dengan tanah, seperti yang ditunjukkan dalam Rajah 6 di bawah. Pada masa yang sama, mod inferens ini boleh berskala, dengan memori teragih sama rata merentas peranti untuk menggunakan lebih banyak mesin untuk menyokong jujukan yang lebih panjang. #🎜🎜 #Proses latihan LongVILA #🎜🎜🎜##🎜🎜🎜##🎜##🎜🎜 #Seperti yang dinyatakan di atas, proses latihan LongVILA terbahagi kepada 5 peringkat. Tugas utama setiap peringkat adalah seperti berikut:
Dalam Peringkat 1, hanya pemeta berbilang modal boleh dilatih, dan pemeta lain dibekukan.
Dalam Peringkat 2, penyelidik membekukan pengekod visual dan melatih LLM dan pemeta berbilang modal.
Dalam Peringkat 3, penyelidik memperhalusi model secara menyeluruh untuk arahan data pendek berikutan tugasan, seperti menggunakan set data imej dan video pendek.
Dalam Peringkat 4, penyelidik menggunakan set data teks sahaja untuk memanjangkan panjang konteks LLM dengan cara pra-latihan yang berterusan.
Dalam Peringkat 5, penyelidik menggunakan penyeliaan video yang panjang untuk memperhalusi bagi meningkatkan keupayaan mengikuti arahan. Perlu diingat bahawa semua parameter boleh dilatih dalam peringkat ini.
#🎜##🎜##🎜🎜🎜##🎜🎜🎜 Para penyelidik menilai penyelesaian timbunan penuh dalam artikel ini dari dua aspek: sistem dan pemodelan. Mereka mula-mula membentangkan hasil latihan dan inferens, menggambarkan kecekapan dan kebolehskalaan sistem yang boleh menyokong latihan dan inferens konteks panjang. Kami kemudian menilai prestasi model konteks panjang pada kapsyen dan tugasan berikut arahan. Latihan dan Sistem Inferens
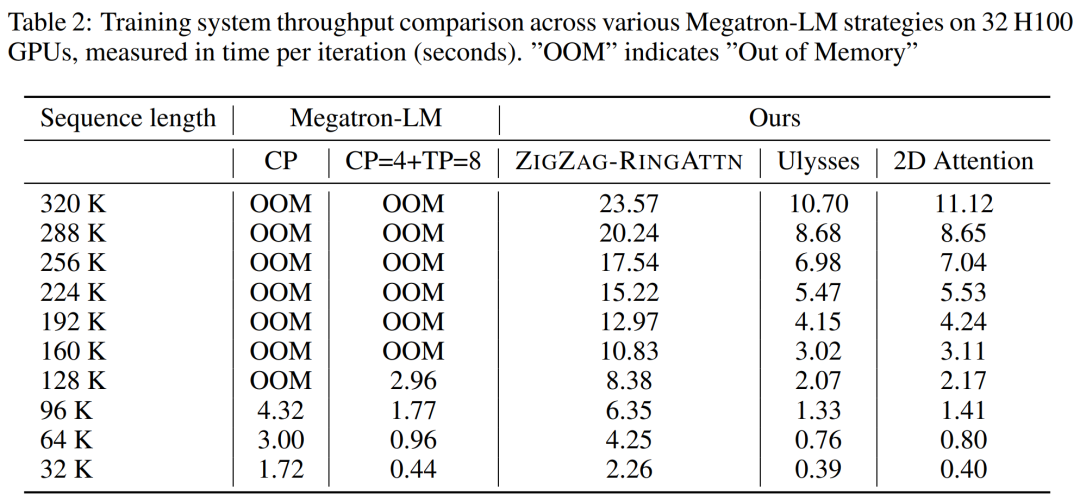
#🎜🎜🎜##🎜🎜🎜##🎜🎜🎜 🎜#Kajian ini menyediakan penilaian kuantitatif daya pemprosesan sistem latihan, kependaman sistem inferens dan panjang jujukan maksimum yang disokong. Jadual 2 menunjukkan hasil pemprosesan. Berbanding dengan ZIGZAG-RINGATTN, sistem ini mencapai pecutan 2.1 kali hingga 5.7 kali, dan prestasinya setanding dengan DeepSpeed-Ulysses. Kelajuan 3.1x hingga 4.3x dicapai berbanding pelaksanaan selari jujukan cincin yang lebih optimum dalam Megatron-LM CP.
