

Bagaimanakah Search-O1 meningkatkan aliran logik dalam penalaran AI?

Kemajuan pesat AI mendorong sempadan keupayaan mesin, melebihi jangkaan dari beberapa tahun yang lalu. Model penalaran yang besar (LRM, yang dicontohkan oleh OpenAI-O1) adalah sistem yang canggih menangani masalah yang kompleks melalui pendekatan langkah demi langkah. Model -model ini tidak hanya menyelesaikan masalah; Mereka secara metoden alasan, menggunakan pembelajaran tetulang untuk memperbaiki logik mereka dan menghasilkan penyelesaian yang terperinci dan koheren. Proses yang disengajakan ini, yang sering disebut "pemikiran perlahan," meningkatkan kejelasan logik. Walau bagaimanapun, batasan yang ketara kekal: jurang pengetahuan. LRM boleh menghadapi ketidakpastian yang menyebarkan kesilapan, menjejaskan ketepatan akhir. Penyelesaian tradisional seperti meningkatkan saiz model dan memperluaskan dataset, sementara membantu, mempunyai batasan, dan juga kaedah generasi pengambilan semula (RAG) perjuangan dengan penalaran yang sangat kompleks.
Search-O1, rangka kerja yang dibangunkan oleh penyelidik di Renmin University of China dan Tsinghua University, menangani batasan-batasan ini. Ia dengan lancar mengintegrasikan arahan tugas, soalan, dan pengetahuan yang diambil secara dinamik ke dalam rantaian penalaran yang padu, memudahkan penyelesaian logik. Search-O1 menambah LRM dengan mekanisme RAG yang agentik dan modul alasan-dalam-dokumen untuk memperbaiki maklumat yang diambil.
Jadual Kandungan
- Apa itu Search-O1?
- Penalaran tradisional
- Agentic Rag
- Rangka Kerja Search-O1
- Prestasi Search-O1 merentasi Benchmarks
- Sains QA (GPOQA)
- Masalah matematik
- liveCodeBench (penalaran kod)
- Kajian Kes Kimia dari dataset GPQA
- Masalah
- Strategi Model
- Penalaran dan penyelesaian
- Wawasan Utama
- Kesimpulan
Apa itu Search-O1?
Tidak seperti model tradisional yang berjuang dengan pengetahuan yang tidak lengkap atau kaedah RAG asas yang sering mengambil maklumat yang berlebihan, tidak relevan, Search-O1 memperkenalkan modul sebab-dalam-dokumen yang penting . Modul ini menyuling data yang luas ke dalam langkah ringkas, logik, memastikan ketepatan dan koheren.
Rangka kerja ini beroperasi secara teratur, mencari dan mengekstrak dokumen yang relevan secara dinamik, mengubahnya menjadi langkah penalaran yang tepat, dan menyempurnakan proses sehingga penyelesaian lengkap diperolehi. Ia melampaui pemikiran tradisional (dihalang oleh jurang pengetahuan) dan kaedah RAG asas (yang mengganggu aliran pemikiran). Melalui mekanismeagentik untuk integrasi pengetahuan dan mengekalkan koheren, Search-O1 memastikan penalaran yang boleh dipercayai dan tepat, mewujudkan standard baru untuk penyelesaian masalah yang kompleks dalam AI.
Search-O1 menangani jurang pengetahuan dalam LRMS dengan mengintegrasikan pengambilan pengetahuan luaran dengan lancar tanpa mengganggu aliran logik. Penyelidikan ini membandingkan tiga pendekatan: Penalaran Tradisional, Rag Agentik, dan Rangka Kerja Carian-O1.
1. Penalaran tradisional
Menentukan bilangan atom karbon dalam produk akhir reaksi kimia tiga langkah berfungsi sebagai contoh. Kaedah tradisional berjuang ketika menghadapi jurang pengetahuan, seperti kekurangan struktur trans-cinnamaldehyde . Tanpa maklumat yang tepat, model bergantung kepada andaian, yang berpotensi membawa kepada kesilapan.
2. Agentic RAG
RAG Agentik membolehkan pengambilan pengetahuan autonomi. Jika tidak pasti tentang struktur kompaun, ia menghasilkan pertanyaan khusus (mis., "Struktur trans-cinnamaldehyde "). Walau bagaimanapun, secara langsung menggabungkan dokumen yang diperolehi secara panjang, sering tidak relevan mengganggu proses penalaran dan mengurangkan koheren akibat maklumat yang jelas dan tangen.
