

Model Bahasa Kecil Mistral AI (SLM), Mistral Small 3, memberikan prestasi dan kecekapan yang mengagumkan. Model parameter 24 bilion ini menawarkan masa tindak balas yang cepat dan keupayaan yang mantap merentasi tugas AI yang pelbagai. Mari kita meneroka ciri -ciri, aplikasi, aksesibiliti, dan perbandingan penanda aras.
Memperkenalkan Kecil 3, model kami yang paling cekap dan serba boleh! Versi pra-terlatih dan diarahkan, Apache 2.0, 24B, 81% MMLU, 150 TOK/s. Tiada data sintetik, menjadikannya sesuai untuk tugas -tugas pemikiran. Bangunan gembira!
Jadual Kandungan
Apa yang Mistral Small 3?
Mistral Small 3 mengutamakan latensi rendah tanpa mengorbankan prestasi. Parameter 24Bnya menyaingi model yang lebih besar seperti Llama 3.3 70B arahan dan qwen2.5 32B mengarahkan, menawarkan fungsi setanding dengan keperluan pengiraan yang berkurangan. Dikeluarkan sebagai model asas, pemaju dapat melatihnya dengan menggunakan pembelajaran tetulang atau penalaan halus. Tingkap konteks 32,000 yang ditarik dan 150 kelajuan pemprosesan tokens-per-second menjadikannya sesuai untuk aplikasi yang menuntut kelajuan dan ketepatan.
Sokongan berbilang bahasa (Bahasa Inggeris, Perancis, Jerman, Sepanyol, Itali, Cina, Jepun, Korea, Portugis, Belanda, Poland)
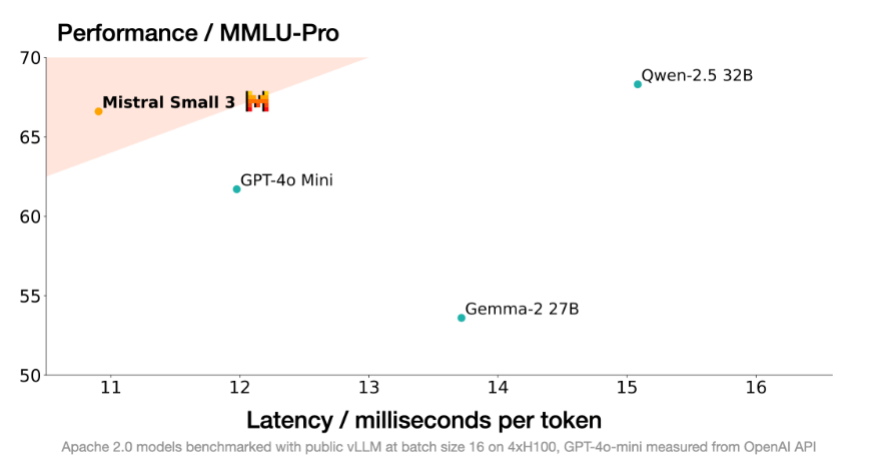
Mistral Small 3 cemerlang dalam pelbagai tanda aras, sering mengalahkan model yang lebih besar di kawasan tertentu sambil mengekalkan kelajuan unggul. Perbandingan terhadap GPT-4O-Mini, Llama 3.3 70B mengajar, qwen2.5 32B mengajar, dan Gemma 2 27B menyerlahkan kekuatannya.
Lihat juga: PHI 4 vs GPT 4O-MINI Perbandingan
1. Pemahaman Bahasa Multitask Massive (MMLU):
Mistral Small 3 mencapai ketepatan lebih dari 81%, menunjukkan prestasi yang kuat merentasi pelbagai subjek.
2. Tujuan Umum Soalan Menjawab (GPQA) Utama: Ia melebihi pesaing dalam menjawab soalan -soalan yang pelbagai, mempamerkan kebolehan penalaran yang mantap.
3. HumanEval: Pengekodan pengekodannya adalah setanding dengan Llama-3.3-70B-Instruct.

4. Arahan Matematik: Mistral Small 3 menunjukkan hasil yang menjanjikan dalam penyelesaian masalah matematik.
kelebihan kelajuan Mistral Small 3 (lebih daripada tiga kali lebih cepat daripada Llama 3.3 70B Mengarahkan perkakasan yang sama) menggariskan kecekapannya.
Lihat juga: qwen2.5-vl Visi Model Gambaran Keseluruhan
Mengakses Mistral Small 3
Mistral Small 3 boleh didapati di bawah lesen Apache 2.0 melalui laman web Mistral AI, memeluk Face, Ollama, Kaggle, Together AI, dan Fireworks AI. Contoh Kaggle di bawah menggambarkan integrasinya:
pip install kagglehub
from transformers import AutoModelForCausalLM, AutoTokenizer
import kagglehub
model_name = kagglehub.model_download("mistral-ai/mistral-small-24b/transformers/mistral-small-24b-base-2501")
# ... (rest of the code as provided in the original text)
Atas ialah kandungan terperinci Mistral Small 3 | Cara mengakses, ciri, prestasi, dan banyak lagi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penggunaan rewritecond
Penggunaan rewritecond
 Windows tidak dapat menyelesaikan pemformatan penyelesaian cakera keras
Windows tidak dapat menyelesaikan pemformatan penyelesaian cakera keras
 Apakah inskripsi dalam blockchain?
Apakah inskripsi dalam blockchain?
 Apakah maksud aksara lebar penuh?
Apakah maksud aksara lebar penuh?
 Gambar rajah pangkalan data
Gambar rajah pangkalan data
 Bagaimana untuk menyelesaikan ketidakserasian beban pelayan
Bagaimana untuk menyelesaikan ketidakserasian beban pelayan
 Apakah perisian lukisan yang ada?
Apakah perisian lukisan yang ada?
 Bagaimana untuk mendapatkan alamat bar alamat
Bagaimana untuk mendapatkan alamat bar alamat








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



