

Tutorial ini menunjukkan penalaan halus model Llama 3.1-8b-it untuk analisis sentimen kesihatan mental. Kami akan menyesuaikan model untuk meramalkan status kesihatan mental pesakit dari data teks, menggabungkan penyesuai dengan model asas, dan menggunakan model lengkap pada hab muka yang memeluk. secara penting, ingat bahawa pertimbangan etika adalah yang paling penting apabila menggunakan AI dalam penjagaan kesihatan; Contoh ini adalah untuk tujuan ilustrasi sahaja.
Kami akan meliputi mengakses model Llama 3.1 melalui Kaggle, menggunakan Perpustakaan Transformers untuk kesimpulan, dan proses penalaan halus itu sendiri. Pemahaman terlebih dahulu mengenai penalaan halus LLM (lihat "Panduan Pengenalan kepada LLMS Fine-Tuning") bermanfaat.

imej oleh pengarang
Memahami llama 3.1
llama 3.1, Model Bahasa Besar Berbilang Bahasa Meta (LLM), cemerlang dalam pemahaman bahasa dan generasi. Tersedia dalam versi parameter 8B, 70B, dan 405B, ia dibina di atas seni bina auto-regresif dengan transformer yang dioptimumkan. Dilatih dengan pelbagai data awam, ia menyokong lapan bahasa dan menawarkan panjang konteks 128k. Lesen komersilnya mudah diakses, dan ia melebihi beberapa pesaing dalam pelbagai tanda aras.
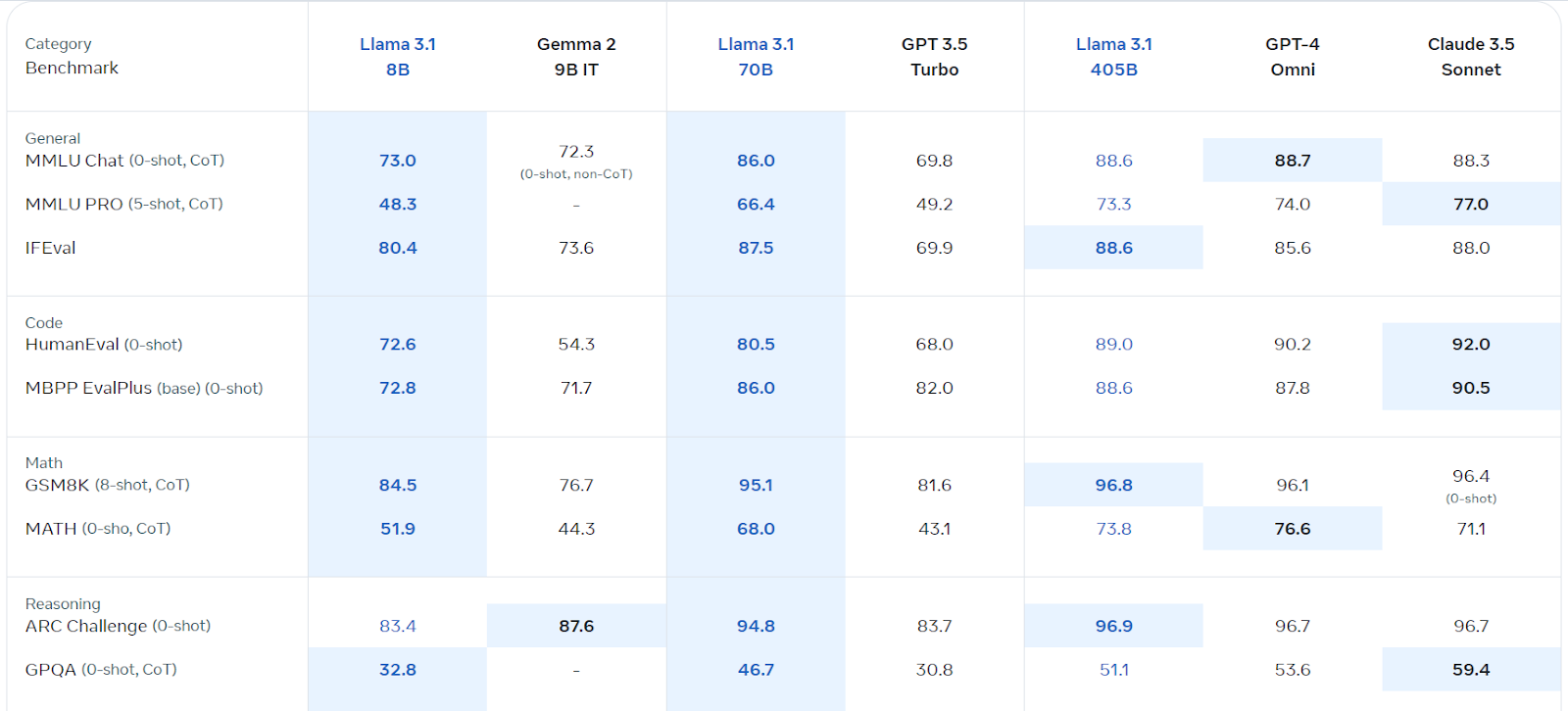
mengakses dan menggunakan llama 3.1 di Kaggle
Kami akan memanfaatkan GPU/TPU percuma Kaggle. Ikuti langkah -langkah ini:
Daftar di Meta.com (menggunakan e -mel Kaggle anda).
