

Sukar untuk berhujah Atlassian JIRA ialah salah satu penjejak isu dan penyelesaian pengurusan projek yang paling popular. Anda boleh menyukainya, anda boleh membencinya, tetapi jika anda diupah sebagai jurutera perisian untuk sesetengah syarikat, terdapat kebarangkalian tinggi untuk bertemu dengan JIRA.
Jika projek yang anda sedang kerjakan sangat aktif, mungkin terdapat ribuan isu JIRA pelbagai jenis. Jika anda mengetuai pasukan jurutera, anda boleh berminat dengan alatan analisis yang boleh membantu anda memahami perkara yang sedang berlaku dalam projek berdasarkan data yang disimpan dalam JIRA. JIRA mempunyai beberapa kemudahan pelaporan yang disepadukan, serta pemalam pihak ketiga. Tetapi kebanyakannya agak asas. Contohnya, sukar untuk mencari alatan "ramalan" yang agak fleksibel.
Semakin besar projek, semakin kurang anda berpuas hati dengan alatan pelaporan bersepadu. Pada satu ketika, anda akan menggunakan API untuk mengekstrak, memanipulasi dan menggambarkan data. Sepanjang 15 tahun terakhir penggunaan JIRA, saya melihat berpuluh-puluh skrip dan perkhidmatan sedemikian dalam pelbagai bahasa pengaturcaraan di sekitar domain ini.
Banyak tugas seharian mungkin memerlukan analisis data sekali sahaja, jadi perkhidmatan menulis setiap kali tidak membuahkan hasil. Anda boleh menganggap JIRA sebagai sumber data dan menggunakan tali pinggang alat analisis data biasa. Sebagai contoh, anda boleh mengambil Jupyter, mengambil senarai pepijat terbaru dalam projek, menyediakan senarai "ciri" (atribut yang berharga untuk analisis), menggunakan panda untuk mengira statistik dan cuba meramalkan arah aliran menggunakan scikit-learn. Dalam artikel ini, saya ingin menerangkan cara melakukannya.
Di sini, kita akan bercakap tentang versi awan JIRA. Tetapi jika anda menggunakan versi yang dihoskan sendiri, konsep utama adalah hampir sama.
Pertama sekali, kita perlu mencipta kunci rahsia untuk mengakses JIRA melalui REST API. Untuk berbuat demikian, pergi ke pengurusan profil - https://id.atlassian.com/manage-profile/profile-and-visibility Jika anda memilih tab "Keselamatan", anda akan menemui pautan "Buat dan urus token API":
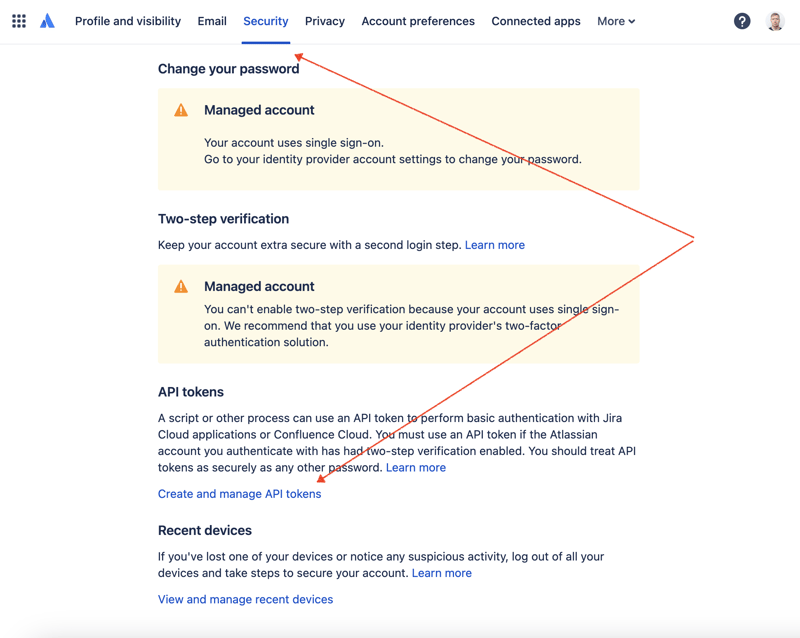
Buat token API baharu di sini dan simpannya dengan selamat. Kami akan menggunakan token ini kemudian.
