Lajur AIxiv ialah lajur di mana kandungan akademik dan teknikal diterbitkan di tapak ini. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Ujian unit ialah pautan utama dalam proses pembangunan perisian dan digunakan terutamanya untuk Sahkan bahawa unit, fungsi atau modul yang boleh diuji terkecil dalam perisian berfungsi seperti yang diharapkan. Matlamat ujian unit adalah untuk memastikan setiap serpihan kod bebas dapat melaksanakan fungsinya dengan betul, yang sangat penting untuk meningkatkan kualiti perisian dan kecekapan pembangunan. Walau bagaimanapun, model besar dengan sendirinya tidak dapat menjana set sampel ujian liputan tinggi untuk fungsi kompleks yang sedang diuji (siklokompleksiti lebih daripada 10). Untuk menyelesaikan titik kesakitan ini, pasukan Profesor Li Ge dari Universiti Peking mencadangkan kaedah baharu untuk meningkatkan liputan kes ujian Kaedah ini menggunakan penghirisan program (Method Slicing) untuk menguraikan fungsi kompleks di bawah ujian kepada beberapa serpihan mudah berdasarkan semantik model besar menjana kes ujian untuk setiap serpihan ringkas secara berasingan. Apabila menjana satu kes ujian, model besar hanya perlu menganalisis serpihan fungsi asal yang akan diuji, yang mengurangkan kesukaran analisis dan kesukaran menjana ujian unit yang meliputi serpihan ini. Promosi ini boleh meningkatkan liputan kod set sampel ujian keseluruhan. Kertas berkaitan "HITS: Penjanaan Ujian Unit berasaskan LLM berliputan tinggi melalui Penghirisan Kaedah" baru-baru ini diterbitkan oleh ASE 2024 (pada Persidangan Antarabangsa IEEE/ACM ke-39 mengenai Kejuruteraan Perisian Automatik ) akan diterima. 
Alamat kertas: https://www.arxiv.org/pdf/2408.11324Lihat sebelah The specific kandungan penyelidikan kertas pasukan Universiti Peking: HITS menggunakan model besar untuk sharding programProgram sharding merujuk kepada membahagikan program kepada beberapa peringkat penyelesaian masalah berdasarkan semantik. Program adalah ungkapan formal penyelesaian kepada masalah. Penyelesaian masalah biasanya terdiri daripada berbilang langkah, setiap langkah sepadan dengan kepingan kod dalam program. Seperti yang ditunjukkan dalam rajah di bawah, blok warna sepadan dengan sekeping kod dan langkah untuk menyelesaikan masalah. 
