

Melancarkan sihir di belakang model bahasa besar (LLMS): Eksplorasi dua bahagian
Model bahasa yang besar (LLMs) sering kelihatan ajaib, tetapi kerja dalaman mereka menghairankan sistematik. Siri dua bahagian ini menafikan LLMS, menjelaskan pembinaan, latihan, dan penghalusan mereka ke dalam sistem AI yang kami gunakan hari ini. Diilhamkan oleh video YouTube yang berwawasan (dan panjang!) Andrej Karpathy, versi ini memberikan konsep teras dalam format yang lebih mudah diakses. Walaupun video Karpathy sangat disyorkan (800,000 paparan dalam hanya 10 hari!), Ini 10 minit membaca menyuling kunci utama dari 1.5 jam pertama.
bahagian 1: dari data mentah ke model asas
Pembangunan LLM melibatkan dua fasa penting: pra-latihan dan pasca latihan.
1. Pra-Latihan: Mengajar bahasa
Sebelum menghasilkan teks, LLM mesti belajar struktur bahasa. Proses pra-latihan intensif ini melibatkan beberapa langkah:
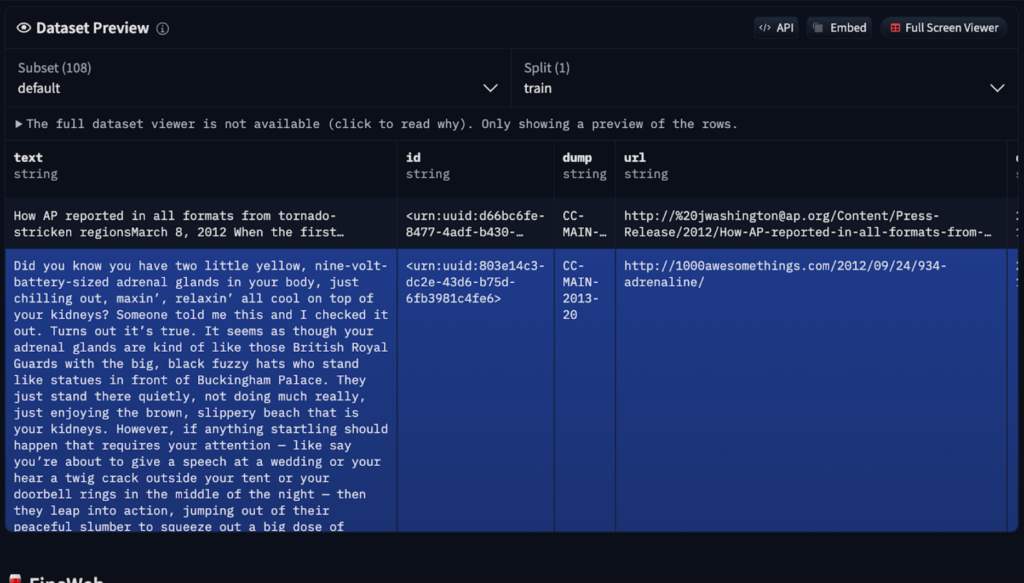
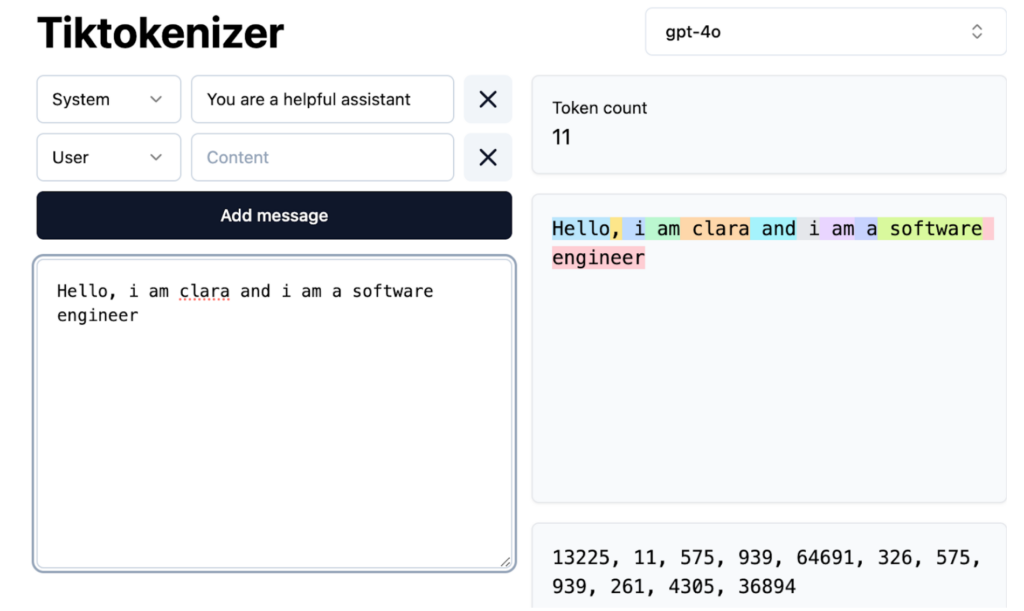
Model asas 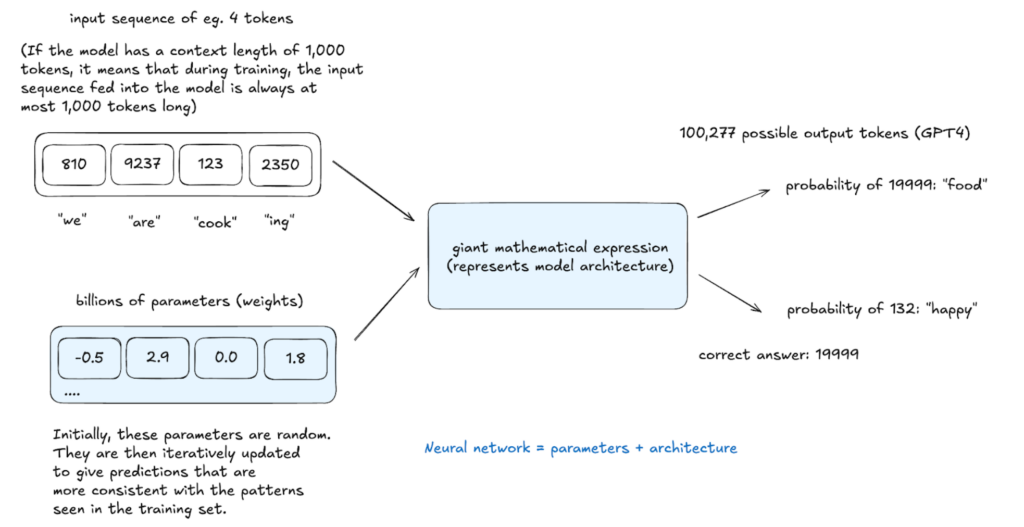 yang dihasilkan
yang dihasilkan
2. Post-Training: Memperbaiki untuk kegunaan praktikal
Model asas ditapis melalui latihan pasca menggunakan dataset yang lebih kecil dan khusus. Ini bukan pengaturcaraan eksplisit tetapi arahan tersirat melalui contoh berstruktur.
Kaedah selepas latihan termasuk:
token khas diperkenalkan untuk menggambarkan input pengguna dan respons AI.
Kesimpulan: Menjana teks
Kesimpulan, dilakukan di mana -mana peringkat, menilai pembelajaran model. Model ini memberikan kebarangkalian kepada potensi token dan sampel yang akan datang dari pengedaran ini, mewujudkan teks yang tidak jelas dalam data latihan tetapi secara statistik konsisten dengannya. Proses stokastik ini membolehkan output bervariasi dari input yang sama.
