La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Ce travail a été parrainé par le membre IEEE du National Key Laboratory. d'intelligence cognitive réalisé par l'équipe de Chen Enhong et le laboratoire Arche de Noé de Huawei. L’équipe du professeur Chen Enhong est profondément engagée dans les domaines de l’exploration de données et de l’apprentissage automatique et a publié de nombreux articles dans des revues et conférences de premier plan. Les articles de Google Scholar ont été cités plus de 20 000 fois. Le Noah's Ark Laboratory est le laboratoire de Huawei engagé dans la recherche fondamentale sur l'intelligence artificielle. Il adhère au concept d'importance égale accordée à la recherche théorique et à l'innovation applicative, et s'engage à promouvoir l'innovation et le développement technologiques dans le domaine de l'intelligence artificielle. Lors de la 30e Conférence ACM sur la découverte des connaissances et l'exploration de données (KDD2024) qui s'est tenue à Barcelone, en Espagne, du 25 au 29 août, le professeur Chen Enhong du Laboratoire national clé d'intelligence cognitive de l'Université de la science et de la technologie de Chine, membre de l'IEEE, l'article « Dataset Regeneration for Sequential Recommendation » publié conjointement avec Huawei Noah a remporté le seul prix du meilleur article étudiant dans le volet recherche de la conférence 2024. Les premiers auteurs de l'article sont le professeur Chen Enhong et le professeur Lian Defu du Laboratoire national clé d'intelligence cognitive de l'Université des sciences et technologies de Chine, ainsi que le doctorant Yin Mingjia, co-supervisé par Wang Haote en tant que chercheur associé. Huawei Noah Liu Yong et le chercheur Guo Wei ont également participé aux travaux connexes. C’est la deuxième fois que les étudiants de l’équipe du professeur Chen Enhong remportent ce prix depuis sa création en 2004.

- Pautan kertas: https://arxiv.org/abs/2405.17795
- Pautan kod: https://github.com/USTC -StarTeam/DR4SR
Cadangan urutan Sistem (Pengesyoran Berurutan, SR) ialah bahagian penting dalam sistem pengesyoran moden kerana ia bertujuan untuk menangkap pilihan pengguna yang berubah-ubah. Dalam tahun-tahun kebelakangan ini, penyelidik telah membuat banyak usaha untuk meningkatkan keupayaan sistem pengesyoran jujukan. Kaedah ini biasanya mengikut paradigma berpusatkan model, iaitu membangunkan model yang berkesan berdasarkan set data tetap. Walau bagaimanapun, pendekatan ini sering mengabaikan potensi isu kualiti dan kelemahan dalam data. Untuk menyelesaikan masalah ini, kalangan akademik telah mencadangkan paradigma berpusatkan data, yang memfokuskan pada menggunakan model tetap untuk menjana set data berkualiti tinggi. Kami merangka ini sebagai masalah "pembinaan semula set data". Untuk mendapatkan data latihan terbaik, idea utama pasukan penyelidik adalah untuk mempelajari set data baharu yang secara eksplisit mengandungi corak pemindahan item. Secara khusus, mereka membahagikan proses pemodelan sistem pengesyor kepada dua peringkat: mengekstrak corak pemindahan 〈🎜〉 daripada set data asal dan mempelajari pilihan pengguna 〈🎜〉 berdasarkan 〈🎜〉. Proses ini mencabar kerana mempelajari pemetaan daripada  melibatkan dua pemetaan tersirat:
melibatkan dua pemetaan tersirat:  . Untuk tujuan ini, pasukan penyelidik meneroka kemungkinan membangunkan set data yang secara eksplisit mewakili corak pemindahan item dalam
. Untuk tujuan ini, pasukan penyelidik meneroka kemungkinan membangunkan set data yang secara eksplisit mewakili corak pemindahan item dalam  , yang membolehkan kami memisahkan secara eksplisit proses pembelajaran kepada dua peringkat, di mana
, yang membolehkan kami memisahkan secara eksplisit proses pembelajaran kepada dua peringkat, di mana  lebih mudah dipelajari . Oleh itu, tumpuan utama mereka adalah untuk mempelajari fungsi pemetaan yang cekap untuk
lebih mudah dipelajari . Oleh itu, tumpuan utama mereka adalah untuk mempelajari fungsi pemetaan yang cekap untuk  , iaitu pemetaan satu-ke-banyak. Pasukan penyelidik mentakrifkan proses pembelajaran ini sebagai paradigma penjanaan semula dataset, seperti yang ditunjukkan dalam Rajah 1, di mana "penjanaan semula" bermaksud bahawa mereka tidak memperkenalkan sebarang maklumat tambahan dan hanya bergantung pada set data asal.
