
 pembangunan bahagian belakang
Tutorial Python
Aliran Kerja Pembelajaran Mesin Lengkap dengan Scikit-Learn: Meramalkan Harga Perumahan California
pembangunan bahagian belakang
Tutorial Python
Aliran Kerja Pembelajaran Mesin Lengkap dengan Scikit-Learn: Meramalkan Harga Perumahan California
Aliran Kerja Pembelajaran Mesin Lengkap dengan Scikit-Learn: Meramalkan Harga Perumahan California

pengenalan
Dalam artikel ini, kami akan menunjukkan aliran kerja projek pembelajaran mesin yang lengkap menggunakan Scikit-Learn. Kami akan membina model untuk meramalkan harga perumahan California berdasarkan pelbagai ciri, seperti pendapatan median, umur rumah dan purata bilangan bilik. Projek ini akan membimbing anda melalui setiap langkah proses, termasuk pemuatan data, penerokaan, latihan model, penilaian dan visualisasi hasil. Sama ada anda seorang pemula yang ingin memahami asas atau pengamal berpengalaman yang mencari penyegar semula, artikel ini akan memberikan cerapan berharga tentang aplikasi praktikal teknik pembelajaran mesin.
Projek Ramalan Harga Perumahan California
1. Pengenalan
Pasaran perumahan California terkenal dengan ciri unik dan dinamik harganya. Dalam projek ini, kami berhasrat untuk membangunkan model pembelajaran mesin untuk meramalkan harga rumah berdasarkan pelbagai ciri. Kami akan menggunakan set data perumahan California, yang merangkumi pelbagai atribut seperti pendapatan median, umur rumah, bilik purata dan banyak lagi.
2. Mengimport Perpustakaan
Dalam bahagian ini, kami akan mengimport perpustakaan yang diperlukan untuk manipulasi data, visualisasi dan membina model pembelajaran mesin kami.
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.datasets import fetch_california_housing
3. Memuatkan Set Data
Kami akan memuatkan set data Perumahan California dan mencipta DataFrame untuk menyusun data. Pembolehubah sasaran, iaitu harga rumah, akan ditambahkan sebagai lajur baharu.
# Load the California Housing dataset california = fetch_california_housing() df = pd.DataFrame(california.data, columns=california.feature_names) df['PRICE'] = california.target
4. Memilih Sampel Secara Rawak
Untuk memastikan analisis terurus, kami akan memilih 700 sampel secara rawak daripada set data untuk kajian kami.
# Randomly Selecting 700 Samples df_sample = df.sample(n=700, random_state=42)
5. Melihat Data Kami
Bahagian ini akan memberikan gambaran keseluruhan set data, memaparkan lima baris pertama untuk memahami ciri dan struktur data kami.
# Overview of the data
print("First five rows of the dataset:")
print(df_sample.head())
Output
First five rows of the dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude \
20046 1.6812 25.0 4.192201 1.022284 1392.0 3.877437 36.06
3024 2.5313 30.0 5.039384 1.193493 1565.0 2.679795 35.14
15663 3.4801 52.0 3.977155 1.185877 1310.0 1.360332 37.80
20484 5.7376 17.0 6.163636 1.020202 1705.0 3.444444 34.28
9814 3.7250 34.0 5.492991 1.028037 1063.0 2.483645 36.62
Longitude PRICE
20046 -119.01 0.47700
3024 -119.46 0.45800
15663 -122.44 5.00001
