

Mengikis Carian Google menyampaikan analisis SERP penting, pengoptimuman SEO dan keupayaan pengumpulan data. Alat pengikis moden menjadikan proses ini lebih cepat dan lebih dipercayai.
Salah seorang ahli komuniti kami menulis blog ini sebagai sumbangan kepada Blog Crawlee. Jika anda ingin menyumbang blog seperti ini kepada Crawlee Blog, sila hubungi kami di saluran perselisihan kami.
Dalam panduan ini, kami akan mencipta pengikis Carian Google menggunakan Crawlee untuk Python yang boleh mengendalikan kedudukan hasil dan penomboran.
Kami akan mencipta pengikis yang:
Pasang Crawlee dengan kebergantungan yang diperlukan:
pipx install crawlee[beautifulsoup,curl-impersonate]
Buat projek baharu menggunakan Crawlee CLI:
pipx run crawlee create crawlee-google-search
Apabila digesa, pilih Beautifulsoup sebagai jenis templat anda.
Navigasi ke direktori projek dan lengkapkan pemasangan:
cd crawlee-google-search poetry install
Pertama, mari kita tentukan skop pengekstrakan kami. Hasil carian Google kini termasuk peta, orang terkenal, butiran syarikat, video, soalan biasa dan banyak elemen lain. Kami akan menumpukan pada menganalisis hasil carian standard dengan kedudukan.
Inilah perkara yang akan kami keluarkan:

Mari sahkan sama ada kami boleh mengekstrak data yang diperlukan daripada kod HTML halaman, atau jika kami memerlukan analisis yang lebih mendalam atau pemaparan JS. Ambil perhatian bahawa pengesahan ini sensitif kepada teg HTML:

Berdasarkan data yang diperoleh daripada halaman, semua maklumat yang diperlukan ada dalam kod HTML. Oleh itu, kita boleh menggunakan beautifulsoup_crawler.
Medan yang akan kami ekstrak:
Mula-mula, mari buat konfigurasi perangkak.
Kami akan menggunakan CurlImpersonateHttpClient sebagai http_client kami dengan pengepala pratetap dan menyamar sebagai berkaitan dengan penyemak imbas Chrome.
Kami juga akan mengkonfigurasi ConcurrencySettings untuk mengawal keagresifan mengikis. Ini penting untuk mengelak daripada disekat oleh Google.
Jika anda perlu mengekstrak data dengan lebih intensif, pertimbangkan untuk menyediakan ProxyConfiguration.
pipx install crawlee[beautifulsoup,curl-impersonate]
Mula-mula, mari analisa kod HTML elemen yang perlu kita ekstrak:

Terdapat perbezaan yang jelas antara atribut ID boleh dibaca dan nama kelas dijana dan atribut lain. Apabila membuat pemilih untuk pengekstrakan data, anda harus mengabaikan sebarang atribut yang dijana. Walaupun anda telah membaca bahawa Google telah menggunakan teg terjana tertentu selama N tahun, anda tidak seharusnya bergantung padanya - ini mencerminkan pengalaman anda dalam menulis kod yang mantap.
Sekarang kita memahami struktur HTML, mari kita laksanakan pengekstrakan. Memandangkan perangkak kami hanya berurusan dengan satu jenis halaman, kami boleh menggunakan router.default_handler untuk memprosesnya. Dalam pengendali, kami akan menggunakan BeautifulSoup untuk mengulangi setiap hasil carian, mengekstrak data seperti tajuk, url dan text_widget sambil menyimpan hasil carian.
pipx run crawlee create crawlee-google-search
Memandangkan hasil Google bergantung pada geolokasi IP permintaan carian, kami tidak boleh bergantung pada teks pautan untuk penomboran. Kami perlu mencipta pemilih CSS yang lebih canggih yang berfungsi tanpa mengira geolokasi dan tetapan bahasa.
Parameter max_crawl_depth mengawal bilangan halaman yang perlu diimbas oleh perangkak kami. Setelah kami mempunyai pemilih yang teguh, kami hanya perlu mendapatkan pautan halaman seterusnya dan menambahkannya pada baris gilir perangkak.
Untuk menulis pemilih yang lebih cekap, pelajari asas sintaks CSS dan XPath.
cd crawlee-google-search poetry install
Memandangkan kami ingin menyimpan semua data hasil carian dalam format jadual yang mudah seperti CSV, kami hanya boleh menambah panggilan kaedah export_data sejurus selepas menjalankan perangkak:
from crawlee.beautifulsoup_crawler import BeautifulSoupCrawler
from crawlee.http_clients.curl_impersonate import CurlImpersonateHttpClient
from crawlee import ConcurrencySettings, HttpHeaders
async def main() -> None:
concurrency_settings = ConcurrencySettings(max_concurrency=5, max_tasks_per_minute=200)
http_client = CurlImpersonateHttpClient(impersonate="chrome124",
headers=HttpHeaders({"referer": "https://www.google.com/",
"accept-language": "en",
"accept-encoding": "gzip, deflate, br, zstd",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}))
crawler = BeautifulSoupCrawler(
max_request_retries=1,
concurrency_settings=concurrency_settings,
http_client=http_client,
max_requests_per_crawl=10,
max_crawl_depth=5
)
await crawler.run(['https://www.google.com/search?q=Apify'])
Sementara logik perangkak teras kami berfungsi, anda mungkin perasan bahawa keputusan kami pada masa ini kekurangan maklumat kedudukan kedudukan. Untuk melengkapkan pengikis kami, kami perlu melaksanakan penjejakan kedudukan kedudukan yang betul dengan menghantar data antara permintaan menggunakan data_pengguna dalam Permintaan.
Mari ubah suai skrip untuk mengendalikan berbilang pertanyaan dan menjejaki kedudukan kedudukan untuk analisis hasil carian. Kami juga akan menetapkan kedalaman merangkak sebagai pembolehubah peringkat atas. Mari alihkan router.default_handler ke routes.py untuk memadankan struktur projek:
@crawler.router.default_handler
async def default_handler(context: BeautifulSoupCrawlingContext) -> None:
"""Default request handler."""
context.log.info(f'Processing {context.request} ...')
for item in context.soup.select("div#search div#rso div[data-hveid][lang]"):
data = {
'title': item.select_one("h3").get_text(),
"url": item.select_one("a").get("href"),
"text_widget": item.select_one("div[style*='line']").get_text(),
}
await context.push_data(data)
Mari ubah suai pengendali untuk menambah medan pertanyaan dan order_no dan pengendalian ralat asas:
await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a")
Dan kami sudah selesai!
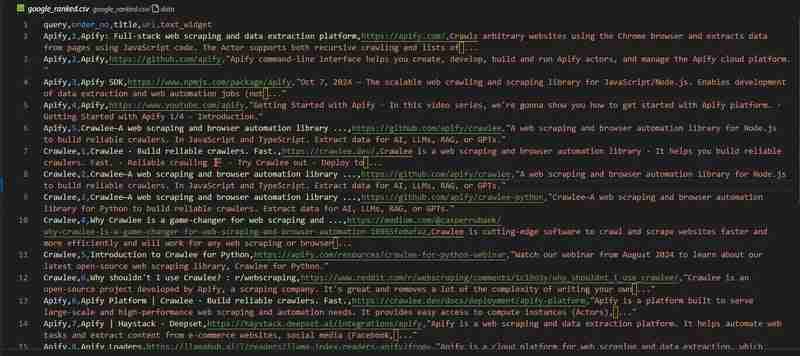
Perangkak Carian Google kami sudah sedia. Mari lihat keputusan dalam fail google_ranked.csv:
Repositori kod tersedia di GitHub
Jika anda sedang mengusahakan projek berskala besar yang memerlukan berjuta-juta titik data, seperti projek yang dipaparkan dalam artikel ini tentang analisis kedudukan Google - anda mungkin memerlukan penyelesaian siap sedia.
Pertimbangkan untuk menggunakan Pengikis Hasil Carian Google oleh pasukan Apify.
Ia menawarkan ciri penting seperti:
Anda boleh mengetahui lebih lanjut dalam blog Apify
Dalam blog ini, kami telah meneroka langkah demi langkah cara membuat perangkak Carian Google yang mengumpul data kedudukan. Cara anda menganalisis set data ini terpulang kepada anda!
Sebagai peringatan, anda boleh mencari kod projek penuh di GitHub.
Saya ingin berfikir bahawa dalam 5 tahun saya perlu menulis artikel tentang "Cara mengekstrak data daripada enjin carian terbaik untuk LLM", tetapi saya mengesyaki bahawa dalam 5 tahun artikel ini masih relevan.
Atas ialah kandungan terperinci Cara mengikis hasil carian Google dengan Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