3. Search-O1Search-O1 meningkatkan rag agentik dengan modul alasan-dalam-dokumen. Modul ini menyempurnakan dokumen yang diambil ke dalam langkah -langkah penalaran ringkas, mengintegrasikan pengetahuan luaran dengan lancar sambil mengekalkan aliran logik. Memandangkan pertanyaan semasa, dokumen yang diambil, dan rantaian penalaran yang berkembang, ia menghasilkan langkah -langkah yang koheren, saling berkaitan dengan lisan sehingga jawapan konklusif dicapai.
Prestasi Search-O1 merentasi Benchmarks
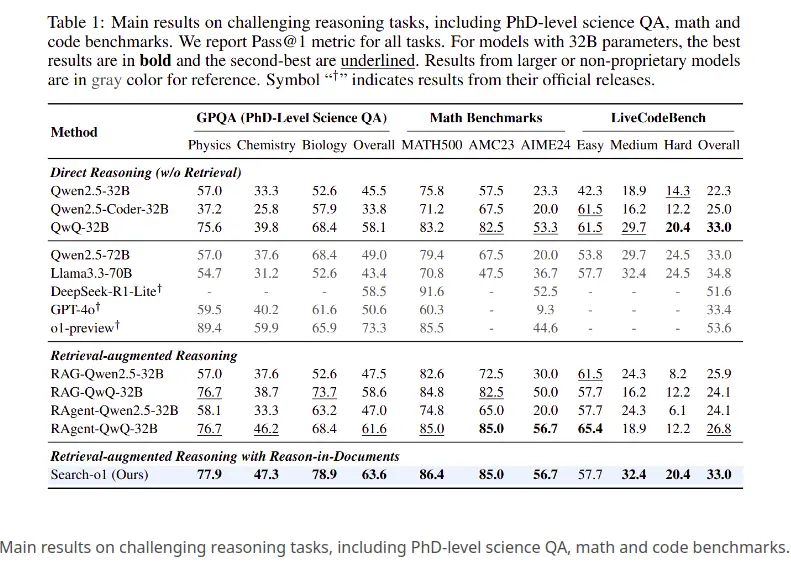 Tiga tugas penalaran yang mencabar telah dinilai:
Tiga tugas penalaran yang mencabar telah dinilai:
- Advanced Science QA (soalan peringkat PhD dalam Fizik, Kimia, Biologi), Masalah matematik kompleks
- (masalah sukar dari Math500 dan AMC23), Cabaran Pengekodan Live
- (tugas pengekodan dunia nyata yang dikategorikan oleh kesukaran). 1. Sains QA (GPOQA)
- Penalaran langsung (tiada pengambilan semula):
- model seperti QWEN2.5-32B (57.0%) dan QWQ-32B (68.4%) tertinggal di belakang Search-O1 (77.9%). Penalaran pengambilan semula: RAG-QWQ-32B (76.7%) dilakukan dengan baik tetapi masih kurang daripada ketepatan
- carian-O1 Search-O1 menunjukkan prestasi unggul dalam fizik (78.9%) dan kimia (47.3%). 2. Penanda aras matematik
Penalaran langsung:
- qwq-32b (83.2%) dilakukan dengan baik di antara kaedah langsung, tetapi
- search-o1 (86.4%) melepasinya. Penalaran pengambilan semula: RAG-QWQ-32B (85.0%) adalah dekat, tetapi
- Search-O1 mengekalkan plumbum, menonjolkan manfaat penalaran berstrukturnya. 3. LiveCodeBench (penalaran kod)
Penalaran langsung: Search-O1 (33.0%).
- Penaakulan semula: Kaedah RAG yang kurang baik berbanding dengan Search-O1 .
-
Penemuan Utama :
Prestasi unggul: Search-O1 secara konsisten mengatasi kaedah lain kerana pendekatan penalaran berulangnya.
Kesan modul alasan-dalam-Dokumen: - Modul ini memastikan penalaran yang difokuskan, memberikan kelebihan ke atas pendekatan langsung dan kain.
keteguhan: - Walaupun beberapa kaedah cemerlang dalam tugas tertentu, Search-O1 menunjukkan prestasi seimbang di semua kategori.
