

NVIDIA Memperkenalkan Llama 3.1-Nemotron-51B: Lonjakan dalam Ketepatan dan Kecekapan

NVIDIA's Llama 3.1-Nemotron-51B menetapkan penanda aras baharu dalam AI dengan ketepatan dan kecekapan yang unggul, membolehkan beban kerja yang tinggi pada satu GPU.

Model bahasa terbaharu NVIDIA, Llama 3.1-Nemotron-51B, menetapkan piawaian baharu dalam prestasi AI dengan ketepatan dan kecekapan yang luar biasa. Model ini menandakan kemajuan dalam menskalakan LLM agar muat pada satu GPU, walaupun di bawah beban kerja yang tinggi.
NVIDIA telah melancarkan model bahasa baharu, digelar Llama 3.1-Nemotron-51B, menjanjikan lonjakan dalam prestasi AI dengan ketepatan dan kecekapan yang unggul. Model ini diperoleh daripada Meta Llama-3.1-70B dan memanfaatkan pendekatan Carian Senibina Neural (NAS) novel untuk mengoptimumkan ketepatan dan kecekapan. Hebatnya, model ini boleh dimuatkan pada satu GPU NVIDIA H100, walaupun di bawah beban kerja yang tinggi, menjadikannya lebih mudah diakses dan menjimatkan kos.
Model Llama 3.1-Nemotron-51B mempunyai kelajuan inferens 2.2 kali lebih pantas sambil mengekalkan tahap ketepatan yang hampir sama berbanding dengan pendahulunya. Kecekapan ini membolehkan beban kerja 4 kali ganda lebih besar pada satu GPU semasa inferens, berkat jejak memori yang berkurangan dan seni bina yang dioptimumkan.
Salah satu cabaran dalam mengguna pakai model bahasa besar (LLM) ialah kos inferens yang tinggi. Model Llama 3.1-Nemotron-51B menangani perkara ini dengan menawarkan pertukaran seimbang antara ketepatan dan kecekapan, menjadikannya penyelesaian yang kos efektif untuk pelbagai aplikasi, daripada sistem tepi hingga pusat data awan. Keupayaan ini amat berguna untuk menggunakan berbilang model melalui pelan tindakan Kubernetes dan NIM.
Model Nemotron dioptimumkan dengan enjin TensorRT-LLM untuk prestasi inferens yang lebih tinggi dan dibungkus sebagai perkhidmatan mikro inferens NVIDIA NIM. Persediaan ini memudahkan dan mempercepatkan penggunaan model AI generatif merentas infrastruktur dipercepat NVIDIA, termasuk awan, pusat data dan stesen kerja.
Model Llama 3.1-Nemotron-51B-Instruct dibina menggunakan teknologi NAS dan kaedah latihan yang cekap, yang membolehkan penciptaan model pengubah bukan standard yang dioptimumkan untuk GPU tertentu. Pendekatan ini termasuk rangka kerja penyulingan blok untuk melatih pelbagai varian blok secara selari, memastikan inferens yang cekap dan tepat.
Pendekatan NAS NVIDIA membolehkan pengguna memilih keseimbangan optimum mereka antara ketepatan dan kecekapan. Sebagai contoh, varian Llama-3.1-Nemotron-40B-Instruct dicipta untuk mengutamakan kelajuan dan kos, mencapai peningkatan kelajuan 3.2 kali ganda berbanding model induk dengan penurunan ketepatan yang sederhana.
Model Llama 3.1-Nemotron-51B-Instruct telah ditanda aras dengan beberapa piawaian industri, mempamerkan prestasi unggulnya dalam pelbagai senario. Ia menggandakan daya pemprosesan model rujukan, menjadikannya kos efektif dalam pelbagai kes penggunaan.
Model Llama 3.1-Nemotron-51B-Instruct menawarkan satu set baharu kemungkinan untuk pengguna dan syarikat memanfaatkan model asas yang sangat tepat secara kos efektif. Keseimbangan antara ketepatan dan kecekapan menjadikannya pilihan yang menarik untuk pembina dan menyerlahkan keberkesanan pendekatan NAS, yang NVIDIA sasarkan untuk diperluaskan kepada model lain.
Atas ialah kandungan terperinci NVIDIA Memperkenalkan Llama 3.1-Nemotron-51B: Lonjakan dalam Ketepatan dan Kecekapan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1663
1663
 14
1420
52
1313
25
1266
29
1238
24
14
1420
52
1313
25
1266
29
1238
24

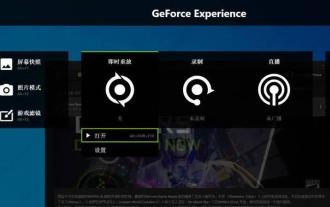 Bagaimana untuk menyelesaikan masalah bahawa kekunci pintasan rakaman skrin kad grafik NVIDIA tidak boleh digunakan?
