

Penanda aras CPU pembelajaran yang mendalam

Penanda aras GPU pembelajaran mendalam telah merevolusikan cara kita menyelesaikan masalah yang rumit, dari pengiktirafan imej kepada pemprosesan bahasa semula jadi. Walau bagaimanapun, semasa melatih model-model ini sering bergantung kepada GPU berprestasi tinggi, menggunakannya dengan berkesan dalam persekitaran yang terkawal sumber seperti peranti kelebihan atau sistem dengan perkakasan terhad memberikan cabaran yang unik. CPU, yang tersedia secara meluas dan cekap kos, sering berfungsi sebagai tulang belakang untuk kesimpulan dalam senario tersebut. Tetapi bagaimana kita memastikan bahawa model yang digunakan pada CPU memberikan prestasi yang optimum tanpa menjejaskan ketepatan?
Artikel ini menyelam ke dalam penanda aras kesimpulan model pembelajaran mendalam pada CPU, yang memberi tumpuan kepada tiga metrik kritikal: latency, penggunaan CPU dan penggunaan ingatan. Menggunakan contoh klasifikasi spam, kami meneroka bagaimana kerangka popular seperti Pytorch, Tensorflow, Jax, dan ONNX Runtime Handle Handle Inference Workloads. Akhirnya, anda akan mempunyai pemahaman yang jelas tentang cara mengukur prestasi, mengoptimumkan penyebaran, dan memilih alat dan kerangka yang tepat untuk kesimpulan berasaskan CPU dalam persekitaran yang terkawal sumber.
Kesan: Pelaksanaan kesimpulan yang optimum dapat menjimatkan sejumlah besar wang dan sumber bebas untuk beban kerja lain.
Objektif pembelajaran
- Memahami peranan penanda aras CPU pembelajaran mendalam dalam menilai prestasi perkakasan untuk latihan dan kesimpulan model AI.
- Evaluasi Pytorch, Tensorflow, Jax, Onnx Runtime, dan Openvino Runtime untuk memilih yang terbaik untuk keperluan anda.
- Alat induk seperti PSUTIL dan masa untuk mengumpul data prestasi yang tepat dan mengoptimumkan kesimpulan.
- Sediakan model, jalankan kesimpulan, dan mengukur prestasi, menggunakan teknik untuk tugas -tugas yang pelbagai seperti klasifikasi imej dan NLP.
- Kenal pasti kesesakan, mengoptimumkan model, dan meningkatkan prestasi sambil menguruskan sumber dengan cekap.
Artikel ini diterbitkan sebagai sebahagian daripada Blogathon Sains Data.
Jadual Kandungan
- Mengoptimumkan kesimpulan dengan pecutan runtime
- Metrik prestasi kesimpulan model
- Andaian dan batasan
- Alat dan kerangka
- Pasang kebergantungan
- Penyataan masalah dan spesifikasi input
- Senibina dan format model
- Contoh rangkaian tambahan untuk penanda aras
- Aliran kerja penanda aras
- Fungsi penanda aras definiton
- Kesimpulan model dan melaksanakan penandaarasan untuk setiap rangka kerja
- Keputusan dan perbincangan
- Kesimpulan
- Soalan yang sering ditanya
Mengoptimumkan kesimpulan dengan pecutan runtime
Kelajuan kesimpulan adalah penting untuk pengalaman pengguna dan kecekapan operasi dalam aplikasi pembelajaran mesin. Pengoptimuman runtime memainkan peranan penting dalam meningkatkan ini dengan menyelaraskan pelaksanaan. Menggunakan perpustakaan yang dipercepatkan perkakasan seperti runtime ONNX mengambil kesempatan daripada pengoptimuman yang disesuaikan dengan seni bina tertentu, mengurangkan latensi (masa per kesimpulan).
Di samping itu, format model ringan seperti ONNX meminimumkan overhead, membolehkan pemuatan dan pelaksanaan yang lebih cepat. Runtime yang dioptimumkan memanfaatkan pemprosesan selari untuk mengedarkan pengiraan di seluruh teras CPU yang tersedia dan meningkatkan pengurusan memori, memastikan prestasi yang lebih baik terutama pada sistem dengan sumber yang terhad. Pendekatan ini menjadikan model lebih cepat dan lebih cekap sambil mengekalkan ketepatan.