Salah satu cara yang paling mudah untuk bermain dengan set data ialah menggunakan Jupyter. Jika anda tidak biasa dengan alat ini, jangan risau. Saya akan tunjukkan cara menggunakannya untuk menyelesaikan masalah kita. Untuk percubaan tempatan, saya suka menggunakan DataSpell oleh JetBrains, tetapi terdapat perkhidmatan yang tersedia dalam talian dan secara percuma. Salah satu perkhidmatan yang paling terkenal di kalangan saintis data ialah Kaggle. Walau bagaimanapun, buku nota mereka tidak membenarkan anda membuat sambungan luaran untuk mengakses JIRA melalui API. Satu lagi perkhidmatan yang sangat popular ialah Colab oleh Google. Ia membolehkan anda membuat sambungan jauh dan memasang modul Python tambahan.
JIRA mempunyai API REST yang agak mudah digunakan. Anda boleh membuat panggilan API menggunakan cara kegemaran anda untuk melakukan permintaan HTTP dan menghuraikan respons secara manual. Walau bagaimanapun, kami akan menggunakan modul jira yang sangat baik dan sangat popular untuk tujuan itu.
Mari kita gabungkan semua bahagian untuk menghasilkan penyelesaiannya.
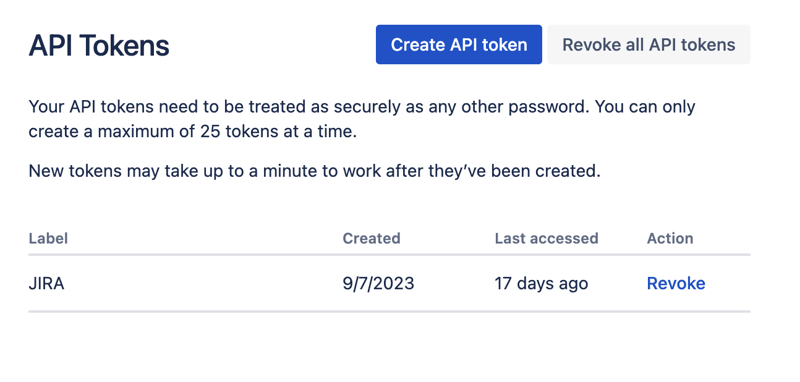
Pergi ke antara muka Google Colab dan buat buku nota baharu. Selepas penciptaan buku nota, kita perlu menyimpan bukti kelayakan JIRA yang diperoleh sebelum ini sebagai "rahsia." Klik ikon "Kunci" dalam bar alat kiri untuk membuka dialog yang sesuai dan tambah dua "rahsia" dengan nama berikut: JIRA_USER dan JIRA_PASSWORD. Di bahagian bawah skrin, anda boleh melihat cara untuk mengakses "rahsia" ini:
Perkara seterusnya ialah memasang modul Python tambahan untuk penyepaduan JIRA. Kita boleh melakukannya dengan melaksanakan arahan shell dalam skop sel notebook:
!pip install jira
Output sepatutnya kelihatan seperti berikut:
Collecting jira
Downloading jira-3.8.0-py3-none-any.whl (77 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.5/77.5 kB 1.3 MB/s eta 0:00:00
Requirement already satisfied: defusedxml in /usr/local/lib/python3.10/dist-packages (from jira) (0.7.1)
...
Installing collected packages: requests-toolbelt, jira
Successfully installed jira-3.8.0 requests-toolbelt-1.0.0
Kita perlu mengambil "rahsia"/kredential:
from google.colab import userdata
JIRA_URL = 'https://******.atlassian.net'
JIRA_USER = userdata.get('JIRA_USER')
JIRA_PASSWORD = userdata.get('JIRA_PASSWORD')
Dan sahkan sambungan ke Awan JIRA:
from jira import JIRA jira = JIRA(JIRA_URL, basic_auth=(JIRA_USER, JIRA_PASSWORD)) projects = jira.projects() projects
Jika sambungan ok dan bukti kelayakannya sah, anda seharusnya melihat senarai projek anda yang tidak kosong:
[<JIRA Project: key='PROJ1', name='Name here..', id='10234'>, <JIRA Project: key='PROJ2', name='Friendly name..', id='10020'>, <JIRA Project: key='PROJ3', name='One more project', id='10045'>, ...
