

Bolehkah O3-mini menggantikan DeepSeek-R1 untuk penalaran logik?

model penaakulan berkuasa AI mengambil dunia dengan ribut pada tahun 2025! Dengan pelancaran DeepSeek-R1 dan O3-Mini, kami telah melihat keupayaan penalaran logik yang belum pernah terjadi sebelumnya dalam chatbots AI. Dalam artikel ini, kami akan mengakses model ini melalui API mereka dan menilai kemahiran penalaran logik mereka untuk mengetahui sama ada O3-Mini dapat menggantikan DeepSeek-R1. Kami akan membandingkan prestasi mereka pada tanda aras standard serta aplikasi dunia nyata seperti menyelesaikan teka-teki logik dan juga membina permainan Tetris! Oleh itu, geser dan sertai perjalanan.
Jadual Kandungan- Perbandingan penalaran
- Tugas 1: Membina permainan Tetris
- Tugas 2: Menganalisis Ketidakseimbangan
-
- DeepSeek-R1 vs O3-Mini: Penanda Aras Penalaran Logik
- DeepSeek-R1 dan O3-Mini menawarkan pendekatan yang unik untuk pemikiran dan potongan berstruktur, menjadikannya sesuai untuk pelbagai jenis tugas menyelesaikan masalah yang kompleks. Sebelum kita bercakap tentang prestasi penanda aras mereka, mari kita mula -mula mengintip pada seni bina model -model ini.
- O3-Mini adalah model pemikiran yang paling maju OpenAI. Ia menggunakan seni bina pengubah yang padat, memproses setiap token dengan semua parameter model untuk prestasi yang kukuh tetapi penggunaan sumber yang tinggi. Sebaliknya, model paling logik DeepSeek, R1, menggunakan rangka kerja campuran-ekspertasi (MOE), mengaktifkan hanya subset parameter per input untuk kecekapan yang lebih tinggi. Ini menjadikan DeepSeek-R1 lebih berskala dan dikomputal dioptimumkan sambil mengekalkan prestasi yang kukuh.
- Ketahui lebih lanjut: Adakah O3-Mini Openai lebih baik daripada DeepSeek-R1?
Sekarang apa yang perlu kita lihat ialah bagaimana model -model ini dilakukan dalam tugas -tugas penalaran logik. Pertama, mari kita lihat prestasi mereka dalam ujian penanda aras LiveBench. -
Hasil penanda aras menunjukkan bahawa Openai's O3-mini mengalahkan DeepSeek-R1 dalam hampir semua aspek, kecuali matematik. Dengan skor purata global sebanyak 73.94 berbanding dengan 71.38 Deepseek, O3-Mini menunjukkan prestasi keseluruhan yang lebih kuat. Ia terutamanya cemerlang dalam penalaran, mencapai 89.58 berbanding DeepSeek's 83.17, mencerminkan keupayaan analisis dan penyelesaian masalah yang unggul.
Juga baca: Google Gemini 2.0 Pro vs DeepSeek-R1: Siapa yang membuat pengekodan lebih baik?
DeepSeek-R1 vs O3-Mini: Perbandingan Harga API Oleh kerana kita sedang menguji model -model ini melalui API mereka, mari kita lihat berapa banyak model model ini
| Model | Context length | Input Price | Cached Input Price | Output Price |
| o3-mini | 200k | .10/M tokens | .55/M tokens | .40/M tokens |
| deepseek-chat | 64k | .27/M tokens | .07/M tokens | .10/M tokens |
| deepseek-reasoner | 64k | .55/M tokens | .14/M tokens | .19/M tokens |
Seperti yang dilihat di dalam meja, Openai's O3-mini hampir dua kali lebih mahal seperti Deepseek R1 dari segi kos API. Ia mengenakan token $ 1.10 per juta untuk input dan $ 4.40 untuk output, sedangkan DeepSeek R1 menawarkan kadar yang lebih kos efektif $ 0.55 per juta token untuk input dan $ 2.19 untuk output, menjadikannya pilihan yang lebih mesra bajet untuk aplikasi berskala besar.