Search-O1 membuktikan kaedah yang paling berkesan dalam semua tugas, menetapkan standard baru dengan menggabungkan pengambilan semula dan penalaran berstruktur. Rangka kerja ini menangani kekurangan pengetahuan dengan mengintegrasikan RAG dengan modul alasan-dalam-dokumen, yang membolehkan penggunaan pengetahuan luaran yang lebih berkesan. Ini membentuk asas yang kukuh untuk penyelidikan masa depan dalam sistem pengambilan, analisis dokumen, dan penyelesaian masalah pintar. -
Kajian Kes Kimia dari dataset GPQA
Kajian kes ini menggambarkan bagaimana carian-o1 menjawab soalan kimia dari dataset GPQA menggunakan penalaran pengambilan semula.
Masalah
Tentukan bilangan atom karbon dalam produk akhir tindak balas pelbagai langkah yang melibatkan trans-cinnamaldehyde.
Strategi model
- Penguraian Masalah: Model menganalisis tindak balas langkah demi langkah, mengenal pasti komponen utama dan bagaimana atom karbon ditambah.
- Pengambilan Pengetahuan Luaran: Model maklumat yang ditanya mengenai mekanisme tindak balas, mengambil data mengenai reaksi reagen grignard dengan aldehid dan struktur trans-cinnamaldehyde.
- Analisis tindak balas berikutnya: Model mengesan atom karbon berubah sepanjang setiap langkah reaksi.
- Pengesahan Struktur Awal: Model mengesahkan kiraan atom karbon awal dalam trans-cinnamaldehyde.
- Analisis tindak balas akhir: Model menganalisis tindak balas akhir, menentukan jumlah atom karbon dalam produk akhir.
Penalaran dan penyelesaian
Model ini menyimpulkan bahawa produk akhir mengandungi 11 atom karbon (bermula dengan 9, menambah satu dari reaksi Grignard, dan satu lagi dalam langkah terakhir). Jawapannya ialah 11.
Wawasan Utama
- Penggunaan pengetahuan yang berkesan: carian yang disasarkan jurang pengetahuan yang diisi.
- Penalaran berulang: analisis langkah demi langkah yang metodik memastikan ketepatan.
- Pemeriksaan ralat: model yang dinilai semula, memastikan ketepatan.
Kesimpulan
Search-O1 mewakili kemajuan yang signifikan dalam LRM, menangani kekurangan pengetahuan. Dengan mengintegrasikan RAG Agentik dan modul alasan-dalam-dokumen, ia membolehkan penalaran berulang yang lancar yang menggabungkan pengetahuan luaran sambil mengekalkan koheren logik. Prestasi unggulnya merentasi pelbagai domain menetapkan standard baru untuk penyelesaian masalah yang kompleks di AI. Inovasi ini meningkatkan ketepatan pemikiran dan membuka jalan untuk penyelidikan dalam sistem pengambilan, analisis dokumen, dan penyelesaian masalah pintar, merapatkan jurang antara pengambilan pengetahuan dan penalaran logik. Search-O1 mewujudkan asas yang mantap untuk masa depan AI, membolehkan penyelesaian yang lebih berkesan untuk cabaran yang kompleks.
- (33.0%).
- Penaakulan semula: Kaedah RAG yang kurang baik berbanding dengan Search-O1 .
- Penemuan Utama :
Prestasi unggul: Search-O1 secara konsisten mengatasi kaedah lain kerana pendekatan penalaran berulangnya.
- Kesan modul alasan-dalam-Dokumen:
- Modul ini memastikan penalaran yang difokuskan, memberikan kelebihan ke atas pendekatan langsung dan kain. keteguhan:
- Walaupun beberapa kaedah cemerlang dalam tugas tertentu, Search-O1 menunjukkan prestasi seimbang di semua kategori. Search-O1 membuktikan kaedah yang paling berkesan dalam semua tugas, menetapkan standard baru dengan menggabungkan pengambilan semula dan penalaran berstruktur. Rangka kerja ini menangani kekurangan pengetahuan dengan mengintegrasikan RAG dengan modul alasan-dalam-dokumen, yang membolehkan penggunaan pengetahuan luaran yang lebih berkesan. Ini membentuk asas yang kukuh untuk penyelidikan masa depan dalam sistem pengambilan, analisis dokumen, dan penyelesaian masalah pintar.
- Kajian Kes Kimia dari dataset GPQA Kajian kes ini menggambarkan bagaimana carian-o1 menjawab soalan kimia dari dataset GPQA menggunakan penalaran pengambilan semula.