, iaitu pemetaan satu-ke-banyak. Pasukan penyelidik mentakrifkan proses pembelajaran ini sebagai paradigma penjanaan semula dataset, seperti yang ditunjukkan dalam Rajah 1, di mana "penjanaan semula" bermaksud bahawa mereka tidak memperkenalkan sebarang maklumat tambahan dan hanya bergantung pada set data asal. 

 Paradigma utama, Penjanaan Semula Set Data untuk Pengesyoran Jujukan (DR4SR) , bertujuan untuk membina semula set data asal menjadi set data yang bermaklumat dan boleh digeneralisasikan. Khususnya, pasukan penyelidik mula-mula membina tugas pra-latihan untuk membolehkan penjanaan semula set data. Seterusnya, mereka mencadangkan penjana semula yang dipertingkatkan kepelbagaian untuk memodelkan hubungan satu-ke-banyak antara jujukan dan corak semasa proses penjanaan semula. Akhirnya, mereka mencadangkan strategi inferens hibrid untuk mencapai keseimbangan antara penerokaan dan eksploitasi untuk menjana set data baharu.
Paradigma utama, Penjanaan Semula Set Data untuk Pengesyoran Jujukan (DR4SR) , bertujuan untuk membina semula set data asal menjadi set data yang bermaklumat dan boleh digeneralisasikan. Khususnya, pasukan penyelidik mula-mula membina tugas pra-latihan untuk membolehkan penjanaan semula set data. Seterusnya, mereka mencadangkan penjana semula yang dipertingkatkan kepelbagaian untuk memodelkan hubungan satu-ke-banyak antara jujukan dan corak semasa proses penjanaan semula. Akhirnya, mereka mencadangkan strategi inferens hibrid untuk mencapai keseimbangan antara penerokaan dan eksploitasi untuk menjana set data baharu. Proses pembinaan semula set data adalah umum, tetapi mungkin tidak sesuai sepenuhnya untuk model sasaran tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik mencadangkan DR4SR+, proses penjanaan semula sedar model yang menyesuaikan set data mengikut ciri model sasaran. DR4SR+ memperibadikan pemarkahan dan mengoptimumkan corak dalam set data yang dibina semula melalui masalah pengoptimuman dua lapisan dan teknik pembezaan tersirat untuk meningkatkan kesan set data.
Dalam kajian ini, pasukan penyelidik mencadangkan data A- rangka kerja sentrik yang dipanggil "Penjanaan Semula Data untuk Pengesyoran Urutan" (DR4SR) bertujuan untuk membina semula set data asal menjadi set data yang bermaklumat dan boleh digeneralisasikan, seperti yang ditunjukkan dalam Rajah 2. Memandangkan proses penjanaan semula data adalah bebas daripada model sasaran, set data yang dijana semula mungkin tidak semestinya memenuhi keperluan model sasaran. Oleh itu, pasukan penyelidik memperluaskan DR4SR ke dalam versi sedar model, iaitu DR4SR+, untuk menyesuaikan set data yang dijana semula kepada model sasaran tertentu.
Pembinaan semula set data model-agnostik 2 Penjana semula untuk memudahkan penjanaan semula set data secara automatik. Walau bagaimanapun, terdapat kekurangan maklumat penyeliaan dalam set data asal untuk mempelajari penjana semula set data. Oleh itu, mereka mesti mencapai ini dengan cara pembelajaran yang diselia sendiri. Untuk tujuan ini, mereka memperkenalkan tugas pra-latihan untuk membimbing pembelajaran penjana semula yang dipertingkatkan kepelbagaian. Selepas melengkapkan pra-latihan, pasukan penyelidik selanjutnya menggunakan strategi inferens hibrid untuk menjana semula set data baharu.
