

Lightrag: Sistem Generasi Pengambilan Rekrut ringan
Model bahasa yang besar (LLMs) berkembang pesat, tetapi mengintegrasikan pengetahuan luaran dengan berkesan tetap menjadi halangan yang penting. Teknik Generasi Pengambilan semula (RAG) bertujuan untuk meningkatkan output LLM dengan memasukkan maklumat yang relevan semasa generasi. Walau bagaimanapun, sistem kain tradisional boleh menjadi kompleks dan intensif sumber. Makmal Sains Data HKU menangani ini dengan Lightrag, alternatif yang lebih cekap. Lightrag menggabungkan kuasa graf pengetahuan dengan pengambilan vektor, membolehkan pemprosesan maklumat tekstual yang cekap sambil mengekalkan hubungan berstruktur dalam data.
Titik pembelajaran utama:
Mengapa Lightrag mengatasi Rag Tradisional:
Sistem RAG tradisional sering berjuang dengan hubungan yang kompleks antara titik data, mengakibatkan tindak balas yang berpecah -belah. Mereka menggunakan perwakilan data yang sederhana dan rata, kurang pemahaman kontekstual. Sebagai contoh, pertanyaan mengenai kesan kenderaan elektrik pada kualiti udara dan pengangkutan awam mungkin menghasilkan hasil yang berasingan pada setiap topik, gagal menyambungkannya secara bermakna. Lightrag menangani batasan ini.
Bagaimana fungsi lightrag:
Lightrag menggunakan pengindeksan berasaskan graf dan mekanisme pengambilan dwi-peringkat untuk tindak balas yang cekap dan konteks yang kaya dengan pertanyaan kompleks.

Pengindeksan teks berasaskan graf:
 Proses ini melibatkan:
Proses ini melibatkan:
Lightrag menggunakan dua tahap pengambilan semula: 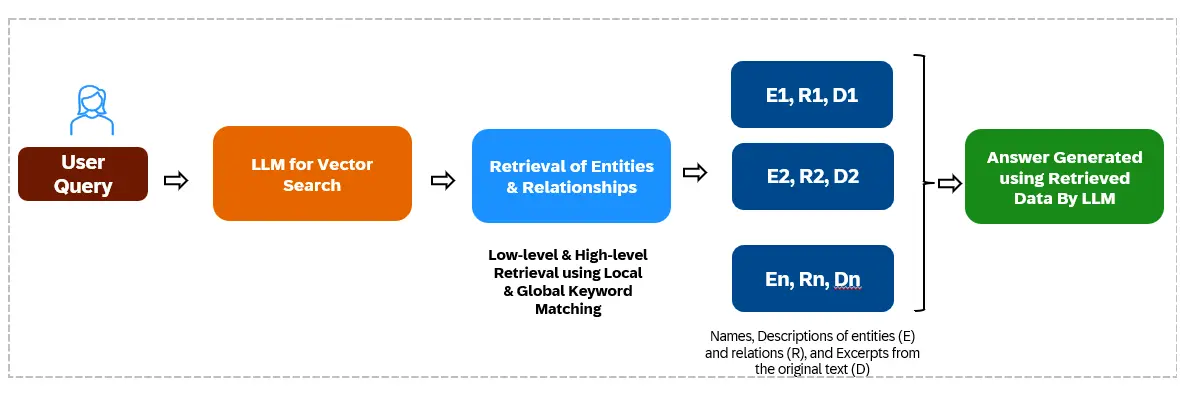
Graphrag mengalami penggunaan token yang tinggi dan banyak panggilan API LLM kerana kaedah traversal berasaskan komuniti. Lightrag, menggunakan carian berasaskan vektor dan mengambil entiti/hubungan bukannya ketulan, dengan ketara mengurangkan overhead ini.
penanda aras prestasi lightrag:
Lightrag ditanda aras terhadap sistem RAG lain menggunakan GPT-4O-Mini untuk penilaian di empat domain (pertanian, sains komputer, undang-undang, dan bercampur). Lightrag secara konsisten mengatasi garis dasar, terutamanya dalam kepelbagaian, terutamanya pada dataset undang -undang yang lebih besar. Ini menonjolkan keupayaannya untuk menjana tindak balas yang pelbagai dan kaya.
pelaksanaan python hands-on (Google Colab):
Langkah -langkah berikut menggariskan pelaksanaan asas menggunakan model OpenAI:
Langkah 1: Pasang perpustakaan
!pip install lightrag-hku aioboto3 tiktoken nano_vectordb !sudo apt update !sudo apt install -y pciutils !pip install langchain-ollama !curl -fsSL https://ollama.com/install.sh | sh !pip install ollama==0.4.2
from lightrag import LightRAG, QueryParam from lightrag.llm import gpt_4o_mini_complete import os os.environ['OPENAI_API_KEY'] = '' # Replace with your key import nest_asyncio nest_asyncio.apply()
WORKING_DIR = "./content"
if not os.path.exists(WORKING_DIR):
os.mkdir(WORKING_DIR)
rag = LightRAG(working_dir=WORKING_DIR, llm_model_func=gpt_4o_mini_complete)
with open("./Coffe.txt") as f: # Replace with your data file
rag.insert(f.read())(contoh yang disediakan dalam teks asal)
Kesimpulan:Lightrag meningkatkan sistem kain tradisional dengan menangani batasan mereka dalam mengendalikan hubungan kompleks dan pemahaman kontekstual. Pengindeksan berasaskan grafik dan pengambilan semula peringkat dwi membawa kepada respons yang lebih komprehensif dan relevan, menjadikannya kemajuan yang berharga dalam bidang.
Takeaways utama:
Lightrag mengatasi batasan Rag Tradisional dalam mengintegrasikan maklumat yang saling berkaitan.
(serupa dengan teks asal, tetapi diubahsuai untuk kesimpulan) (Bahagian ini akan dimasukkan di sini, sama dengan yang asal.)
(nota: URL imej kekal tidak berubah.)
Atas ialah kandungan terperinci Lightrag: alternatif sederhana dan pantas untuk graphrag. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penggunaan asas pernyataan sisipan
Penggunaan asas pernyataan sisipan
 Cara menggunakan return dalam bahasa C
Cara menggunakan return dalam bahasa C
 Bagaimana untuk mengubah suai elemen.gaya
Bagaimana untuk mengubah suai elemen.gaya
 Bagaimana untuk membaca data dalam fail excel dalam python
Bagaimana untuk membaca data dalam fail excel dalam python
 Kaedah pemulihan data komputer Xiaomi
Kaedah pemulihan data komputer Xiaomi
 Bagaimana untuk memasuki mod selamat pada komputer riba
Bagaimana untuk memasuki mod selamat pada komputer riba
 Bagaimana untuk memadam indeks dalam mysql
Bagaimana untuk memadam indeks dalam mysql
 Penggunaan modul semula Python
Penggunaan modul semula Python








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



