

Snowpark: Pembelajaran Mesin Dalam Data dengan Snowflake
Pembelajaran mesin tradisional sering melibatkan pemindahan dataset besar dari pangkalan data untuk memodelkan persekitaran latihan. Ini semakin tidak cekap dengan dataset besar hari ini. Snowflake Snowpark menangani ini dengan membolehkan pemprosesan dalam data. Snowpark menyediakan perpustakaan dan runtime untuk melaksanakan kod (Python, Java, Scala) secara langsung dalam awan Snowflake, meminimumkan pergerakan data dan meningkatkan keselamatan.
mengapa memilih Snowpark?
Snowpark menawarkan beberapa kelebihan utama:
Bermula: Panduan langkah demi langkah
Tutorial ini menunjukkan membina model hyperparameter yang menggunakan snowpark.
Buat persekitaran conda dan pasang perpustakaan yang diperlukan (snowflake-snowpark-python, pandas, pyarrow, numpy). matplotlib
seaborn
ipykernel
).
config.py
.gitignore
Memahami DataFrames Snowpark
Bila Menggunakan Snowpark DataFrames:
Gunakan data snowpark untuk dataset besar di mana memindahkan data ke mesin tempatan anda tidak praktikal. Untuk dataset yang lebih kecil, panda mungkin mencukupi. Kaedah
membolehkan penukaran antara Snowpark dan Pandas DataFrames. Kaedahmenyediakan alternatif untuk melaksanakan pertanyaan SQL secara langsung.
fungsi transformasi data snowpark: to_pandas()
Fungsi transformasi Snowpark (diimport sebagai F dari snowflake.snowpark.functions) menyediakan antara muka yang kuat untuk manipulasi data. Fungsi ini digunakan dengan kaedah .select(), .filter(), dan .with_column().
Analisis Data Exploratory (EDA):
EDA boleh dilakukan dengan data sampling dari data snowpark, menukarnya ke data Pandas, dan menggunakan perpustakaan visualisasi seperti Matplotlib dan Seaborn. Sebagai alternatif, pertanyaan SQL boleh menjana data untuk visualisasi.
Latihan Model Pembelajaran Mesin:
Pembersihan Data: Pastikan jenis data betul dan mengendalikan sebarang keperluan pra -proses (mis., Menamakan semula lajur, jenis data pemutus, ciri teks pembersihan).
Preprocessing: Gunakan Snowflake ML Pipeline dengan OrdinalEncoder dan StandardScaler untuk data preprocess. Simpan saluran paip menggunakan joblib.
Latihan Model: Melatih model XGBOOST (XGBRegressor) menggunakan data yang telah diproses. Pecahkan data ke dalam latihan dan ujian ujian menggunakan random_split().
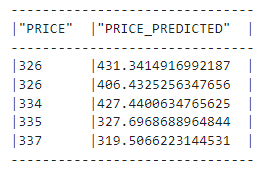
Penilaian model: menilai model menggunakan metrik seperti RMSE (mean_squared_error dari snowflake.ml.modeling.metrics).
HyperParameter Tuning: Gunakan RandomizedSearchCV untuk mengoptimumkan hyperparameters model.
Penjimatan Model: Simpan model terlatih dan metadatanya ke pendaftaran model Snowflake menggunakan kelas Registry.
Kesimpulan: Melaksanakan kesimpulan pada data baru menggunakan model yang disimpan dari pendaftaran.
Kesimpulan:
Snowpark menyediakan cara yang kuat dan cekap untuk melakukan pembelajaran mesin dalam data. Penilaian malasnya, integrasi dengan perpustakaan yang biasa, dan pendaftaran model menjadikannya alat yang berharga untuk mengendalikan dataset yang besar. Ingatlah untuk berunding dengan panduan pemaju API Snowpark dan ML untuk ciri -ciri dan fungsi yang lebih canggih.












Nota: URL imej dipelihara dari input. Pemformatan diselaraskan untuk kebolehbacaan dan aliran yang lebih baik. Butiran teknikal dikekalkan, tetapi bahasa dibuat lebih ringkas dan dapat diakses oleh khalayak yang lebih luas.
Atas ialah kandungan terperinci Snowflake Snowpark: Pengenalan Komprehensif. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyalakan telefon Xiaomi
Bagaimana untuk menyalakan telefon Xiaomi
 Bagaimana untuk memusatkan div dalam css
Bagaimana untuk memusatkan div dalam css
 Bagaimana untuk membuka fail rar
Bagaimana untuk membuka fail rar
 Kaedah untuk membaca dan menulis fail java dbf
Kaedah untuk membaca dan menulis fail java dbf
 Bagaimana untuk menyelesaikan masalah bahawa fail msxml6.dll hilang
Bagaimana untuk menyelesaikan masalah bahawa fail msxml6.dll hilang
 Formula pilih atur dan gabungan yang biasa digunakan
Formula pilih atur dan gabungan yang biasa digunakan
 Nombor telefon mudah alih maya untuk menerima kod pengesahan
Nombor telefon mudah alih maya untuk menerima kod pengesahan
 album foto dinamik
album foto dinamik








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