Mar 13, 2024 pm 03:52 PM
Bagaimana untuk menyelesaikan masalah bahawa kekunci pintasan rakaman skrin kad grafik NVIDIA tidak boleh digunakan?
Mar 13, 2024 pm 03:52 PM
Kad grafik NVIDIA mempunyai fungsi rakaman skrin mereka sendiri. Sekarang biarkan tapak ini memberi pengguna pengenalan terperinci kepada masalah kekunci pintasan rakaman skrin N-kad tidak bertindak balas. Analisis masalah kekunci pintasan rakaman skrin NVIDIA tidak bertindak balas Kaedah 1, rakaman automatik 1. Rakaman automatik dan mod main semula segera Pemain boleh menganggapnya sebagai mod rakaman automatik Pertama, buka Pengalaman NVIDIA GeForce. 2. Selepas memanggil menu perisian dengan kekunci Alt+Z, klik butang Buka di bawah Main Semula Segera untuk memulakan rakaman, atau gunakan kekunci pintasan Alt+Shift+F10 untuk mula merakam.
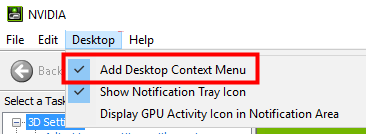 Bagaimana untuk menyelesaikan masalah panel kawalan nvidia apabila mengklik kanan dalam Win11?
Feb 20, 2024 am 10:20 AM
Bagaimana untuk menyelesaikan masalah panel kawalan nvidia apabila mengklik kanan dalam Win11?
Feb 20, 2024 am 10:20 AM
Bagaimana untuk menyelesaikan masalah panel kawalan nvidia apabila mengklik kanan dalam Win11? Ramai pengguna selalunya perlu membuka panel kawalan nvidia apabila menggunakan komputer mereka, tetapi ramai pengguna mendapati bahawa mereka tidak dapat mencari panel kawalan nvidia Jadi apa yang perlu mereka lakukan? Biarkan tapak ini dengan teliti memperkenalkan kepada pengguna penyelesaian kepada masalah bahawa tiada panel kawalan nvidia dalam klik kanan Win11. Penyelesaian kepada masalah bahawa tiada panel kawalan nvidia dalam Win11 klik kanan 1. Pastikan ia tidak tersembunyi Tekan Windows+R pada papan kekunci untuk membuka kotak jalankan baharu dan masukkan kawalan. Di penjuru kanan sebelah atas, di bawah Lihat mengikut: pilih Ikon besar. Buka Panel Kawalan NVIDIA dan tuding pada pilihan desktop untuk melihat
 Versi eksklusif untuk pasaran tanah besar China, Hong Kong dan Macau: NVIDIA akan mengeluarkan kad grafik RTX 4090D tidak lama lagi
Dec 01, 2023 am 11:34 AM
Versi eksklusif untuk pasaran tanah besar China, Hong Kong dan Macau: NVIDIA akan mengeluarkan kad grafik RTX 4090D tidak lama lagi
Dec 01, 2023 am 11:34 AM
Pada 16 November, NVIDIA sedang giat membangunkan versi baharu kad grafik RTX4090D yang direka khusus untuk tanah besar China, Hong Kong dan Macao untuk menghadapi larangan pengeluaran dan jualan tempatan. Kad grafik edisi khas ini akan membawa pelbagai ciri unik dan tweak reka bentuk untuk memenuhi keperluan dan peraturan khusus pasaran tempatan. Kad grafik ini bermaksud Chinese Year of the Dragon 2024, jadi "D" ditambahkan pada nama, yang bermaksud "Dragon". Menurut sumber industri, RTX4090D ini akan menggunakan teras GPU yang berbeza daripada RTX4090 asal, bernombor AD102-. 250. Nombor ini kelihatan lebih rendah secara berangka berbanding AD102-300/301 pada RTX4090, menunjukkan kemungkinan penurunan prestasi. Menurut N.V.