%pip install -U transformers accelerate Muatkan model dan tokenizer: from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model, return_dict=True, low_cpu_mem_usage=True, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.float16, device_map="auto")messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])  Fine-Tuning Llama 3.1 untuk Klasifikasi Kesihatan Mental
Fine-Tuning Llama 3.1 untuk Klasifikasi Kesihatan Mental
Persediaan:
Mulakan notebook Kaggle baru dengan Llama 3.1, pasang pakej yang diperlukan (,
Pemprosesan Data: Muatkan dataset, bersihkannya (mengeluarkan kategori samar -samar: "bunuh diri," "tekanan," "gangguan keperibadian"), shuffle, dan berpecah kepada latihan, penilaian, dan set ujian (menggunakan 3000 sampel untuk kecekapan). Buat petunjuk menggabungkan pernyataan dan label.
Model Loading: Muatkan model Llama-3.1-8B-Instruct menggunakan kuantisasi 4-bit untuk kecekapan memori. Muatkan tokenizer dan tetapkan id token pad.
Penilaian pra-penalaan: Buat fungsi untuk meramalkan label dan menilai prestasi model (ketepatan, laporan klasifikasi, matriks kekeliruan). Menilai prestasi asas model sebelum penalaan halus.
Fine-penune: Konfigurasi LORA menggunakan parameter yang sesuai. Sediakan hujah latihan (menyesuaikan seperti yang diperlukan untuk persekitaran anda). Melatih model menggunakan SFTTrainer. Pantau kemajuan menggunakan berat & bias.
penilaian pasca-penalaan: menilai semula prestasi model selepas penalaan halus.
PeftModel.from_pretrained() ingat untuk menggantikan ruang letak seperti model.merge_and_unload() dengan laluan fail sebenar anda. Kod lengkap dan penjelasan terperinci boleh didapati dalam respons asal, lebih lama. Versi pekat ini menyediakan gambaran keseluruhan peringkat tinggi dan coretan kod utama. Sentiasa mengutamakan pertimbangan etika semasa bekerja dengan data sensitif.
Atas ialah kandungan terperinci Penalaan Llama 3.1 untuk klasifikasi teks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 perintah biasa iscsiadm
perintah biasa iscsiadm
 Pengenalan kepada nama domain peringkat atas yang biasa digunakan
Pengenalan kepada nama domain peringkat atas yang biasa digunakan
 Bagaimana untuk kembali ke halaman utama dari subhalaman html
Bagaimana untuk kembali ke halaman utama dari subhalaman html
 Kumpulan benang Python dan prinsip dan kegunaannya
Kumpulan benang Python dan prinsip dan kegunaannya
 Bagaimana untuk menetapkan gambar latar belakang ppt
Bagaimana untuk menetapkan gambar latar belakang ppt
 Bagaimana untuk menyemak status pelayan
Bagaimana untuk menyemak status pelayan
 Apakah alamat laman sesawang Ouyi?
Apakah alamat laman sesawang Ouyi?
 Apakah sifat-sifat tag?
Apakah sifat-sifat tag?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