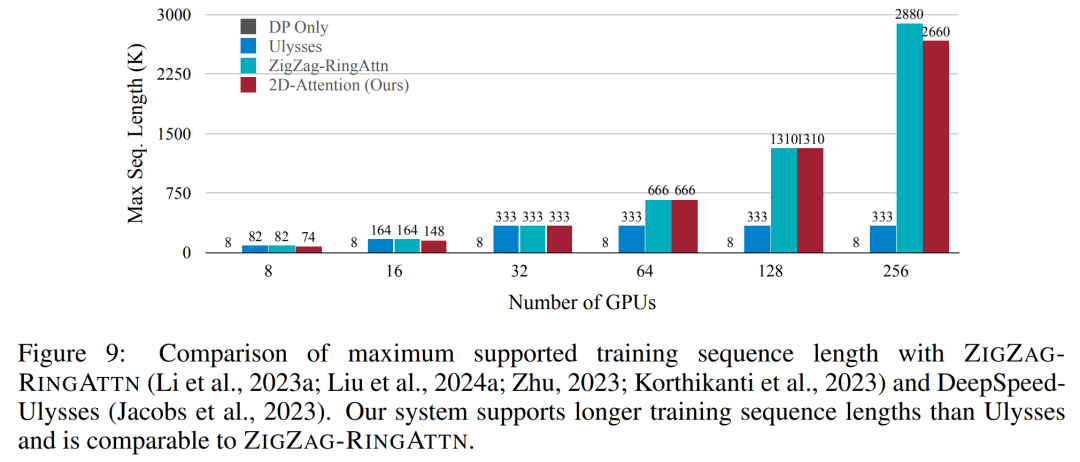
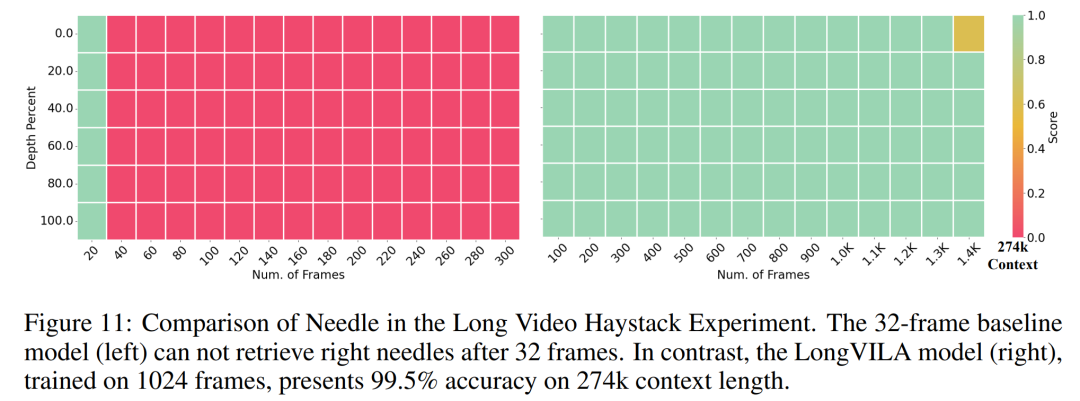
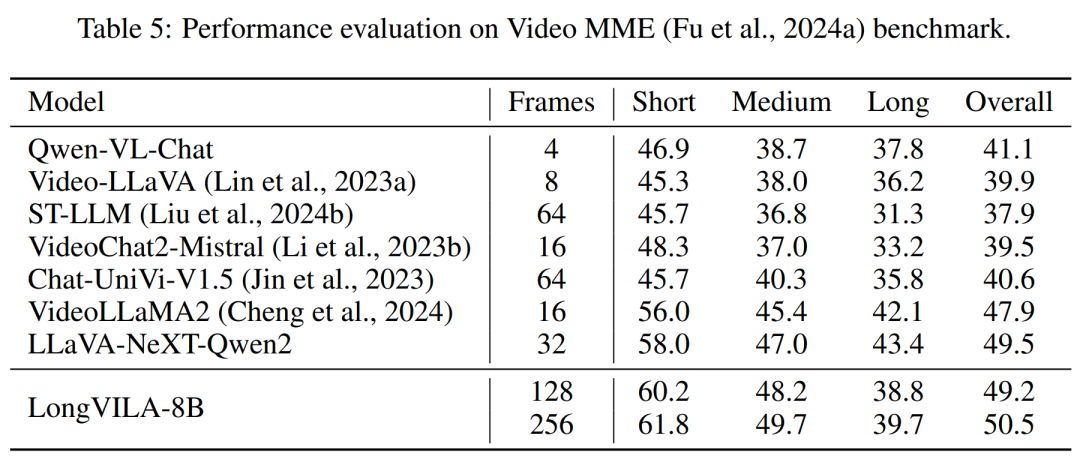
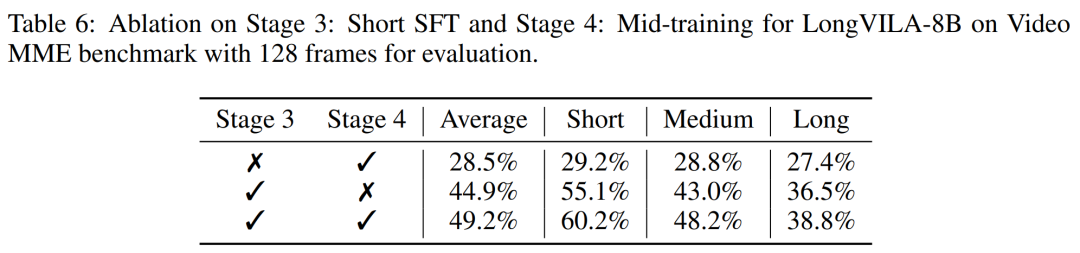
Diese Studie bewertet die maximale Sequenzlänge, die von einer festen Anzahl von GPUs unterstützt wird, indem die Sequenzlänge schrittweise von 1 KB auf 10 KB erhöht wird, bis ein Fehler wegen unzureichendem Speicher auftritt. Die Ergebnisse sind in Abbildung 9 zusammengefasst. Bei einer Skalierung auf 256 GPUs kann unsere Methode etwa das Achtfache der Kontextlänge unterstützen. Darüber hinaus erreicht das vorgeschlagene System eine Kontextlängenskalierung ähnlich wie ZIGZAG-RINGATTN und unterstützt mehr als 2 Millionen Kontextlängen auf 256 GPUs. Tabelle 3 vergleicht die maximal unterstützte Sequenzlänge, und die in dieser Studie vorgeschlagene Methode unterstützt Sequenzen, die 2,9-mal länger sind als die von HuggingFace Pipeline unterstützten. Abbildung 11 zeigt die Ergebnisse des langen Videonadel-im-Heuhaufen-Experiments. Im Gegensatz dazu zeigt das LongVILA-Modell (rechts) eine verbesserte Leistung über eine Reihe von Rahmen und Tiefen hinweg. Tabelle 5 listet die Leistung verschiedener Modelle im Video-MME-Benchmark auf und vergleicht ihre Wirksamkeit bei kurzen, mittleren und langen Videolängen sowie die Gesamtleistung. LongVILA-8B verwendet 256 Bilder und hat eine Gesamtpunktzahl von 50,5. Die Forscher führten außerdem eine Ablationsstudie zu den