Sumber: DeepSeek-R1 | O3-Minibagaimana untuk mengakses DeepSeek-R1 dan O3-Mini melalui API
Sebelum kita melangkah ke perbandingan prestasi tangan, mari kita pelajari bagaimana untuk mengakses DeepSeek-R1 dan O3-Mini menggunakan API.
semua yang perlu anda lakukan untuk ini, mengimport perpustakaan dan kunci API yang diperlukan:
from openai import OpenAI from IPython.display import display, Markdown import time
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()with open("path_of_api_key") as file:
deepseek_api = file.read().strip()Sekarang kita mendapat akses API, mari kita bandingkan DeepSeek-R1 dan O3-mini berdasarkan keupayaan penalaran logik mereka. Untuk ini, kami akan memberikan arahan yang sama kepada kedua -dua model dan menilai respons mereka berdasarkan metrik ini:
- masa yang diambil oleh model untuk menghasilkan respons,
- Kualiti tindak balas yang dihasilkan, dan
- kos yang ditanggung untuk menghasilkan respons.
tugas 1: Membina permainan tetris
Tugas ini memerlukan model untuk melaksanakan permainan Tetris yang berfungsi sepenuhnya menggunakan Python, menguruskan logik permainan dengan cekap, pergerakan sekeping, pengesanan perlanggaran, dan rendering tanpa bergantung pada enjin permainan luaran.
prompt: "Tulis kod python untuk masalah ini: menghasilkan kod python untuk permainan tetris"
Input ke DeepSeek-R1 API
INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task1_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = messages=[
{
"role": "system",
"content": """You are a professional Programmer with a large experience ."""
},
{
"role": "user",
"content": """write a python code for this problem: generate a python code for Tetris game.
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task1_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task2_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are an expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """In the following question, assuming the given statements to be true, find which of the conclusions among given conclusions is/are definitely true and then give your answers accordingly.
Statements: H > F ≤ O ≤ L; F ≥ V < D
Conclusions:
I. L ≥ V
II. O > D
The options are:
A. Only I is true
B. Only II is true
C. Both I and II are true
D. Either I or II is true
E. Neither I nor II is true
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task2_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task3_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are a Expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """
Study the given matrix carefully and select the number from among the given options that can replace the question mark (?) in it.
__________________
| 7 | 13 | 174|
| 9 | 25 | 104|
| 11 | 30 | ? |
|_____|_____|____|
The options are:
A 335
B 129
C 431
D 100
Please mention your approch that you have taken at each step
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task3_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: .005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: .015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
# Print results
print(completion.choices[0].message)
print("----------------=Total Time Taken for task 3:----------------- ", task3_end_time - task3_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices[0].message.content))Response by DeepSeek-R1
 Anda boleh menemui respons lengkap DeepSeek-R1 di sini.
Anda boleh menemui respons lengkap DeepSeek-R1 di sini.
Kos token output:
Token input: 28 | Token Output: 3323 | Anggaran kos: $ 0.0073
output kod
input ke o3-mini api
respons oleh O3-Mini
Anda boleh menemui respons lengkap O3-Mini di sini. 
Kos token output:
Token input: 28 | Token Output: 3235 | Anggaran Kos: $ 0.014265
output kod
Analisis perbandingan
Dalam tugas ini, model -model diperlukan untuk menjana kod Tetris berfungsi yang membolehkan permainan sebenar. DeepSeek-R1 berjaya menghasilkan pelaksanaan kerja sepenuhnya, seperti yang ditunjukkan dalam video output kod. Sebaliknya, sementara kod O3-Mini muncul dengan baik, ia mengalami kesilapan semasa pelaksanaan. Akibatnya, DeepSeek-R1 mengatasi O3-Mini dalam senario ini, menyampaikan penyelesaian yang lebih dipercayai dan dimainkan.
skor: DeepSeek-R1: 1 | O3-Mini: 0
Tugas 2: Menganalisis Ketidaksamaan Relasi
Tugas ini memerlukan model untuk menganalisis ketidaksamaan hubungan dengan cekap dan bukannya bergantung pada kaedah penyortiran asas.
prompt: " Dalam soalan berikut dengan menganggap kenyataan yang diberikan menjadi benar, cari kesimpulan yang mana kesimpulan yang diberikan adalah/pasti benar dan kemudian berikan jawapan anda dengan sewajarnya.