HITS에서는 효율적으로 처리할 수 있는 각 코드 조각에 대한 단위 테스트 코드를 설계하기 위해 대형 모델이 필요합니다. 위 그림을 예로 들면, 그림과 같은 슬라이스를 얻을 때 HITS에서는 슬라이스 1(녹색), 슬라이스 2(파란색), 슬라이스 3(빨간색)에 대한 테스트 샘플을 각각 생성하기 위해 대형 모델이 필요합니다. 슬라이스 1에 대해 생성된 테스트 샘플은 슬라이스 2 및 슬라이스 3에 관계없이 슬라이스 1을 최대한 많이 포함해야 합니다. 다른 코드 부분에도 동일하게 적용됩니다. HITS는 두 가지 이유로 작동합니다. 첫째, 대규모 모델에서는 적용되는 코드의 양을 줄이는 것을 고려해야 합니다. 위 그림을 예로 들면, 슬라이스 3에 대한 테스트 샘플을 생성할 때 슬라이스 3의 조건부 분기만 고려하면 됩니다. 슬라이스 3의 일부 조건부 분기를 처리하려면 이 실행 경로가 슬라이스 1과 슬라이스 2의 적용 범위에 미치는 영향을 고려하지 않고 슬라이스 1과 슬라이스 2에서 실행 경로만 찾으면 됩니다. 둘째, 의미론(문제 해결 단계)을 기반으로 분할된 코드 조각은 대규모 모델이 코드 실행의 중간 상태를 파악하는 데 도움이 됩니다. 이후 코드 블록에 대한 테스트 사례를 생성하려면 이전 코드로 인해 발생한 프로그램 상태의 변경 사항을 고려해야 합니다. 코드 블록은 실제 문제 해결 단계에 따라 분할되므로 이전 코드 블록의 동작을 자연어로 설명할 수 있습니다(위 그림의 주석 참조). 현재 대부분의 대규모 언어 모델은 자연어와 프로그래밍 언어 간의 혼합 교육의 산물이므로, 좋은 자연어 요약은 대규모 모델이 코드로 인한 프로그램 상태의 변화를 보다 정확하게 파악하는 데 도움이 될 수 있습니다. HITS는 프로그램 샤딩을 위해 대형 모델을 사용합니다. 문제 해결 단계는 프로그래머의 주관적인 색감을 담아 자연어로 표현하는 경우가 많아 자연어 처리 능력이 뛰어난 대형 모델을 바로 활용 가능하다. 특히 HITS는 상황 내 학습을 사용하여 대규모 모델을 호출합니다. 팀은 실제 시나리오에서의 과거 실무 경험을 활용하여 여러 프로그램 샤딩 샘플을 수동으로 작성했습니다. 몇 가지 조정 후에 프로그램 샤딩에 대한 대규모 모델의 효과가 연구팀의 기대에 부합했습니다. 다뤄야 할 코드 조각이 주어지면, 해당 테스트 샘플을 생성하려면 다음 세 단계를 거쳐야 합니다. 1. 조각의 입력을 분석합니다. 2. 대규모 모델에 초기 테스트 샘플을 생성하도록 지시하는 프롬프트를 구성합니다. 대형 모델 자체 디버그 조정 샘플이 올바르게 실행되도록 테스트합니다. 프래그먼트의 입력을 분석합니다. 이는 후속 프롬프트 사용을 위해 프래그먼트에서 허용하는 모든 외부 입력을 추출하는 것을 의미합니다. 외부 입력은 이 조각이 적용되는 이전 조각에서 정의된 지역 변수, 테스트 중인 메서드의 형식 매개 변수, 조각 내에서 호출되는 메서드 및 외부 변수를 나타냅니다. 외부 입력의 값은 다룰 조각의 실행을 직접적으로 결정하므로 이 정보를 추출하여 대형 모델을 프롬프트하는 것은 목표한 방식으로 테스트 사례를 설계하는 데 도움이 됩니다. 연구팀은 실험을 통해 대형 모델이 외부 입력을 추출하는 능력이 뛰어나다는 사실을 발견했으며, 따라서 HITS에서는 이 작업을 완료하기 위해 대형 모델을 사용합니다. 다음으로 HITS는 대규모 모델이 테스트 샘플을 생성하도록 안내하는 일련의 사고 프롬프트를 구축합니다. 추론 단계는 다음과 같습니다. 첫 번째 단계는 외부 입력을 제공하고 다룰 코드 조각의 다양한 조건 분기의 순열과 조합을 분석하는 것입니다. 외부 입력이 충족해야 하는 속성은 무엇입니까? 예를 들어 조합 1, 문자열 a는 다음을 포함해야 합니까? 문자 'x', 정수 변수 i는 조합 2에서 음수가 아니어야 하고, 문자열 a는 비어 있지 않아야 하며, 정수 변수 i는 소수여야 합니다. 두 번째 단계에서는 이전 단계의 각 조합에 대해 실제 매개변수의 특성과 전역 변수의 설정을 포함하되 이에 국한되지 않는 해당 테스트 중인 코드가 실행되는 환경의 특성을 분석합니다. 세 번째 단계는 각 조합에 대한 테스트 샘플을 생성하는 것입니다. 연구팀은 대형 모델이 지시사항을 정확하게 이해하고 실행할 수 있도록 각 단계마다 예제를 직접 제작했습니다. 마지막으로 HITS를 사용하면 대형 모델에서 생성된 테스트 샘플을 후처리 및 자체 디버그를 통해 올바르게 실행할 수 있습니다. 대형 모델에서 생성된 테스트 샘플은 직접 사용하기 어려운 경우가 많으며, 잘못 작성된 테스트 샘플로 인해 다양한 컴파일 오류 및 런타임 오류가 발생하게 됩니다. 연구팀은 자체 관찰과 기존 논문 요약을 바탕으로 몇 가지 규칙과 일반적인 오류 복구 사례를 설계했습니다. 먼저 규칙에 따라 수정해 보세요. 규칙을 복구할 수 없는 경우에는 대형 모델의 자체 디버그 기능을 사용하여 복구하십시오. 일반적인 오류에 대한 복구 사례는 대형 모델을 참조할 수 있도록 프롬프트에 제공됩니다. 
