

Pembelajaran In-Context (ICL), ciri utama model bahasa besar moden (LLMS), membolehkan transformer menyesuaikan diri berdasarkan contoh-contoh dalam prompt input. Beberapa tembakan yang mendorong, menggunakan beberapa contoh tugas, dengan berkesan menunjukkan tingkah laku yang dikehendaki. Tetapi bagaimana transformer mencapai penyesuaian ini? Artikel ini meneroka mekanisme yang berpotensi di belakang ICL.

perhatian softmax dan carian jiran terdekat
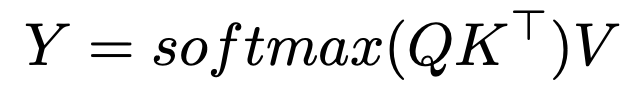 memperkenalkan parameter suhu songsang,
memperkenalkan parameter suhu songsang,
, mengubah peruntukan perhatian:
sebagai 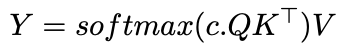 c
c
c , perhatian menyerupai pelicinan kernel Gaussian. Ini menunjukkan ICL mungkin melaksanakan algoritma jiran terdekat pada pasangan input-output. Implikasi dan penyelidikan selanjutnya
Memahami Bagaimana Transformers Belajar Algoritma (seperti jiran terdekat) Membuka pintu untuk AUTOML. Hollmann et al. Menunjukkan Latihan Pengubah pada dataset sintetik untuk mempelajari keseluruhan saluran paip AUTOML, meramalkan model optimum dan hiperparameter dari data baru dalam satu pas.Kajian baru -baru ini (Garg et al 2022, Oswald et al 2023) menghubungkan ICL Transformers ke keturunan kecerunan. Perhatian linear, menghilangkan operasi softmax:
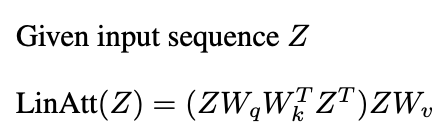
Satu lapisan perhatian linear melakukan satu langkah PGD.
Kesimpulan 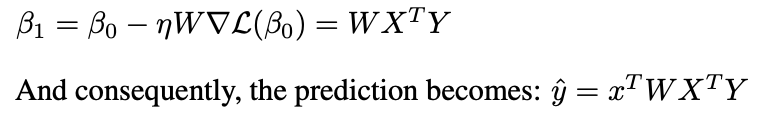
Bacaan Lanjut:
Artikel ini diilhamkan oleh Kursus Kursus Siswazah 2024 di University of Michigan. Sebarang kesilapan semata -mata penulis.
Atas ialah kandungan terperinci Matematik di belakang pembelajaran dalam konteks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Cara melaksanakan pemesejan segera pada bahagian hadapan
Cara melaksanakan pemesejan segera pada bahagian hadapan
 Perbezaan antara Sass dan kurang
Perbezaan antara Sass dan kurang
 Bagaimana untuk menyelesaikan ralat aplikasi WerFault.exe
Bagaimana untuk menyelesaikan ralat aplikasi WerFault.exe
 IIS penyelesaian ralat tidak dijangka 0x8ffe2740
IIS penyelesaian ralat tidak dijangka 0x8ffe2740
 Perbezaan antara kursus python dan kursus c+
Perbezaan antara kursus python dan kursus c+
 Adakah terdapat perbezaan besar antara bahasa c dan Python?
Adakah terdapat perbezaan besar antara bahasa c dan Python?
 Adakah OS Hongmeng Huawei Android?
Adakah OS Hongmeng Huawei Android?
 Win10 menjeda kemas kini
Win10 menjeda kemas kini








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



