

Pertama sekali kita mesti memasang Go, Arahan untuk memuat turun dan memasang Go.
Kami mencipta folder baharu untuk projek itu, pindah ke direktori dan laksanakan arahan berikut:
go mod init scraper
? Perintah go mod init digunakan untuk memulakan modul Go baharu dalam direktori tempat ia dijalankan dan mencipta fail go.mod untuk menjejaki kebergantungan kod. Pengurusan pergantungan
Sekarang mari pasang Colibri:
go get github.com/gonzxlez/colibri
? Colibri ialah pakej Go yang membolehkan kami merangkak dan mengekstrak data berstruktur di web menggunakan set peraturan yang ditakrifkan dalam JSON. Repositori
Kami mentakrifkan peraturan yang akan digunakan oleh colibri untuk mengekstrak data yang kami perlukan. Dokumentasi
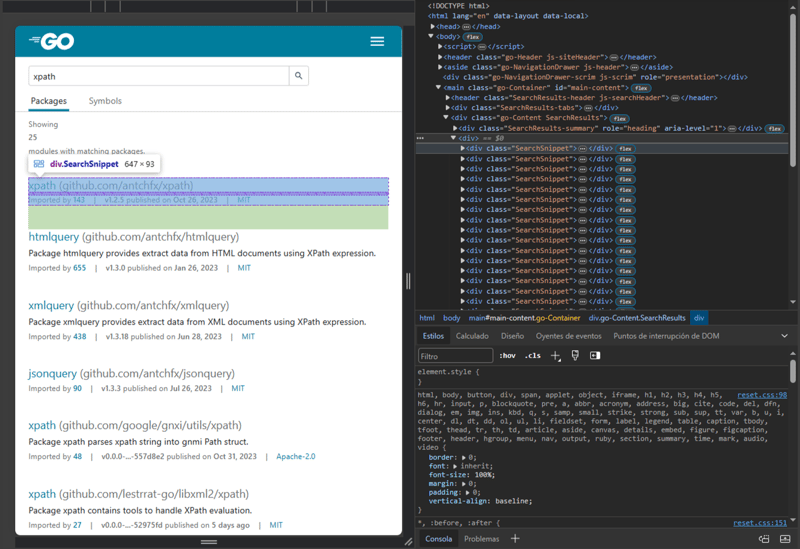
Kami akan membuat permintaan HTTP ke URL https://pkg.go.dev/search?q=xpath yang mengandungi hasil pertanyaan untuk pakej Go yang berkaitan dengan xpath dalam Pakej Go.
Menggunakan alat pembangunan yang disertakan dalam penyemak imbas web kami, kami boleh memeriksa struktur HTML halaman. Apakah alat pembangunan penyemak imbas?
<div class="SearchSnippet">
<div class="SearchSnippet-headerContainer">
<h2>
<a href="/github.com/antchfx/xpath" data-gtmc="search result" data-gtmv="0" data-test-id="snippet-title">
xpath
<span class="SearchSnippet-header-path">(github.com/antchfx/xpath)</span>
</a>
</h2>
</div>
<div class="SearchSnippet-infoLabel">
<a href="/github.com/antchfx/xpath?tab=importedby" aria-label="Go to Imported By">
<span class="go-textSubtle">Imported by </span><strong>143</strong>
</a>
<span class="go-textSubtle">|</span>
<span class="go-textSubtle">
<strong>v1.2.5</strong> published on <span data-test-id="snippet-published"><strong>Oct 26, 2023</strong></span>
</span>
<span class="go-textSubtle">|</span>
<span data-test-id="snippet-license">
<a href="/github.com/antchfx/xpath?tab=licenses" aria-label="Go to Licenses">
MIT
</a>
</span>
</div>
</div>
Serpihan struktur HTML yang mewakili hasil pertanyaan.
Kemudian kami memerlukan pemilih “pakej” yang akan menemui semua elemen div dalam HTML dengan kelas SearchSnippet, daripada elemen tersebut pemilih “ nama" akan mengambil teks elemen a di dalam elemen h2 dan pemilih "path” akan mengambil nilai atribut href bagi elemen a dalam h2 elemen . Dalam erti kata lain, “nama” akan mengambil nama pakej Go dan “path” laluan pakej :)
{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}
Kami bersedia untuk mencipta fail scraper.go, mengimport pakej yang diperlukan dan menentukan fungsi utama:
package main
import (
"encoding/json"
"fmt"
"github.com/gonzxlez/colibri"
"github.com/gonzxlez/colibri/webextractor"
)
var rawRules = `{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}`
func main() {
we, err := webextractor.New()
if err != nil {
panic(err)
}
var rules colibri.Rules
err = json.Unmarshal([]byte(rawRules), &rules)
if err != nil {
panic(err)
}
output, err := we.Extract(&rules)
if err != nil {
panic(err)
}
fmt.Println("URL:", output.Response.URL())
fmt.Println("Status code:", output.Response.StatusCode())
fmt.Println("Content-Type", output.Response.Header().Get("Content-Type"))
fmt.Println("Data:", output.Data)
}
? WebExtractor ialah antara muka lalai untuk Colibri sedia untuk mula merangkak atau mengekstrak data di web.
Menggunakan fungsi Baharu webextractor, kami menjana struktur Colibri dengan apa yang diperlukan untuk mula mengekstrak data.
Kemudian kami menukar peraturan kami dalam JSON kepada struktur Peraturan dan memanggil kaedah Ekstrak menghantar peraturan sebagai argumen.
Kami memperoleh output dan URL respons HTTP, kod status HTTP, jenis kandungan respons dan data yang diekstrak dengan pemilih dicetak pada skrin. Lihat dokumentasi struktur Output.
Kami melaksanakan arahan berikut:
go mod tidy
? Perintah go mod tidy memastikan bahawa kebergantungan dalam go.mod sepadan dengan kod sumber modul.
Akhirnya kami menyusun dan menjalankan kod kami dalam Go dengan arahan:
go run scraper.go
Dalam siaran ini, kami telah mempelajari cara melakukan Pengikisan Web dalam Go menggunakan pakej Colibri, mentakrifkan peraturan pengekstrakan dengan pemilih CSS dan XPath. Colibri muncul sebagai alat untuk mereka yang ingin mengautomasikan pengumpulan data web dalam Go. Pendekatan berasaskan peraturan dan kemudahan penggunaan menjadikannya pilihan yang menarik untuk pembangun semua peringkat pengalaman.
Ringkasnya, Web Scraping in Go ialah teknik yang berkuasa dan serba boleh yang boleh digunakan untuk mengekstrak maklumat daripada pelbagai tapak web. Adalah penting untuk menyerlahkan bahawa Pengikisan Web mesti dijalankan secara beretika, menghormati terma dan syarat tapak web dan mengelakkan membebankan pelayan mereka.
Atas ialah kandungan terperinci Web Scraping a Go. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