Ilustrasi keseluruhan Hits Pasukan penyelidik menggunakan gpt-3.5-turbo sebagai model besar yang dipanggil oleh HITS, dan membandingkan HITS pada fungsi kompleks (siklokompleksiti lebih daripada 10) dalam projek Java yang telah dipelajari oleh model besar dan yang belum dipelajari kaedah ujian unit berasaskan model besar dan liputan kod dengan evosuite. Keputusan eksperimen menunjukkan bahawa HITS mempunyai peningkatan prestasi yang ketara berbanding dengan kaedah yang dibandingkan.
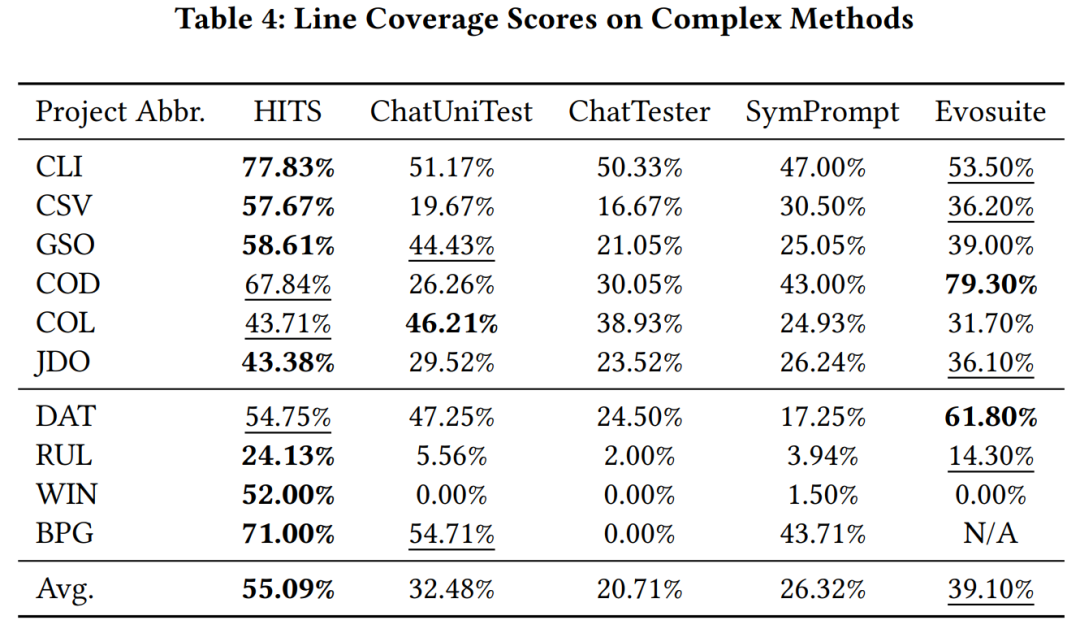


Tingkatkan liputan kod. Seperti yang ditunjukkan dalam gambar.
Dalam kes ini, sampel ujian yang dijana oleh kaedah garis dasar gagal menutup sepenuhnya serpihan kod merah dalam Slice 2. Walau bagaimanapun, kerana HITS memfokuskan pada Slice 2, ia menganalisis pembolehubah luaran yang dirujuk olehnya dan menangkap sifat bahawa "jika anda ingin menutup serpihan kod merah, 'argumen' pembolehubah perlu tidak kosong", dan membina ujian sampel berdasarkan harta ini. Berjaya mencapai liputan kod kawasan merah.
Tingkatkan liputan ujian unit, tingkatkan kebolehpercayaan dan kestabilan sistem, dan seterusnya meningkatkan kualiti perisian. HITS menggunakan eksperimen sharding program untuk membuktikan bahawa teknologi ini bukan sahaja dapat meningkatkan liputan kod keseluruhan set sampel ujian, tetapi juga mempunyai kaedah pelaksanaan yang mudah dan langsung Pada masa hadapan, ia dijangka membantu pasukan menemui dan membetulkan ralat pembangunan lebih awal dalam amalan senario kehidupan sebenar, meningkatkan kualiti penghantaran Perisian.
Atas ialah kandungan terperinci Pasukan Li Ge Universiti Peking mencadangkan kaedah baharu untuk menjana ujian tunggal untuk model besar, meningkatkan liputan ujian kod dengan ketara.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