pernyataan:h & gt; F ≤ o ≤ l; F ≥ v & lt; D
Kesimpulan: I. l ≥ v ii. O & gt; D
Pilihannya ialah:
a. Hanya saya yang benar
b. Hanya ii yang benar
c. Kedua -dua I dan II adalah benar
d. Sama ada I atau II adalah benar
e. Baik saya atau II adalah benar. "
Input ke DeepSeek-R1 API
from openai import OpenAI from IPython.display import display, Markdown import time
Token input: 136 | Token Output: 352 | Anggaran kos: $ 0.000004
Response by DeepSeek-R1
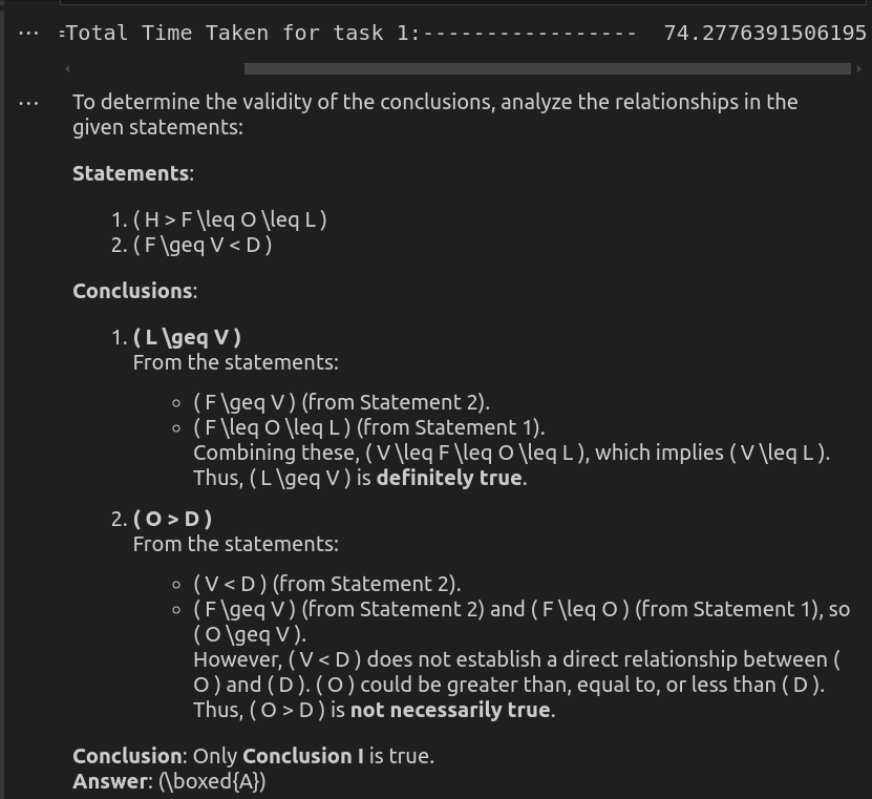 input ke o3-mini api
input ke o3-mini api
Kos token output:
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()Token input: 135 | Token Output: 423 | Anggaran kos: $ 0.002010
respons oleh O3-Mini
Analisis perbandingan 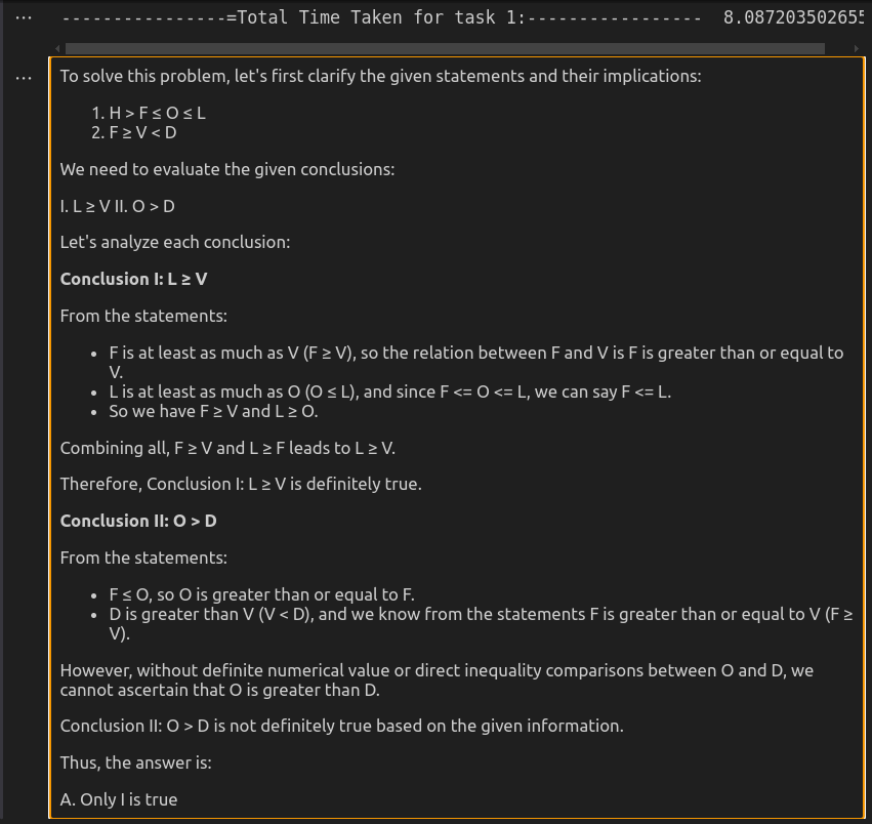
O3-Mini menyampaikan penyelesaian yang paling berkesan, memberikan respons ringkas namun tepat dalam masa yang kurang. Ia mengekalkan kejelasan sambil memastikan kekukuhan logik, menjadikannya sesuai untuk tugas -tugas pemikiran yang cepat. DeepSeek-R1, sementara sama betul, jauh lebih perlahan dan lebih jelas. Pecahan terperinci hubungan logiknya meningkatkan kebolehpecahan tetapi mungkin merasa berlebihan untuk penilaian langsung. Walaupun kedua-dua model tiba pada kesimpulan yang sama, pendekatan kelajuan dan langsung O3-Mini menjadikannya pilihan yang lebih baik untuk kegunaan praktikal.
