

Dalam banyak aplikasi dunia nyata, data tidak semata-mata tekstual-ia mungkin termasuk imej, jadual, dan carta yang membantu memperkuat naratif. Penjana laporan multimodal membolehkan anda memasukkan kedua -dua teks dan imej ke dalam output akhir, menjadikan laporan anda lebih dinamik dan kaya dengan visual.
Artikel ini menggariskan bagaimana untuk membina saluran paip itu menggunakan:
Objektif Pembelajaran
Jadual Kandungan Model Langkah 5: Mengurangkan dokumen dengan llamaparse Langkah 6: Teks dan Imej Bersekutu
Setelah persediaan selesai, saluran paip memproses dokumen PDF, menguraikan kandungannya ke dalam teks berstruktur dan menjadikan elemen visual seperti jadual dan carta. Unsur -unsur parsed ini kemudiannya dikaitkan, mewujudkan dataset bersatu. SummaryIndex dibina untuk membolehkan pandangan peringkat tinggi, dan enjin pertanyaan berstruktur dibangunkan untuk menghasilkan laporan yang menggabungkan analisis teks dengan visual yang relevan. Hasilnya adalah penjana laporan dinamik dan interaktif yang mengubah dokumen statik menjadi output yang kaya dan multimodal yang disesuaikan untuk pertanyaan pengguna.
Ikuti panduan terperinci ini untuk membina penjana laporan multimodal, dari menubuhkan kebergantungan untuk menghasilkan output berstruktur dengan teks dan imej bersepadu. Setiap langkah memastikan integrasi lullamaindex, llamaparse, dan arize Phoenix untuk saluran paip yang cekap dan dinamik.
anda memerlukan perpustakaan berikut yang berjalan di Python 3.9.9:
!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Kunci API Phoenix Phoenix boleh didapati dengan mendaftar untuk lbatrace di sini, kemudian navigasi ke panel kiri bawah dan klik pada 'Kekunci' di mana anda perlu mencari kunci API anda.
Sebagai contoh:
Langkah 3: Muatkan data - Dapatkan dek slaid andaPHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)periksa sama ada dek slaid PDF berada dalam folder data, jika tidak letakkan dalam folder data dan namakannya seperti yang anda mahukan.
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Langkah 4: Sediakan Model
Seterusnya, anda mendaftarkannya sebagai lalai untuk llamaindex:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Langkah 5: Mengurangkan dokumen dengan llamaparse
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"]