Jadi kami boleh menyambung dan mengambil data daripada JIRA. Langkah seterusnya ialah mengambil beberapa data untuk dianalisis dengan panda. Mari cuba ambil senarai masalah yang telah diselesaikan selama beberapa minggu yang lalu untuk beberapa projek:
JIRA_FILTER = 19762
issues = jira.search_issues(
f'filter={JIRA_FILTER}',
maxResults=False,
fields='summary,issuetype,assignee,reporter,aggregatetimespent',
)
Kami perlu mengubah set data menjadi bingkai data panda:
import pandas as pd
df = pd.DataFrame([{
'key': issue.key,
'assignee': issue.fields.assignee and issue.fields.assignee.displayName or issue.fields.reporter.displayName,
'time': issue.fields.aggregatetimespent,
'summary': issue.fields.summary,
} for issue in issues])
df.set_index('key', inplace=True)
df
Output mungkin kelihatan seperti berikut:
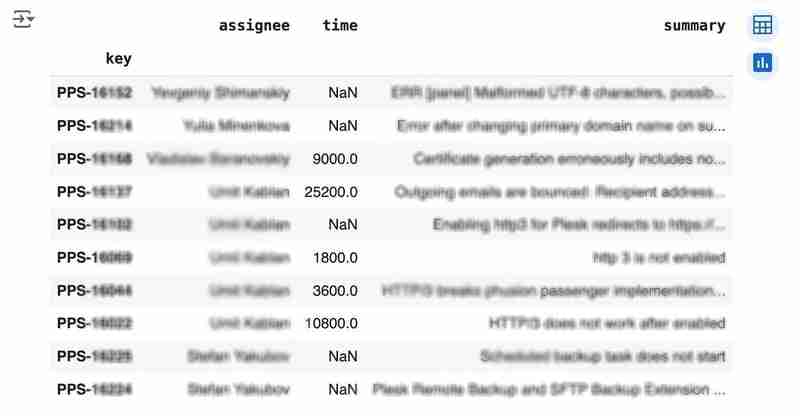
We would like to analyze how much time it usually takes to solve the issue. People are not ideal, so sometimes they forget to log the work. It brings a headache if you try to analyze such data using JIRA built-in tools. But it's not a problem for us to make some adjustments using pandas. For example, we can transform the "time" field from seconds into hours and replace the absent values with the median value (beware, dropna can be more suitable if there are a lot of gaps):
df['time'].fillna(df['time'].median(), inplace=True) df['time'] = df['time'] / 3600
We can easily visualize the distribution to find out anomalies:
df['time'].plot.bar(xlabel='', xticks=[])
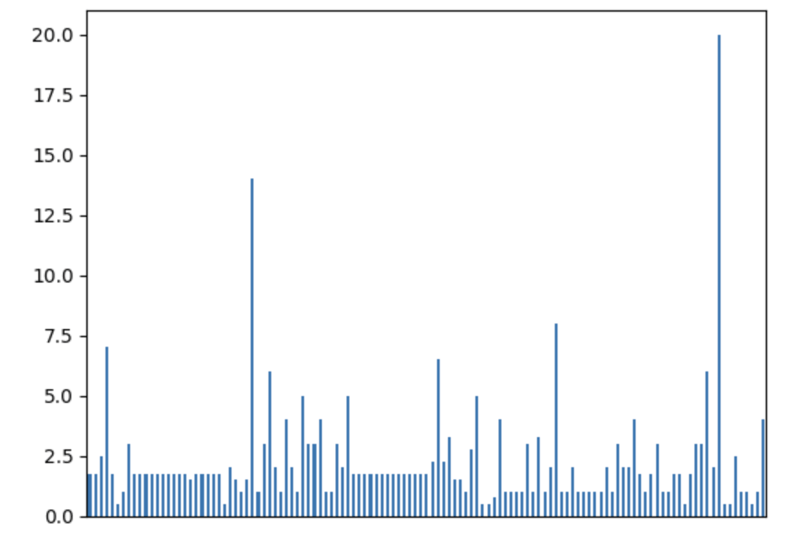
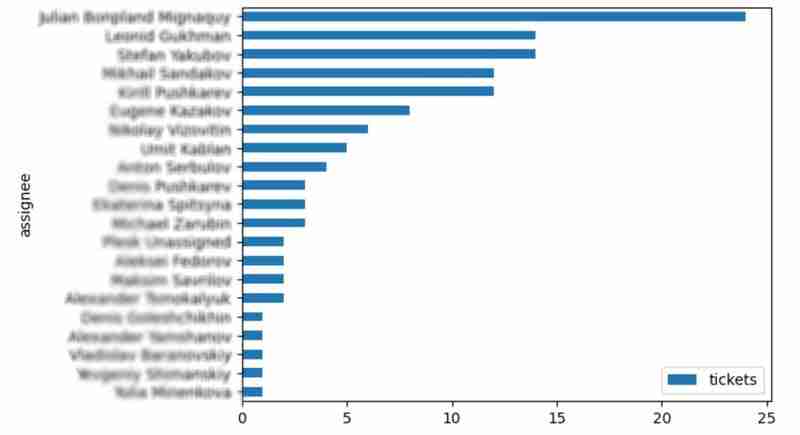
It is also interesting to see the distribution of solved problems by the assignee:
top_solvers = df.groupby('assignee').count()[['time']]
top_solvers.rename(columns={'time': 'tickets'}, inplace=True)
top_solvers.sort_values('tickets', ascending=False, inplace=True)
top_solvers.plot.barh().invert_yaxis()
It may look like the following:
Let's try to predict the amount of time required to finish all open issues. Of course, we can do it without machine learning by using simple approximation and the average time to resolve the issue. So the predicted amount of required time is the number of open issues multiplied by the average time to resolve one. For example, the median time to solve one issue is 2 hours, and we have 9 open issues, so the time required to solve them all is 18 hours (approximation). It's a good enough forecast, but we might know the speed of solving depends on the product, team, and other attributes of the issue. If we want to improve the prediction, we can utilize machine learning to solve this task.