Masalah
Tentukan bilangan atom karbon dalam produk akhir tindak balas pelbagai langkah yang melibatkan trans-cinnamaldehyde.
Strategi model
- Penguraian Masalah: Model menganalisis tindak balas langkah demi langkah, mengenal pasti komponen utama dan bagaimana atom karbon ditambah.
- Pengambilan Pengetahuan Luaran: Model maklumat yang ditanya mengenai mekanisme tindak balas, mengambil data mengenai reaksi reagen grignard dengan aldehid dan struktur trans-cinnamaldehyde.
- Analisis tindak balas berikutnya: Model mengesan atom karbon berubah sepanjang setiap langkah reaksi.
- Pengesahan Struktur Awal: Model mengesahkan kiraan atom karbon awal dalam trans-cinnamaldehyde.
- Analisis tindak balas akhir: Model menganalisis tindak balas akhir, menentukan jumlah atom karbon dalam produk akhir.
Penalaran dan penyelesaian
Model ini menyimpulkan bahawa produk akhir mengandungi 11 atom karbon (bermula dengan 9, menambah satu dari reaksi Grignard, dan satu lagi dalam langkah terakhir). Jawapannya ialah 11.
Wawasan Utama
- Penggunaan pengetahuan yang berkesan: carian yang disasarkan jurang pengetahuan yang diisi.
- Penalaran berulang: analisis langkah demi langkah yang metodik memastikan ketepatan.
- Pemeriksaan ralat: model yang dinilai semula, memastikan ketepatan.
Kesimpulan
Search-O1 mewakili kemajuan yang signifikan dalam LRM, menangani kekurangan pengetahuan. Dengan mengintegrasikan RAG Agentik dan modul alasan-dalam-dokumen, ia membolehkan penalaran berulang yang lancar yang menggabungkan pengetahuan luaran sambil mengekalkan koheren logik. Prestasi unggulnya merentasi pelbagai domain menetapkan standard baru untuk penyelesaian masalah yang kompleks di AI. Inovasi ini meningkatkan ketepatan pemikiran dan membuka jalan untuk penyelidikan dalam sistem pengambilan, analisis dokumen, dan penyelesaian masalah pintar, merapatkan jurang antara pengambilan pengetahuan dan penalaran logik. Search-O1 mewujudkan asas yang mantap untuk masa depan AI, membolehkan penyelesaian yang lebih berkesan untuk cabaran yang kompleks.
Atas ialah kandungan terperinci Bagaimanakah Search-O1 meningkatkan aliran logik dalam penalaran AI?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
Artikel ini membandingkan chatbots AI seperti Chatgpt, Gemini, dan Claude, yang memberi tumpuan kepada ciri -ciri unik mereka, pilihan penyesuaian, dan prestasi dalam pemprosesan bahasa semula jadi dan kebolehpercayaan.
 Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Artikel ini membincangkan pembantu penulisan AI terkemuka seperti Grammarly, Jasper, Copy.ai, WriteSonic, dan Rytr, yang memberi tumpuan kepada ciri -ciri unik mereka untuk penciptaan kandungan. Ia berpendapat bahawa Jasper cemerlang dalam pengoptimuman SEO, sementara alat AI membantu mengekalkan nada terdiri
 AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
Landskap AI minggu ini: Badai kemajuan, pertimbangan etika, dan perdebatan pengawalseliaan. Pemain utama seperti Openai, Google, Meta, dan Microsoft telah melepaskan kemas kini, dari model baru yang terobosan ke peralihan penting di LE
 Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Memo CEO Shopify Tobi Lütke baru -baru ini dengan berani mengisytiharkan penguasaan AI sebagai harapan asas bagi setiap pekerja, menandakan peralihan budaya yang signifikan dalam syarikat. Ini bukan trend seketika; Ini adalah paradigma operasi baru yang disatukan ke p
 10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
Hei ada, pengekodan ninja! Apa tugas yang berkaitan dengan pengekodan yang anda telah merancang untuk hari itu? Sebelum anda menyelam lebih jauh ke dalam blog ini, saya ingin anda memikirkan semua kesengsaraan yang berkaitan dengan pengekodan anda-lebih jauh menyenaraikan mereka. Selesai? - Let ’
 Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Artikel ini mengulas penjana suara AI atas seperti Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, dan Descript, memberi tumpuan kepada ciri -ciri mereka, kualiti suara, dan kesesuaian untuk keperluan yang berbeza.
