

Bermula dengan PHI-2

Pos blog ini menyelidiki model bahasa PHI-2 Microsoft, membandingkan prestasinya dengan model lain dan memperincikan proses latihannya. Kami juga akan meliputi cara mengakses dan menyempurnakan Phi-2 menggunakan Perpustakaan Transformers dan dataset memainkan peranan yang memeluk.
PHI-2, model 2.7 bilion parameter dari siri "PHI" Microsoft, bertujuan untuk prestasi terkini walaupun saiznya yang agak kecil. Ia menggunakan seni bina pengubah, dilatih pada token 1.4 trilion dari dataset sintetik dan web yang memberi tumpuan kepada NLP dan pengekodan. Tidak seperti banyak model yang lebih besar, PHI-2 adalah model asas tanpa pengajaran halus atau RLHF.
Dua aspek utama mendorong pembangunan Phi-2:
-
Data latihan berkualiti tinggi:
- mengutamakan data "buku teks", termasuk dataset sintetik dan kandungan web bernilai tinggi, untuk menanamkan pemikiran akal, pengetahuan umum, dan pemahaman saintifik. Pemindahan pengetahuan berskala:
- memanfaatkan pengetahuan dari model PHI-1.5 parameter 1.3 bilion untuk mempercepat latihan dan meningkatkan skor penanda aras. untuk mendapatkan pandangan untuk membina LLM yang sama, pertimbangkan kursus konsep Master LLM.
PHI-2 Benchmarks
PHI-2 melepasi model parameter 7B-13B seperti Llama-2 dan Mistral merentasi pelbagai tanda aras (pemikiran akal, pemahaman bahasa, matematik, pengekodan). Hebatnya, ia mengatasi Llama-2-70b yang lebih besar pada tugas-tugas penalaran pelbagai langkah.
 Sumber imej
Sumber imej
Fokus ini pada model yang lebih kecil dan mudah disempurnakan membolehkan penggunaan pada peranti mudah alih, mencapai prestasi yang setanding dengan model yang lebih besar. PHI-2 bahkan mengatasi Google Gemini Nano 2 di Big Bench Hard, Boolq, dan MBPP Benchmarks.
Sumber imej 
Mengakses PHI-2 Terokai keupayaan Phi-2 melalui Demo Ruang Muka: Phi 2 Streaming pada GPU. Demo ini menawarkan fungsi tindak balas asas asas.
baru ke AI? Trek Kemahiran Asas AI adalah titik permulaan yang hebat.
mari kita gunakan saluran paip  untuk kesimpulan (pastikan anda mempunyai
untuk kesimpulan (pastikan anda mempunyai
terkini).
transformers Menjana teks menggunakan prompt, menyesuaikan parameter seperti transformers dan accelerate. Output markdown ditukar kepada HTML.
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
) output Phi-2 adalah mengesankan, menghasilkan kod dengan penjelasan. max_new_tokens
temperature
Aplikasi Phi-2
saiz padat Phi-2 membolehkan penggunaan pada komputer riba dan peranti mudah alih untuk Q & A, penjanaan kod, dan perbualan asas.
Fine-penala phi-2
Bahagian ini menunjukkan pHi-2 penalaan halus pada dataset hieunguyenminh/roleplay menggunakan PEFT.
Persediaan dan Pemasangan
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
)Import perpustakaan yang diperlukan:
from IPython.display import Markdown
prompt = "Please create a Python application that can change wallpapers automatically."
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
Markdown(outputs[0]["generated_text"])Tentukan pembolehubah untuk model asas, dataset, dan nama model halus:
%%capture %pip install -U bitsandbytes %pip install -U transformers %pip install -U peft %pip install -U accelerate %pip install -U datasets %pip install -U trl
memeluk Login muka
Log masuk menggunakan token API muka pelukan anda. (Ganti dengan kaedah pengambilan token sebenar anda).
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch
from datasets import load_dataset
from trl import SFTTrainer 
Muatkan subset dataset untuk latihan lebih cepat:
base_model = "microsoft/phi-2" dataset_name = "hieunguyenminh/roleplay" new_model = "phi-2-role-play"
Muatkan model kuantitatif 4-bit untuk kecekapan memori:
# ... (Method to securely retrieve Hugging Face API token) ... !huggingface-cli login --token $secret_hf
Tambahkan lapisan lora untuk penalaan halus yang cekap:
dataset = load_dataset(dataset_name, split="train[0:1000]")
Sediakan hujah latihan dan sfttrainer:
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
 menjimatkan dan menolak model
menjimatkan dan menolak model
simpan dan muat naik model halus:
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense',
'fc1',
'fc2',
]
)
model = get_peft_model(model, peft_config)  Sumber imej
Sumber imej
Penilaian Model
Menilai model yang disesuaikan dengan baik:
training_arguments = TrainingArguments(
output_dir="./results", # Replace with your desired output directory
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_strategy="epoch",
logging_steps=100,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
disable_tqdm=False,
report_to="none",
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= 2048,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
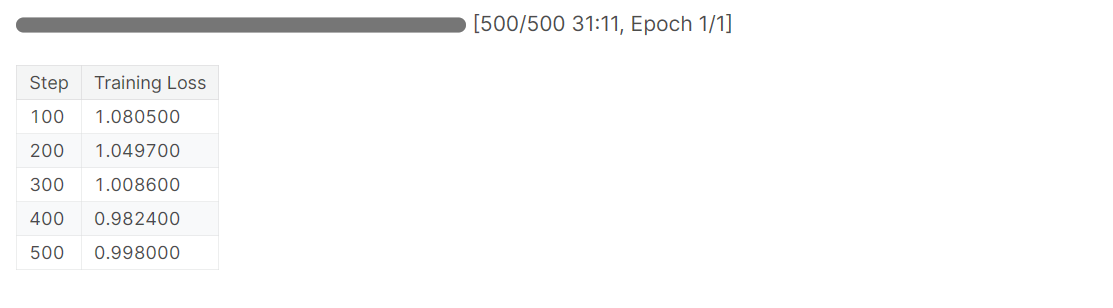
trainer.train()
 Tutorial ini memberikan gambaran menyeluruh mengenai PHI-2 Microsoft, prestasi, latihan, dan penalaan. Keupayaan untuk menyesuaikan model yang lebih kecil ini dengan cekap membuka kemungkinan untuk aplikasi dan penyebaran yang disesuaikan. Eksplorasi lanjut ke dalam aplikasi LLM membina menggunakan rangka kerja seperti Langchain disyorkan.
Tutorial ini memberikan gambaran menyeluruh mengenai PHI-2 Microsoft, prestasi, latihan, dan penalaan. Keupayaan untuk menyesuaikan model yang lebih kecil ini dengan cekap membuka kemungkinan untuk aplikasi dan penyebaran yang disesuaikan. Eksplorasi lanjut ke dalam aplikasi LLM membina menggunakan rangka kerja seperti Langchain disyorkan.
Atas ialah kandungan terperinci Bermula dengan PHI-2. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1655
1655
 14
1413
52
1306
25
1252
29
1226
24
14
1413
52
1306
25
1252
29
1226
24