 Cyberpunk 2077 menyaksikan peningkatan prestasi sehingga 40% dengan mod pengesanan laluan dioptimumkan baharu
Aug 10, 2024 pm 09:45 PM
Cyberpunk 2077 menyaksikan peningkatan prestasi sehingga 40% dengan mod pengesanan laluan dioptimumkan baharu
Aug 10, 2024 pm 09:45 PM
Salah satu ciri menonjol Cyberpunk 2077 ialah pengesanan laluan, tetapi ia boleh menjejaskan prestasi yang teruk. Malah sistem dengan kad grafik berkebolehan yang munasabah, seperti RTX 4080 (Gigabyte AERO OC curr. $949.99 di Amazon), bergelut untuk menawarkan yang stabil
 AMD Radeon RX 7800M dalam OneXGPU 2 mengatasi prestasi GPU Komputer Riba Nvidia RTX 4070
Sep 09, 2024 am 06:35 AM
AMD Radeon RX 7800M dalam OneXGPU 2 mengatasi prestasi GPU Komputer Riba Nvidia RTX 4070
Sep 09, 2024 am 06:35 AM
OneXGPU 2 ialah eGPU pertama yang menampilkan Radeon RX 7800M, GPU yang masih belum diumumkan oleh AMD. Seperti yang didedahkan oleh One-Netbook, pengeluar penyelesaian kad grafik luaran, GPU AMD baharu adalah berdasarkan seni bina RDNA 3 dan mempunyai Navi
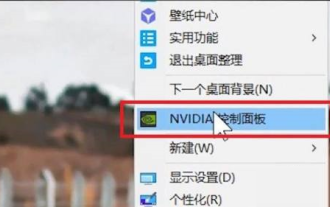 Di manakah pemproses grafik pilihan dalam panel kawalan nvidia - Pengenalan kepada lokasi pemproses grafik pilihan dalam panel kawalan nvidia
Mar 04, 2024 pm 01:50 PM
Di manakah pemproses grafik pilihan dalam panel kawalan nvidia - Pengenalan kepada lokasi pemproses grafik pilihan dalam panel kawalan nvidia
Mar 04, 2024 pm 01:50 PM
Rakan-rakan, adakah anda tahu di mana pemproses grafik pilihan panel kawalan nvidia Hari ini saya akan menerangkan lokasi pemproses grafik pilihan panel kawalan nvidia Jika anda berminat, datang dan lihat dengan editor ia boleh membantu anda. 1. Kita perlu klik kanan ruang kosong pada desktop dan buka "Panel Kawalan nvidia" (seperti yang ditunjukkan dalam gambar). 2. Kemudian masukkan "Urus Tetapan 3D" di bawah "Tetapan 3D" di sebelah kiri (seperti yang ditunjukkan dalam gambar). 3. Selepas masuk, anda boleh mencari "Preferred Graphics Processor" di sebelah kanan (seperti yang ditunjukkan dalam gambar).
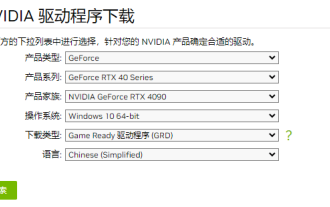 Penjelasan terperinci tentang perkara yang perlu dilakukan jika pemasangan pemacu kad grafik NVIDIA gagal
Mar 14, 2024 am 08:43 AM
Penjelasan terperinci tentang perkara yang perlu dilakukan jika pemasangan pemacu kad grafik NVIDIA gagal
Mar 14, 2024 am 08:43 AM
NVIDIA kini merupakan pengeluar kad grafik yang paling popular, dan ramai pengguna lebih suka memasang kad grafik NVIDIA pada komputer mereka. Walau bagaimanapun, anda pasti akan menghadapi beberapa masalah semasa penggunaan, seperti kegagalan pemasangan pemacu NVIDIA Bagaimana untuk menyelesaikannya? Terdapat banyak sebab untuk situasi ini. Mari kita lihat penyelesaian khusus. Langkah 1: Muat turun pemacu kad grafik terkini Anda perlu pergi ke tapak web rasmi NVIDIA untuk memuat turun pemacu terkini untuk kad grafik anda. Setelah pada halaman pemacu, pilih jenis produk anda, siri produk, keluarga produk, sistem pengendalian, jenis muat turun dan bahasa. Selepas mengklik carian, tapak web akan menanya secara automatik versi pemacu yang sesuai untuk anda. Dengan GeForceRTX4090
 Bagaimana untuk menyelesaikan tidak dapat menyambung ke nvidia
Dec 06, 2023 pm 03:18 PM
Bagaimana untuk menyelesaikan tidak dapat menyambung ke nvidia
Dec 06, 2023 pm 03:18 PM
Penyelesaian kerana tidak dapat menyambung ke nvidia: 1. Semak sambungan rangkaian 2. Semak tetapan firewall; 4. Gunakan sambungan rangkaian lain; ; 7. Mulakan semula Mulakan perkhidmatan rangkaian NVIDIA. Pengenalan terperinci: 1. Periksa sambungan rangkaian untuk memastikan komputer disambungkan ke Internet seperti biasa Anda boleh cuba memulakan semula penghala atau melaraskan tetapan rangkaian untuk memastikan anda boleh menyambung ke perkhidmatan NVIDIA , tembok api mungkin menyekat komputer, dsb.