Pembinaan tugas pra-latihan pembinaan semula data:
Rajah 3 Kemudian, penjana semula diperlukan untuk dapat menjana semula ke dalam corak yang sepadan . Pasukan penyelidik menandakan keseluruhan set data pra-latihan sebagai

 Penjana Semula yang menggalakkan kepelbagaian:
Penjana Semula yang menggalakkan kepelbagaian: 

Dengan tugas pra-latihan, pasukan penyelidik kini boleh pra-melatih penjana semula set data. Dalam makalah ini, mereka mengguna pakai model Transformer sebagai seni bina utama penjana semula, dan keupayaan penjanaannya telah disahkan secara meluas. Penjana semula set data terdiri daripada tiga modul: pengekod untuk mendapatkan perwakilan jujukan dalam set data asal, penyahkod untuk menjana semula corak dan modul peningkatan kepelbagaian untuk menangkap perhubungan pemetaan satu dengan banyak. Seterusnya, pasukan penyelidik akan memperkenalkan modul ini secara berasingan.
Pengekod terdiri daripada berbilang lapisan perhatian kendiri berbilang kepala (MHSA) dan rangkaian suapan ke hadapan (FFN). Bagi penyahkod, ia akan menghasilkan semula corak dalam set data X' sebagai input. Matlamat penyahkod adalah untuk membina semula corak memandangkan perwakilan jujukan yang dijana oleh pengekod Walau bagaimanapun, berbilang corak boleh diekstrak daripada jujukan . mod, yang boleh mencipta cabaran semasa latihan. Untuk menyelesaikan masalah pemetaan satu-ke-banyak ini, pasukan penyelidik seterusnya mencadangkan modul peningkatan kepelbagaian. 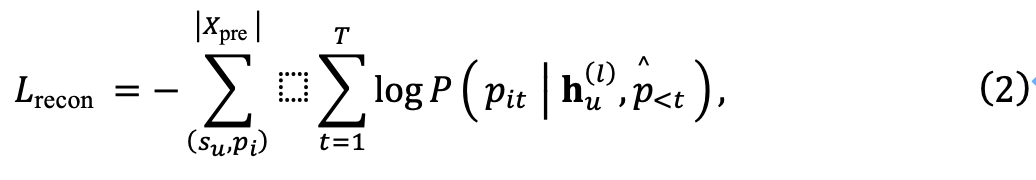
Secara khusus, pasukan penyelidik menyesuaikan secara adaptif pengaruh jujukan asal dengan menyepadukan maklumat daripada corak sasaran ke dalam peringkat penyahkodan. Mula-mula, mereka menayangkan memori yang dijana oleh pengekod ke dalam
ruang vektor yang berbeza, iaitu
. Sebaik-baiknya, corak sasaran yang berbeza harus sepadan dengan kenangan yang berbeza. Untuk tujuan ini, mereka juga memperkenalkan pengekod Transformer untuk mengekod corak sasaran dan mendapatkan