20484 -118.72 2.18600
9814 -121.93 2.78000
Paparkan Maklumat DataFrame
print(df_sample.info())
Keluaran
<class 'pandas.core.frame.DataFrame'> Index: 700 entries, 20046 to 5350 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 700 non-null float64 1 HouseAge 700 non-null float64 2 AveRooms 700 non-null float64 3 AveBedrms 700 non-null float64 4 Population 700 non-null float64 5 AveOccup 700 non-null float64 6 Latitude 700 non-null float64 7 Longitude 700 non-null float64 8 PRICE 700 non-null float64 dtypes: float64(9) memory usage: 54.7 KB
Paparkan Statistik Ringkasan
print(df_sample.describe())
Keluaran
MedInc HouseAge AveRooms AveBedrms Population \
count 700.000000 700.000000 700.000000 700.000000 700.000000
mean 3.937653 28.855714 5.404192 1.079266 1387.422857
std 2.085831 12.353313 1.848898 0.236318 1027.873659
min 0.852700 2.000000 2.096692 0.500000 8.000000
25% 2.576350 18.000000 4.397751 1.005934 781.000000
50% 3.480000 30.000000 5.145295 1.047086 1159.500000
75% 4.794625 37.000000 6.098061 1.098656 1666.500000
max 15.000100 52.000000 36.075472 5.273585 8652.000000
AveOccup Latitude Longitude PRICE
count 700.000000 700.000000 700.000000 700.000000
mean 2.939913 35.498243 -119.439729 2.082073
std 0.745525 2.123689 1.956998 1.157855
min 1.312994 32.590000 -124.150000 0.458000
25% 2.457560 33.930000 -121.497500 1.218500
50% 2.834524 34.190000 -118.420000 1.799000
75% 3.326869 37.592500 -118.007500 2.665500
max 7.200000 41.790000 -114.590000 5.000010
6. Membahagikan Set Data kepada Set Kereta Api dan Ujian
Kami akan memisahkan set data kepada ciri (X) dan pembolehubah sasaran (y) dan kemudian membahagikannya kepada set latihan dan ujian untuk latihan dan penilaian model.
# Splitting the dataset into Train and Test sets
X = df_sample.drop('PRICE', axis=1) # Features
y = df_sample['PRICE'] # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
7. Latihan Model
Dalam bahagian ini, kami akan mencipta dan melatih model Regresi Linear menggunakan data latihan untuk mempelajari hubungan antara ciri dan harga rumah.
# Creating and training the Linear Regression model lr = LinearRegression() lr.fit(X_train, y_train)
8. Menilai Model
Kami akan membuat ramalan pada set ujian dan mengira nilai Ralat Kuasa Dua (MSE) dan R kuasa dua untuk menilai prestasi model.
# Making predictions on the test set
y_pred = lr.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
print(f"\nLinear Regression Mean Squared Error: {mse}")
Keluaran
Linear Regression Mean Squared Error: 0.3699851092128846
9. Memaparkan Nilai Sebenar vs Diramalkan
Di sini, kami akan mencipta DataFrame untuk membandingkan harga rumah sebenar dengan harga ramalan yang dijana oleh model kami.
# Displaying Actual vs Predicted Values
results = pd.DataFrame({'Actual Prices': y_test.values, 'Predicted Prices': y_pred})
print("\nActual vs Predicted:")
print(results)
Output
Actual vs Predicted:
Actual Prices Predicted Prices
0 0.87500 0.887202
1 1.19400 2.445412
2 5.00001 6.249122
3 2.78700 2.743305
4 1.99300 2.794774
.. ... ...