SCORE:DeepSeek-R1: 0 | O3-Mini: 1
Tugas 3: Penalaran Logik dalam Matematik
Tugas ini mencabar model untuk mengenali corak berangka, yang mungkin melibatkan operasi aritmetik, pendaraban, atau gabungan peraturan matematik. Daripada mencari kekerasan, model mesti menggunakan pendekatan berstruktur untuk menyimpulkan logik tersembunyi dengan cekap.
prompt: " Kaji matriks yang diberikan dengan berhati -hati dan pilih nombor dari antara pilihan yang dapat menggantikan tanda tanya (?) Di dalamnya.
| 7 | 13 | 174 |
| 9 | 25 | 104 |
| 11 | 30 | ? |
| _____ | ____ | ___ |
Pilihannya ialah:
A 335
b 129
c 431
d 100
Sila nyatakan pendekatan anda yang telah anda ambil pada setiap langkah. " Input ke DeepSeek-R1 API
Kos token output:
from openai import OpenAI from IPython.display import display, Markdown import time
Token input: 134 | Token Output: 274 | Anggaran kos: $ 0.000003
Response by DeepSeek-R1
input ke o3-mini api 
Kos token output:
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()Token input: 134 | Token Output: 736 | Anggaran kos: $ 0.003386
output oleh O3-Mini



 (nombor 1)^3- (nombor ke -2)^2 = nombor ke -3
(nombor 1)^3- (nombor ke -2)^2 = nombor ke -3
Menggunakan corak ini:
baris 1: 7^3 - 13^2 = 343 - 169 = 174baris 2: 9^3 - 25^2 = 729 - 625 = 104
baris 3: 11^3 - 30^2 = 1331 - 900 = 431
- Oleh itu, jawapan yang betul ialah 431.
- DeepSeek-R1 mengenal pasti dan menggunakan corak ini, yang membawa kepada jawapan yang betul. Pendekatan berstrukturnya memastikan ketepatan, walaupun ia mengambil masa yang lebih lama untuk mengira hasilnya. O3-Mini, sebaliknya, gagal menubuhkan corak yang konsisten. Ia mencuba pelbagai operasi, seperti pendaraban, tambahan, dan eksponensi, tetapi tidak sampai pada jawapan yang pasti. Ini mengakibatkan tindak balas yang tidak jelas dan tidak betul. Secara keseluruhannya, DeepSeek-R1 mengatasi O3-Mini dalam penalaran dan ketepatan logik, manakala O3-mini bergelut kerana pendekatan yang tidak konsisten dan tidak berkesan.
- skor:
- DeepSeek-R1: 1 | O3-Mini: 0
Skor Akhir: DeepSeek-R1: 2 | O3-Mini: 1
ringkasan perbandingan penalaran logik
| Task No. | Task Type | Model | Performance | Time Taken (seconds) | Cost |
| 1 | Code Generation | DeepSeek-R1 | ✅ Working Code | 606.45 | .0073 |
| o3-mini | ❌ Non-working Code | 99.73 | .014265 | ||
| 2 | Alphabetical Reasoning | DeepSeek-R1 | ✅ Correct | 74.28 | .000004 |
| o3-mini | ✅ Correct | 8.08 | .002010 | ||
| 3 | Mathematical Reasoning | DeepSeek-R1 | ✅ Correct | 450.53 | .000003 |
| o3-mini | ❌ Wrong Answer | 12.37 | .003386 |
Kesimpulan
Seperti yang kita lihat dalam perbandingan ini, kedua-dua DeepSeek-R1 dan O3-Mini menunjukkan kekuatan unik yang memenuhi keperluan yang berbeza. DeepSeek-R1 cemerlang dalam tugas-tugas yang didorong oleh ketepatan, terutamanya dalam penalaran matematik dan penjanaan kod kompleks, menjadikannya calon yang kuat untuk aplikasi yang memerlukan kedalaman logik dan ketepatan. Walau bagaimanapun, satu kelemahan yang ketara adalah masa tindak balas yang lebih perlahan, sebahagiannya disebabkan oleh isu penyelenggaraan pelayan yang berterusan yang telah menjejaskan kebolehaksesannya. Sebaliknya, O3-Mini menawarkan masa tindak balas yang lebih cepat, tetapi kecenderungannya menghasilkan hasil yang salah mengehadkan kebolehpercayaannya untuk tugas-tugas penalaran yang tinggi.
