

reft: Pendekatan revolusioner untuk menyempurnakan LLMS
reft (perwakilan finetuning), yang diperkenalkan dalam kertas Mei 2024 Stanford, menawarkan kaedah terobosan untuk menunaikan model bahasa besar (LLMS) yang cekap. Potensinya adalah jelas, selanjutnya diketengahkan oleh eksperimen Oxen.ai pada bulan Julai 2024 yang menyempurnakan Llama3 (8B) pada satu NVIDIA A10 GPU dalam hanya 14 minit.
Tidak seperti kaedah penalaan halus parameter yang sedia ada (PEFT) seperti LORA, yang mengubah suai berat model atau input, REFT memanfaatkan kaedah Interchange Interchange (DII) yang diedarkan. Projek DII membenamkan ke dalam subspace rendah dimensi, membolehkan penalaan halus melalui subspace ini.Artikel ini pertama mengkaji algoritma PEFT yang popular (LORA, penalaan segera, penalaan awalan), kemudian menerangkan DII, sebelum menyelidiki REFT dan hasil eksperimennya.
teknik penalaan halus (PEFT) parameter 
lora (penyesuaian peringkat rendah):
diperkenalkan pada tahun 2021, kesederhanaan dan kebolehpercayaan Lora telah menjadikannya teknik utama untuk model LLM dan penyebaran yang baik. Daripada menyesuaikan semua berat lapisan, LORA menambah matriks peringkat rendah, dengan ketara mengurangkan parameter yang boleh dilatih (selalunya kurang daripada 0.3%), mempercepatkan latihan dan meminimumkan penggunaan memori GPU.
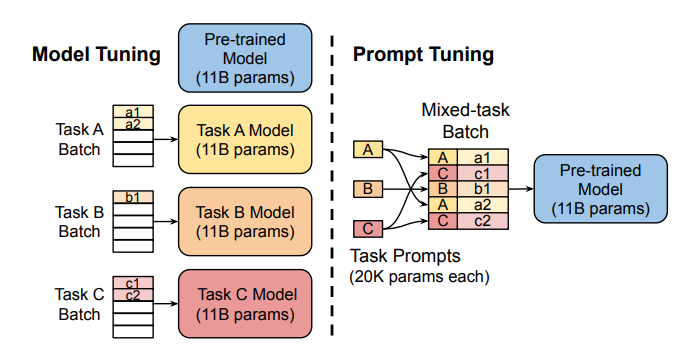
Tuning Prompt:  Kaedah ini menggunakan "soft prompts" -menghabati embeddings khusus tugas-sebagai awalan, membolehkan ramalan multi-tugas yang cekap tanpa menduplikasi model untuk setiap tugas.
Kaedah ini menggunakan "soft prompts" -menghabati embeddings khusus tugas-sebagai awalan, membolehkan ramalan multi-tugas yang cekap tanpa menduplikasi model untuk setiap tugas.
Mengatasi batasan penalaan segera pada skala, penalaan awalan menambah embeddings prompt yang boleh dilatih ke pelbagai lapisan, yang membolehkan pembelajaran khusus tugas pada tahap yang berbeza.
kekukuhan dan kecekapan Lora menjadikannya kaedah PEFT yang paling banyak digunakan untuk LLMS. Perbandingan empirikal terperinci boleh didapati dalam kertas ini .
intervensi interchange yang diedarkan (DII) 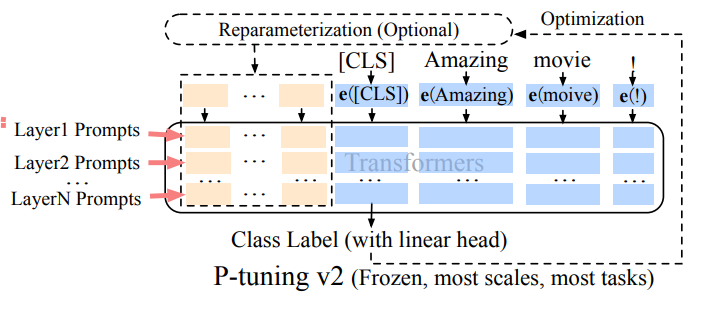
di sini .
Proses DII boleh diwakili secara matematik sebagai:
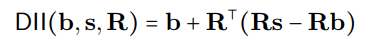
mewakili unjuran ortogonal, dan carian penjajaran yang diedarkan (DAS) mengoptimumkan subspace untuk memaksimumkan kebarangkalian output counterfactual yang dijangkakan selepas campur tangan. R
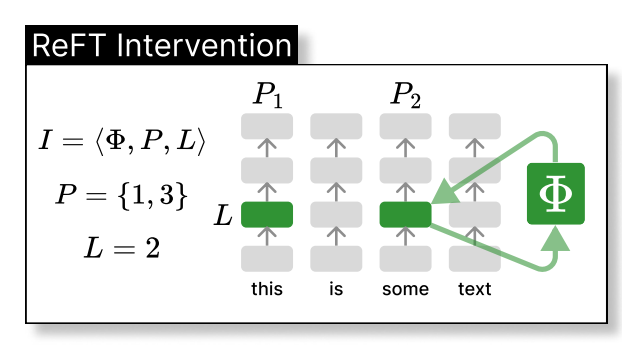 loreft (reft subspace linear rendah) memperkenalkan sumber yang diproyeksikan yang dipelajari:
loreft (reft subspace linear rendah) memperkenalkan sumber yang diproyeksikan yang dipelajari:
di mana 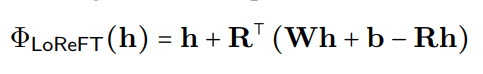 adalah perwakilan tersembunyi, dan
adalah perwakilan tersembunyi, dan
di ruang dimensi rendah yang dibesarkan oleh h. Integrasi loreft ke lapisan rangkaian saraf ditunjukkan di bawah: Rs
h R
) dilatih. 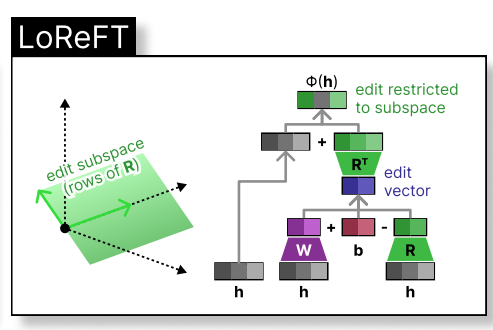
phi={R, W, b} Kertas REFT asal membentangkan eksperimen perbandingan terhadap penalaan penuh (FT), LORA, dan awalan penalaan di pelbagai tanda aras. Teknik REFT secara konsisten mengatasi kaedah sedia ada, mengurangkan parameter sekurang -kurangnya 90% semasa mencapai prestasi unggul.
Perbincangan
rayuan Reft berpunca daripada prestasi unggulnya dengan model-model keluarga Llama merentasi penanda aras yang pelbagai dan asasnya dalam abstraksi kausal, yang membantu interpretasi model. REFT menunjukkan bahawa subspace linear yang diedarkan di seluruh neuron dapat mengawal pelbagai tugas dengan berkesan, menawarkan pandangan berharga ke LLMS. 
(nota: Sila ganti https://www.php.cn/link/6c11cb78b7bbb5c22d5f5271b5494381 tempat letak dengan pautan sebenar ke kertas penyelidikan.)
Atas ialah kandungan terperinci Adakah reft semua yang kita perlukan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