 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
Hei ada, pengekodan ninja! Apa tugas yang berkaitan dengan pengekodan yang anda telah merancang untuk hari itu? Sebelum anda menyelam lebih jauh ke dalam blog ini, saya ingin anda memikirkan semua kesengsaraan yang berkaitan dengan pengekodan anda-lebih jauh menyenaraikan mereka. Selesai? - Let ’
 AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
Landskap AI minggu ini: Badai kemajuan, pertimbangan etika, dan perdebatan pengawalseliaan. Pemain utama seperti Openai, Google, Meta, dan Microsoft telah melepaskan kemas kini, dari model baru yang terobosan ke peralihan penting di LE
 Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Memo CEO Shopify Tobi Lütke baru -baru ini dengan berani mengisytiharkan penguasaan AI sebagai harapan asas bagi setiap pekerja, menandakan peralihan budaya yang signifikan dalam syarikat. Ini bukan trend seketika; Ini adalah paradigma operasi baru yang disatukan ke p
 Panduan Komprehensif untuk Model Bahasa Visi (VLMS)
Apr 12, 2025 am 11:58 AM
Panduan Komprehensif untuk Model Bahasa Visi (VLMS)
Apr 12, 2025 am 11:58 AM
Pengenalan Bayangkan berjalan melalui galeri seni, dikelilingi oleh lukisan dan patung yang terang. Sekarang, bagaimana jika anda boleh bertanya setiap soalan dan mendapatkan jawapan yang bermakna? Anda mungkin bertanya, "Kisah apa yang anda ceritakan?
 GPT-4O vs OpenAI O1: Adakah model Openai baru bernilai gembar-gembur?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1: Adakah model Openai baru bernilai gembar-gembur?
Apr 13, 2025 am 10:18 AM
Pengenalan OpenAI telah mengeluarkan model barunya berdasarkan seni bina "strawberi" yang sangat dijangka. Model inovatif ini, yang dikenali sebagai O1, meningkatkan keupayaan penalaran, yang membolehkannya berfikir melalui masalah MOR
 Bagaimana untuk menambah lajur dalam SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Pernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Penyusunan Tahunan Terkini Teknik Kejuruteraan Terbaik
Apr 10, 2025 am 11:22 AM
Penyusunan Tahunan Terkini Teknik Kejuruteraan Terbaik
Apr 10, 2025 am 11:22 AM
Bagi anda yang mungkin baru dalam lajur saya, saya secara meluas meneroka kemajuan terkini di AI di seluruh papan, termasuk topik seperti yang terkandung AI, penaakulan AI, terobosan berteknologi tinggi di AI, kejuruteraan segera, latihan AI, Fielding of AI, AI Re Re,