135 1.62100 2.246041
136 3.52500 2.626354
137 1.91700 1.899090
138 2.27900 2.731436
139 1.73400 2.017134
[140 rows x
2 columns]
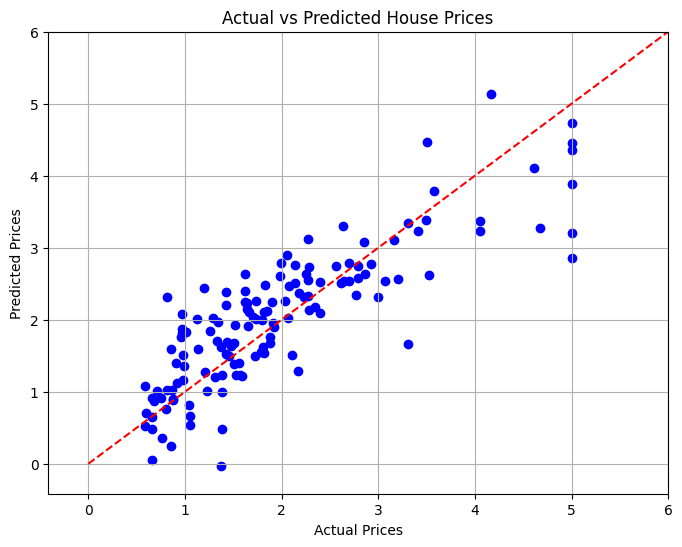
10. Menggambarkan Hasilnya
Dalam bahagian akhir, kami akan menggambarkan hubungan antara harga rumah sebenar dan ramalan menggunakan plot berselerak untuk menilai prestasi model secara visual.
# Visualizing the Results
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue')
plt.xlabel('Actual Prices')
plt.ylabel('Predicted Prices')
plt.title('Actual vs Predicted House Prices')
# Draw the ideal line
plt.plot([0, 6], [0, 6], color='red', linestyle='--')
# Set limits to minimize empty space
plt.xlim(y_test.min() - 1, y_test.max() + 1)
plt.ylim(y_test.min() - 1, y_test.max() + 1)
plt.grid()
plt.show()
Kesimpulan
Dalam projek ini, kami membangunkan model Regresi Linear untuk meramalkan harga perumahan California berdasarkan pelbagai ciri. Ralat Purata Kuasa Dua telah dikira untuk menilai prestasi model, yang memberikan ukuran kuantitatif ketepatan ramalan. Melalui visualisasi, kami dapat melihat prestasi model kami terhadap nilai sebenar.
Projek ini menunjukkan kuasa pembelajaran mesin dalam analitik hartanah dan boleh berfungsi sebagai asas untuk teknik pemodelan ramalan yang lebih maju.
Atas ialah kandungan terperinci Aliran Kerja Pembelajaran Mesin Lengkap dengan Scikit-Learn: Meramalkan Harga Perumahan California. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1677
1677
 14
1431
52
1333
25
1278
29
1257
24
14
1431
52
1333
25
1278
29
1257
24

 Python vs C: Lengkung pembelajaran dan kemudahan penggunaan
Apr 19, 2025 am 12:20 AM
Python vs C: Lengkung pembelajaran dan kemudahan penggunaan
Apr 19, 2025 am 12:20 AM
Python lebih mudah dipelajari dan digunakan, manakala C lebih kuat tetapi kompleks. 1. Sintaks Python adalah ringkas dan sesuai untuk pemula. Penaipan dinamik dan pengurusan memori automatik menjadikannya mudah digunakan, tetapi boleh menyebabkan kesilapan runtime. 2.C menyediakan kawalan peringkat rendah dan ciri-ciri canggih, sesuai untuk aplikasi berprestasi tinggi, tetapi mempunyai ambang pembelajaran yang tinggi dan memerlukan memori manual dan pengurusan keselamatan jenis.
 Pembelajaran Python: Adakah 2 jam kajian harian mencukupi?
Apr 18, 2025 am 12:22 AM
Pembelajaran Python: Adakah 2 jam kajian harian mencukupi?
Apr 18, 2025 am 12:22 AM
Adakah cukup untuk belajar Python selama dua jam sehari? Ia bergantung pada matlamat dan kaedah pembelajaran anda. 1) Membangunkan pelan pembelajaran yang jelas, 2) Pilih sumber dan kaedah pembelajaran yang sesuai, 3) mengamalkan dan mengkaji semula dan menyatukan amalan tangan dan mengkaji semula dan menyatukan, dan anda secara beransur-ansur boleh menguasai pengetahuan asas dan fungsi lanjutan Python dalam tempoh ini.