Hallucinations: Menangani Maklumat Salah
halusinasi, di mana LLM menghasilkan maklumat palsu, timbul dari sifat probabilistik mereka. Mereka tidak "tahu" fakta tetapi meramalkan urutan perkataan yang mungkin. Strategi mitigasi termasuk:
LLMS mengakses pengetahuan melalui ingatan samar-samar (corak dari pra-latihan) dan memori kerja (maklumat dalam tetingkap konteks). Sistem arahan boleh mewujudkan identiti model yang konsisten.
Kesimpulan (Bahagian 1)
Bahagian ini meneroka aspek asas pembangunan LLM. Bahagian 2 akan menyelidiki pembelajaran tetulang dan mengkaji model canggih. Soalan dan cadangan anda dialu -alukan!
Atas ialah kandungan terperinci Bagaimana LLMS Berfungsi: Pra-latihan ke Latihan Pasca, Rangkaian Neural, Hallucinations, dan Kesimpulan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pengesyoran kedudukan perisian pengesanan perkakasan komputer
Pengesyoran kedudukan perisian pengesanan perkakasan komputer
 Kaedah input simbol terbitan
Kaedah input simbol terbitan
 Nama domain tapak web percuma
Nama domain tapak web percuma
 Kedudukan sepuluh platform dagangan formal teratas
Kedudukan sepuluh platform dagangan formal teratas
 Akhiran nama fail pengubahsuaian kelompok Linux
Akhiran nama fail pengubahsuaian kelompok Linux
 kaedah pembukaan fail cdr
kaedah pembukaan fail cdr
 Pengenalan kepada kandungan kerja utama bahagian belakang
Pengenalan kepada kandungan kerja utama bahagian belakang
 laluan tambah pengenalan arahan
laluan tambah pengenalan arahan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