The high-level approach looks the following:
For the first step, we will use a dataset of tickets for the last 30 weeks. Some parts here are simplified for illustrative purposes. In real life, the amount of data for learning should be big enough to make a useful model (e.g., in our case, we need thousands of issues to be analyzed).
issues = jira.search_issues(
f'project = PPS AND status IN (Resolved) AND created >= -30w',
maxResults=False,
fields='summary,issuetype,customfield_10718,customfield_10674,aggregatetimespent',
)
closed_tickets = pd.DataFrame([{
'key': issue.key,
'team': issue.fields.customfield_10718,
'product': issue.fields.customfield_10674,
'time': issue.fields.aggregatetimespent,
} for issue in issues])
closed_tickets.set_index('key', inplace=True)
closed_tickets['time'].fillna(closed_tickets['time'].median(), inplace=True)
closed_tickets
In my case, it's something around 800 tickets and only two fields for "learning": "team" and "product."
The next step is to obtain our target dataset. Why do I do it so early? I want to clean up and do "feature engineering" in one shot for both datasets. Otherwise, the mismatch between the structures can cause problems.
issues = jira.search_issues(
f'project = PPS AND status IN (Open, Reopened)',
maxResults=False,
fields='summary,issuetype,customfield_10718,customfield_10674',
)
open_tickets = pd.DataFrame([{
'key': issue.key,
'team': issue.fields.customfield_10718,
'product': issue.fields.customfield_10674,
} for issue in issues])
open_tickets.set_index('key', inplace=True)
open_tickets
Please notice we have no "time" column here because we want to predict it. Let's nullify it and combine both datasets to prepare the "features."
open_tickets['time'] = 0 tickets = pd.concat([closed_tickets, open_tickets]) tickets
Columns "team" and "product" contain string values. One of the ways of dealing with that is to transform each value into separate fields with boolean flags.