 Python vs C: Meneroka Prestasi dan Kecekapan
Apr 18, 2025 am 12:20 AM
Python vs C: Meneroka Prestasi dan Kecekapan
Apr 18, 2025 am 12:20 AM
Python lebih baik daripada C dalam kecekapan pembangunan, tetapi C lebih tinggi dalam prestasi pelaksanaan. 1. Sintaks ringkas Python dan perpustakaan yang kaya meningkatkan kecekapan pembangunan. 2. Ciri-ciri jenis kompilasi dan kawalan perkakasan meningkatkan prestasi pelaksanaan. Apabila membuat pilihan, anda perlu menimbang kelajuan pembangunan dan kecekapan pelaksanaan berdasarkan keperluan projek.
 Python vs C: Memahami perbezaan utama
Apr 21, 2025 am 12:18 AM
Python vs C: Memahami perbezaan utama
Apr 21, 2025 am 12:18 AM
Python dan C masing -masing mempunyai kelebihan sendiri, dan pilihannya harus berdasarkan keperluan projek. 1) Python sesuai untuk pembangunan pesat dan pemprosesan data kerana sintaks ringkas dan menaip dinamik. 2) C sesuai untuk prestasi tinggi dan pengaturcaraan sistem kerana menaip statik dan pengurusan memori manual.
 Yang merupakan sebahagian daripada Perpustakaan Standard Python: Senarai atau Array?
Apr 27, 2025 am 12:03 AM
Yang merupakan sebahagian daripada Perpustakaan Standard Python: Senarai atau Array?
Apr 27, 2025 am 12:03 AM
Pythonlistsarepartofthestandardlibrary, sementara
 Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python cemerlang dalam automasi, skrip, dan pengurusan tugas. 1) Automasi: Sandaran fail direalisasikan melalui perpustakaan standard seperti OS dan Shutil. 2) Penulisan Skrip: Gunakan Perpustakaan Psutil untuk memantau sumber sistem. 3) Pengurusan Tugas: Gunakan perpustakaan jadual untuk menjadualkan tugas. Kemudahan penggunaan Python dan sokongan perpustakaan yang kaya menjadikannya alat pilihan di kawasan ini.
 Python untuk pengkomputeran saintifik: rupa terperinci
Apr 19, 2025 am 12:15 AM
Python untuk pengkomputeran saintifik: rupa terperinci
Apr 19, 2025 am 12:15 AM
Aplikasi Python dalam pengkomputeran saintifik termasuk analisis data, pembelajaran mesin, simulasi berangka dan visualisasi. 1.Numpy menyediakan susunan pelbagai dimensi yang cekap dan fungsi matematik. 2. Scipy memanjangkan fungsi numpy dan menyediakan pengoptimuman dan alat algebra linear. 3. Pandas digunakan untuk pemprosesan dan analisis data. 4.Matplotlib digunakan untuk menghasilkan pelbagai graf dan hasil visual.
 Python untuk Pembangunan Web: Aplikasi Utama
Apr 18, 2025 am 12:20 AM
Python untuk Pembangunan Web: Aplikasi Utama
Apr 18, 2025 am 12:20 AM
Aplikasi utama Python dalam pembangunan web termasuk penggunaan kerangka Django dan Flask, pembangunan API, analisis data dan visualisasi, pembelajaran mesin dan AI, dan pengoptimuman prestasi. 1. Rangka Kerja Django dan Flask: Django sesuai untuk perkembangan pesat aplikasi kompleks, dan Flask sesuai untuk projek kecil atau sangat disesuaikan. 2. Pembangunan API: Gunakan Flask atau DjangorestFramework untuk membina Restfulapi. 3. Analisis Data dan Visualisasi: Gunakan Python untuk memproses data dan memaparkannya melalui antara muka web. 4. Pembelajaran Mesin dan AI: Python digunakan untuk membina aplikasi web pintar. 5. Pengoptimuman Prestasi: Dioptimumkan melalui pengaturcaraan, caching dan kod tak segerak