Analisis ini menggariskan perdagangan antara kelajuan dan ketepatan dalam model bahasa. Walaupun O3-Mini mungkin berguna untuk aplikasi yang cepat, berisiko rendah, DeepSeek-R1 menonjol sebagai pilihan yang unggul untuk tugas-tugas yang berintensifkan, dengan syarat masalah latensi ditangani. Oleh kerana model AI terus berkembang, menarik keseimbangan antara kecekapan prestasi dan ketepatan akan menjadi kunci untuk mengoptimumkan aliran kerja yang didorong oleh AI di pelbagai domain.
Juga baca: Bolehkah O3-Mini Openai mengalahkan Claude Sonnet 3.5 dalam pengekodan?
Soalan LazimQ1. Apakah perbezaan utama antara DeepSeek-R1 dan O3-Mini? a. DeepSeek-R1 cemerlang dalam penalaran matematik dan penjanaan kod kompleks, menjadikannya sesuai untuk aplikasi yang memerlukan kedalaman dan ketepatan logik. O3-Mini, sebaliknya, jauh lebih cepat tetapi sering mengorbankan ketepatan, yang membawa kepada output yang tidak betul sekali-sekala.
Q2. Adakah DeepSeek-R1 lebih baik daripada O3-Mini untuk tugas pengekodan?
a. O3-Mini paling sesuai untuk aplikasi berisiko rendah, bergantung kepada kelajuan, seperti chatbots, penjanaan teks kasual, dan pengalaman AI interaktif. Walau bagaimanapun, untuk tugas yang memerlukan ketepatan yang tinggi, DeepSeek-R1 adalah pilihan pilihan.
Atas ialah kandungan terperinci Bolehkah O3-mini menggantikan DeepSeek-R1 untuk penalaran logik?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
Artikel ini membandingkan chatbots AI seperti Chatgpt, Gemini, dan Claude, yang memberi tumpuan kepada ciri -ciri unik mereka, pilihan penyesuaian, dan prestasi dalam pemprosesan bahasa semula jadi dan kebolehpercayaan.
 10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
Hei ada, pengekodan ninja! Apa tugas yang berkaitan dengan pengekodan yang anda telah merancang untuk hari itu? Sebelum anda menyelam lebih jauh ke dalam blog ini, saya ingin anda memikirkan semua kesengsaraan yang berkaitan dengan pengekodan anda-lebih jauh menyenaraikan mereka. Selesai? - Let ’
 Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Artikel ini membincangkan pembantu penulisan AI terkemuka seperti Grammarly, Jasper, Copy.ai, WriteSonic, dan Rytr, yang memberi tumpuan kepada ciri -ciri unik mereka untuk penciptaan kandungan. Ia berpendapat bahawa Jasper cemerlang dalam pengoptimuman SEO, sementara alat AI membantu mengekalkan nada terdiri
 Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Memo CEO Shopify Tobi Lütke baru -baru ini dengan berani mengisytiharkan penguasaan AI sebagai harapan asas bagi setiap pekerja, menandakan peralihan budaya yang signifikan dalam syarikat. Ini bukan trend seketika; Ini adalah paradigma operasi baru yang disatukan ke p
 AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
Landskap AI minggu ini: Badai kemajuan, pertimbangan etika, dan perdebatan pengawalseliaan. Pemain utama seperti Openai, Google, Meta, dan Microsoft telah melepaskan kemas kini, dari model baru yang terobosan ke peralihan penting di LE
 Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Artikel ini mengulas penjana suara AI atas seperti Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, dan Descript, memberi tumpuan kepada ciri -ciri mereka, kualiti suara, dan kesesuaian untuk keperluan yang berbeza.