products = pd.get_dummies(tickets['product'], prefix='product')
tickets = pd.concat([tickets, products], axis=1)
tickets.drop('product', axis=1, inplace=True)
teams = pd.get_dummies(tickets['team'], prefix='team')
tickets = pd.concat([tickets, teams], axis=1)
tickets.drop('team', axis=1, inplace=True)
tickets
The result may look like the following:
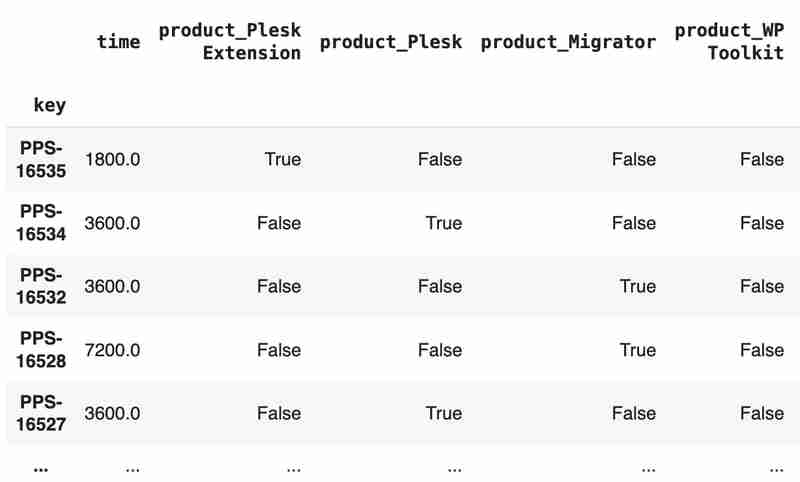
After the combined dataset preparation, we can split it back into two parts:
closed_tickets = tickets[:len(closed_tickets)] open_tickets = tickets[len(closed_tickets):][:]
Now it's time to train our model:
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeRegressor features = closed_tickets.drop(['time'], axis=1) labels = closed_tickets['time'] features_train, features_val, labels_train, labels_val = train_test_split(features, labels, test_size=0.2) model = DecisionTreeRegressor() model.fit(features_train, labels_train) model.score(features_val, labels_val)
And the final step is to use our model to make a prediction:
open_tickets['time'] = model.predict(open_tickets.drop('time', axis=1, errors='ignore'))
open_tickets['time'].sum() / 3600
The final output, in my case, is 25 hours, which is higher than our initial rough estimation. This was a basic example. However, by using ML tools, you can significantly expand your abilities to analyze JIRA data.
Sometimes, JIRA built-in tools and plugins are not sufficient for effective analysis. Moreover, many 3rd party plugins are rather expensive, costing thousands of dollars per year, and you will still struggle to make them work the way you want. However, you can easily utilize well-known data analysis tools by fetching necessary information via JIRA API and go beyond these limitations. I spent so many hours playing with various JIRA plugins in attempts to create good reports for projects, but they often missed some important parts. Building a tool or a full-featured service on top of JIRA API also often looks like overkill. That's why typical data analysis and ML tools like Jupiter, pandas, matplotlib, scikit-learn, and others may work better here.

Atas ialah kandungan terperinci Analitis JIRA dengan Panda. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perbezaan antara hibernasi tingkap dan tidur
Perbezaan antara hibernasi tingkap dan tidur
 Cara menyediakan Douyin untuk menghalang semua orang daripada melihat hasil kerja
Cara menyediakan Douyin untuk menghalang semua orang daripada melihat hasil kerja
 Apakah itu Bitcoin? Adakah ia satu penipuan?
Apakah itu Bitcoin? Adakah ia satu penipuan?
 Peranan pelayan nama domain
Peranan pelayan nama domain
 Ringkasan pengetahuan asas java
Ringkasan pengetahuan asas java
 Penggunaan C#Task
Penggunaan C#Task
 Apakah versi sistem linux yang ada?
Apakah versi sistem linux yang ada?
 Penggunaan fungsi rawak bahasa C
Penggunaan fungsi rawak bahasa C








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