. Mereka memampatkan menjadi vektor kebarangkalian:
,
ialah kebarangkalian untuk memilih memori ke-k. Untuk memastikan setiap ruang memori dilatih sepenuhnya, kami tidak melakukan pemilihan yang sukar, sebaliknya memperoleh memori akhir melalui jumlah wajaran: 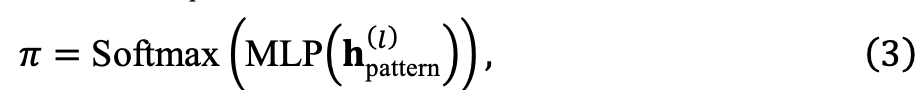
Akhirnya, ingatan yang diperoleh boleh dimanfaatkan untuk memudahkan proses penyahkodan dan secara berkesan menangkap hubungan satu-ke-banyak yang kompleks antara jujukan dan corak. Penjanaan set data sedar modelDisebabkan proses penjanaan semula dan model Sasaran sebelumnya agnostik, jadi set data yang dibina semula mungkin tidak optimum untuk model sasaran tertentu. Oleh itu, mereka memanjangkan proses penjanaan semula dataset bebas model kepada proses penjanaan semula model sedar. Untuk tujuan ini, berdasarkan penjana semula set data, mereka memperkenalkan pemperibadian set data yang menilai skor setiap sampel data dalam set data yang dijana semula. Pasukan penyelidik kemudiannya mengoptimumkan pemperibadian set data dengan lebih cekap melalui pembezaan tersirat. Matlamat pasukan penyelidik adalah untuk melatih parameter berdasarkan Peperibadian Set Data  dilaksanakan oleh MLP untuk menilai skor setiap sampel data
dilaksanakan oleh MLP untuk menilai skor setiap sampel data  W untuk model sasaran. Untuk memastikan keluasan rangka kerja, pasukan penyelidik menggunakan skor yang dikira untuk melaraskan berat kerugian latihan, yang tidak memerlukan pengubahsuaian tambahan kepada model sasaran. Mereka bermula dengan mentakrifkan kehilangan ramalan item seterusnya yang asal:
W untuk model sasaran. Untuk memastikan keluasan rangka kerja, pasukan penyelidik menggunakan skor yang dikira untuk melaraskan berat kerugian latihan, yang tidak memerlukan pengubahsuaian tambahan kepada model sasaran. Mereka bermula dengan mentakrifkan kehilangan ramalan item seterusnya yang asal: Selepas itu, fungsi kehilangan latihan untuk set data diperibadikan boleh ditakrifkan sebagai:
Pasukan penyelidik membandingkan prestasi setiap model sasaran dengan varian “DR4SR” dan “DR4SR+” untuk mengesahkan keberkesanan rangka kerja yang dicadangkan. Rajah 4
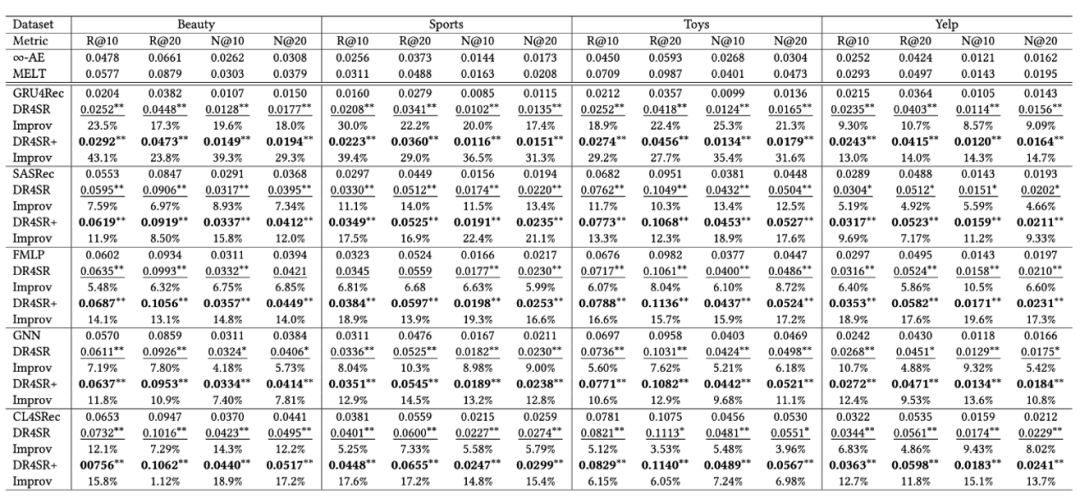
Gambar keseluruhan yang ditunjukkan dalam Prestasi Rajah 4, kesimpulan berikut boleh dibuat:DR4SR dapat membina semula set data yang bermaklumat dan boleh digunakan secara umum
Model sasaran yang berbeza memilih set data yang berbeza
- Denoising hanyalah subset masalah pembinaan semula data
-
Atas ialah kandungan terperinci Tafsiran Kertas Pelajar Terbaik KDD2024, Universiti Sains dan Teknologi China, Huawei Noah: Pengesyoran Paradigma Urutan Baharu DR4SR. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 . Untuk tujuan ini, pasukan penyelidik meneroka kemungkinan membangunkan set data yang secara eksplisit mewakili corak pemindahan item dalam
. Untuk tujuan ini, pasukan penyelidik meneroka kemungkinan membangunkan set data yang secara eksplisit mewakili corak pemindahan item dalam 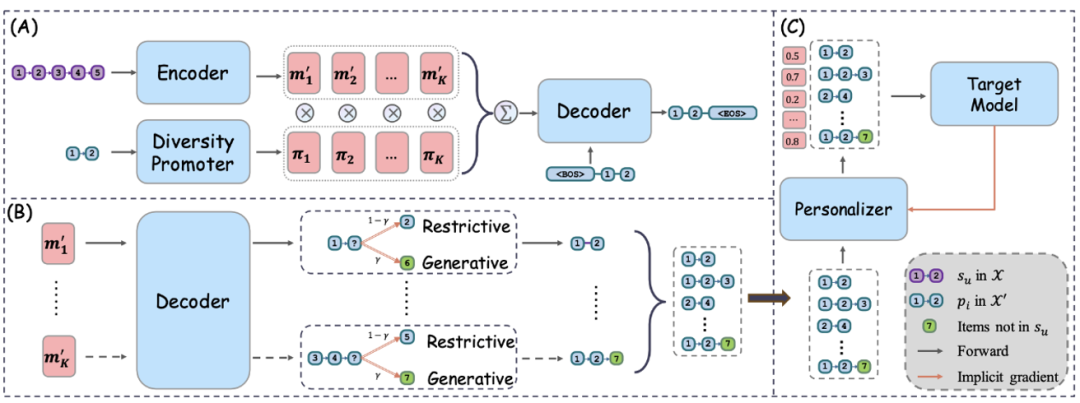



 dengan
dengan 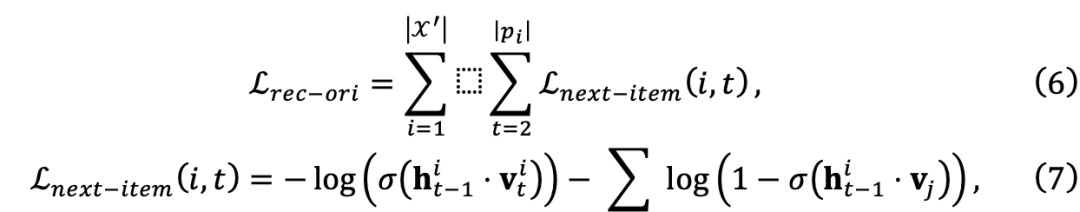
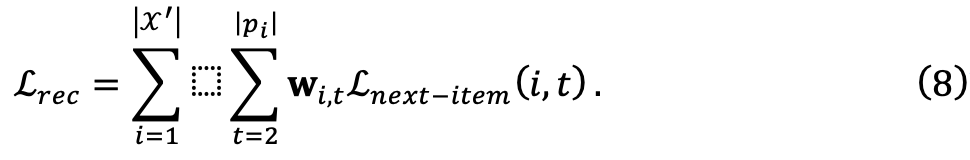
 Linux menambah kaedah sumber kemas kini
Linux menambah kaedah sumber kemas kini
 Bagaimana untuk menyelesaikan tamat masa
Bagaimana untuk menyelesaikan tamat masa
 Cara menggunakan arahan scannow
Cara menggunakan arahan scannow
 projek microsoft
projek microsoft
 Bagaimana untuk menyelesaikan masalah akses ditolak semasa boot Windows 10
Bagaimana untuk menyelesaikan masalah akses ditolak semasa boot Windows 10
 Bagaimana untuk mengimport telefon lama ke telefon baru dari telefon bimbit Huawei
Bagaimana untuk mengimport telefon lama ke telefon baru dari telefon bimbit Huawei
 Penyelesaian kepada javascript:;
Penyelesaian kepada javascript:;
 Pengenalan kepada perisian virtualisasi
Pengenalan kepada perisian virtualisasi








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



