

DeepSeek: Menyelam dalam ke dalam pembelajaran tetulang untuk LLMS
Kejayaan baru -baru ini DeepSeek, mencapai prestasi yang mengagumkan pada kos yang lebih rendah, menyoroti kepentingan kaedah latihan model bahasa besar (LLM). Artikel ini memberi tumpuan kepada aspek pembelajaran tetulang (RL), meneroka algoritma GRPO yang lebih baru. Kami akan meminimumkan matematik kompleks untuk menjadikannya mudah diakses, dengan mengandaikan kebiasaan asas dengan pembelajaran mesin, pembelajaran mendalam, dan LLMS.

 Pembelajaran Penguatkuasaan melibatkan ejen
Pembelajaran Penguatkuasaan melibatkan ejen
berinteraksi dengan persekitaran . Ejen itu wujud dalam state , mengambil tindakan untuk beralih ke negeri -negeri baru. Setiap tindakan mengakibatkan ganjaran dari alam sekitar, membimbing tindakan masa depan ejen. Fikirkan robot yang menavigasi labirin: Kedudukannya adalah keadaan, pergerakan adalah tindakan, dan sampai ke pintu keluar memberikan ganjaran positif. rl di llms: rupa terperinci
Dasar menentukan tindakan yang perlu diambil. Untuk LLM, ia adalah pengagihan kebarangkalian ke atas token yang mungkin, digunakan untuk mencuba token seterusnya. Latihan RL menyesuaikan parameter dasar (berat model) untuk memihak kepada token ganjaran yang lebih tinggi. Dasar ini sering diwakili sebagai:
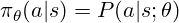
trpo (pengoptimuman dasar rantau amanah)
 TRPO menggunakan fungsi kelebihan, sama dengan fungsi kerugian dalam pembelajaran yang diawasi, tetapi berasal dari ganjaran:
TRPO menggunakan fungsi kelebihan, sama dengan fungsi kerugian dalam pembelajaran yang diawasi, tetapi berasal dari ganjaran:
TRPO memaksimumkan objektif pengganti, dikekang untuk mencegah penyimpangan dasar yang besar dari lelaran sebelumnya, memastikan kestabilan: 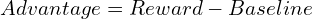
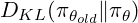 PPO, kini lebih disukai untuk LLMs seperti ChatGPT dan Gemini, memudahkan TRPO dengan menggunakan objektif pengganti yang dipotong, mengehadkan kemas kini dasar secara tersirat dan meningkatkan kecekapan pengiraan. Fungsi objektif PPO ialah:
PPO, kini lebih disukai untuk LLMs seperti ChatGPT dan Gemini, memudahkan TRPO dengan menggunakan objektif pengganti yang dipotong, mengehadkan kemas kini dasar secara tersirat dan meningkatkan kecekapan pengiraan. Fungsi objektif PPO ialah:
GRPO (pengoptimuman dasar relatif kumpulan)

Ini memudahkan proses dan sesuai untuk keupayaan LLM untuk menghasilkan pelbagai respons. GRPO juga menggabungkan istilah perbezaan KL, membandingkan dasar semasa dengan dasar rujukan. Formulasi GRPO terakhir ialah:

rujukan:
Atas ialah kandungan terperinci Latihan Model Bahasa Besar: Dari TRPO ke GRPO. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk memperlahankan video di Douyin
Bagaimana untuk memperlahankan video di Douyin
 Bagaimana untuk mencipta folder baharu dalam pycharm
Bagaimana untuk mencipta folder baharu dalam pycharm
 Apakah perisian pejabat
Apakah perisian pejabat
 Bagaimana untuk mengubah saiz gambar dalam ps
Bagaimana untuk mengubah saiz gambar dalam ps
 Bagaimana untuk menyelesaikan masalah akses ditolak semasa boot Windows 10
Bagaimana untuk menyelesaikan masalah akses ditolak semasa boot Windows 10
 Prestasi mikrokomputer terutamanya bergantung kepada
Prestasi mikrokomputer terutamanya bergantung kepada
 Perbezaan antara a++ dan ++a
Perbezaan antara a++ dan ++a
 Cara menggunakan fungsi datediff
Cara menggunakan fungsi datediff








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