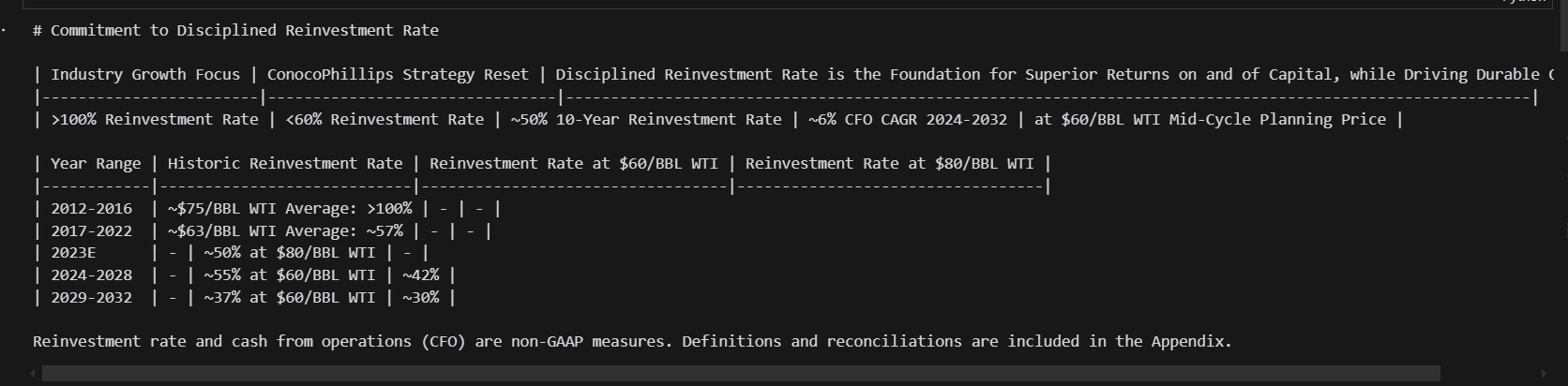
print(md_json_list[10]["md"])
!pip install -U llama-index-callbacks-arize-phoenix
import nest_asyncio
nest_asyncio.apply()
textNode objek (struktur data Llamaindex) untuk setiap halaman. Setiap nod mempunyai metadata mengenai nombor halaman dan laluan fail imej yang sepadan:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)
 Langkah 7: Membina Indeks Ringkasan
Langkah 7: Membina Indeks Ringkasan
SummaryIndex memastikan anda dapat dengan mudah mengambil atau menghasilkan ringkasan peringkat tinggi ke seluruh dokumen.
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Langkah 8: Tentukan skema output berstruktur
textblock dan Titik utama: ReportOutput memerlukan sekurang -kurangnya satu blok imej, memastikan jawapan terakhir adalah multimodal. Langkah 9: Buat enjin pertanyaan berstruktur
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
 Kesimpulan
Kesimpulan
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"]
 Jangan ragu untuk menyesuaikan saluran paip ini ke dokumen anda sendiri, tambahkan langkah pengambilan untuk arkib besar, atau mengintegrasikan model khusus domain untuk menganalisis imej yang mendasari. Dengan asas-asas yang dibentangkan di sini, anda boleh membuat laporan dinamik, interaktif, dan visual yang jauh melebihi pertanyaan berasaskan teks yang mudah.
Jangan ragu untuk menyesuaikan saluran paip ini ke dokumen anda sendiri, tambahkan langkah pengambilan untuk arkib besar, atau mengintegrasikan model khusus domain untuk menganalisis imej yang mendasari. Dengan asas-asas yang dibentangkan di sini, anda boleh membuat laporan dinamik, interaktif, dan visual yang jauh melebihi pertanyaan berasaskan teks yang mudah.
print(md_json_list[10]["md"])
a. Penjana laporan multimodal adalah sistem yang menghasilkan laporan yang mengandungi pelbagai jenis kandungan -terutamanya teks dan imej -dalam satu output kohesif. Dalam saluran paip ini, anda menghuraikan PDF ke dalam kedua -dua elemen teks dan visual, kemudian menggabungkannya ke dalam satu laporan akhir.
Q3. Mengapa menggunakan llamaparse dan bukannya pengekstrak teks pdf standard?
a. SummaryIndex adalah abstraksi llamaindex yang menganjurkan kandungan anda (mis., Halaman PDF) supaya ia dapat dengan cepat menghasilkan ringkasan yang komprehensif. Ia membantu mengumpulkan pandangan peringkat tinggi dari dokumen panjang tanpa perlu memotong mereka secara manual atau menjalankan pertanyaan pengambilan untuk setiap data.
Media yang ditunjukkan dalam artikel ini tidak dimiliki oleh Analytics Vidhya dan digunakan pada budi bicara penulis.
Atas ialah kandungan terperinci Penjanaan laporan kewangan multimodal menggunakan llamaindex. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menggunakan fungsi cetakan dalam python
Bagaimana untuk menggunakan fungsi cetakan dalam python
 securefx tidak boleh menyambung
securefx tidak boleh menyambung
 Pengenalan kepada peralatan pemantauan stesen cuaca
Pengenalan kepada peralatan pemantauan stesen cuaca
 vscode
vscode
 Perbezaan antara bahasa c dan python
Perbezaan antara bahasa c dan python
 Google earth tidak boleh menyambung kepada penyelesaian pelayan
Google earth tidak boleh menyambung kepada penyelesaian pelayan
 Cara memasang perpustakaan pihak ketiga secara sublime
Cara memasang perpustakaan pihak ketiga secara sublime
 Kaedah penyulitan data
Kaedah penyulitan data








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