Auswirkungen der Stadien 3 und 4 in Tabelle 6 durch. Tabelle 7 zeigt die Leistungsmetriken des LongVILA-Modells, das auf einer unterschiedlichen Anzahl von Frames (8, 128 und 256) trainiert und bewertet wurde. Mit zunehmender Anzahl von Frames verbessert sich die Leistung des Modells erheblich. Insbesondere stieg die durchschnittliche Punktzahl von 2,00 auf 3,26, was die Fähigkeit des Modells unterstreicht, bei einer höheren Anzahl von Bildern genaue und reichhaltige Untertitel zu erzeugen. Atas ialah kandungan terperinci Menyokong 1024 bingkai dan hampir 100% ketepatan, NVIDIA 'LongVILA' mula membangunkan video panjang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!






 Windows tidak boleh mengkonfigurasi sambungan wayarles ini
Windows tidak boleh mengkonfigurasi sambungan wayarles ini
 Mengapa win11 tidak boleh dipasang?
Mengapa win11 tidak boleh dipasang?
 Kaedah biasa dalam kelas Matematik
Kaedah biasa dalam kelas Matematik
 Arah aliran harga harga Eth hari ini
Arah aliran harga harga Eth hari ini
 Tujuan memcpy dalam c
Tujuan memcpy dalam c
 Penggunaan asas pernyataan sisipan
Penggunaan asas pernyataan sisipan
 Perbezaan antara akaun perkhidmatan WeChat dan akaun rasmi
Perbezaan antara akaun perkhidmatan WeChat dan akaun rasmi
 Bagaimana untuk menukar perisian bahasa c ke bahasa Cina
Bagaimana untuk menukar perisian bahasa c ke bahasa Cina








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