Metrik prestasi kesimpulan model
Untuk menilai prestasi model kami, kami memberi tumpuan kepada tiga metrik utama:
Latensi
- Definisi: Latency merujuk kepada masa yang diperlukan untuk model membuat ramalan selepas menerima input. Ini sering diukur sebagai masa yang diambil dari menghantar data input untuk menerima output (ramalan)
- Kepentingan : Dalam aplikasi masa nyata atau hampir nyata masa, latency tinggi membawa kepada kelewatan, yang boleh menyebabkan tindak balas yang lebih perlahan.
- Pengukuran : Latensi biasanya diukur dalam milisaat (MS) atau saat. Latihan yang lebih pendek bermakna sistem lebih responsif dan cekap, penting untuk aplikasi yang memerlukan pengambilan keputusan atau tindakan segera.
Penggunaan CPU
- Definisi : Penggunaan CPU adalah peratusan kuasa pemprosesan CPU yang dimakan semasa melaksanakan tugas kesimpulan. Ia memberitahu anda berapa banyak sumber pengiraan sistem yang digunakan semasa kesimpulan model.
- Kepentingan : Penggunaan CPU yang tinggi bermakna mesin mungkin berjuang untuk mengendalikan tugas -tugas lain secara serentak, yang membawa kepada kesesakan. Penggunaan sumber CPU yang cekap memastikan bahawa kesimpulan model tidak memonopoli sumber sistem.
- Pengukuran T: Ia biasanya diukur sebagai peratusan (%) daripada jumlah sumber CPU yang tersedia. Penggunaan yang lebih rendah untuk beban kerja yang sama umumnya menunjukkan model yang lebih dioptimumkan, menggunakan sumber CPU dengan lebih berkesan.
Penggunaan memori
- Definisi: Penggunaan memori merujuk kepada jumlah RAM yang digunakan oleh model semasa proses kesimpulan. Ia menjejaki penggunaan memori oleh parameter model, perhitungan pertengahan, dan data input.
- Kepentingan: Mengoptimumkan penggunaan memori amat kritikal apabila menggunakan model ke peranti kelebihan atau sistem yang memori terhad. Penggunaan memori yang tinggi boleh menyebabkan limpahan ingatan, pemprosesan yang lebih perlahan, atau kemalangan sistem.
- Pengukuran: Penggunaan memori adalah ukuran dalam megabait (MB) atau gigabait (GB). Mengesan penggunaan memori pada tahap kesimpulan yang berbeza dapat membantu mengenal pasti ketidakcekapan memori atau kebocoran memori.
Andaian dan batasan
Untuk memastikan kajian penanda aras ini difokuskan dan praktikal, kami membuat andaian berikut dan menetapkan beberapa sempadan:
- Kekangan perkakasan : Ujian direka untuk dijalankan pada mesin tunggal dengan teras CPU terhad. Walaupun perkakasan moden mampu mengendalikan beban kerja selari, persediaan ini mencerminkan kekangan yang sering dilihat dalam peranti tepi atau penyebaran berskala kecil.
- Tiada paralelisasi multi-sistem : Kami tidak menggabungkan persediaan pengkomputeran yang diedarkan atau penyelesaian berasaskan kluster. Penanda aras mencerminkan keadaan mandiri prestasi, sesuai untuk persekitaran nod tunggal dengan teras CPU terhad dan ingatan.
- Skop : Tumpuan utama hanya pada prestasi kesimpulan CPU. Walaupun kesimpulan berasaskan GPU adalah pilihan yang sangat baik untuk tugas-tugas yang berintensifkan sumber, penanda aras ini bertujuan untuk memberikan gambaran mengenai persediaan CPU sahaja, yang lebih biasa dalam aplikasi sensitif kos atau mudah alih.
Andaian ini memastikan penanda aras tetap relevan untuk pemaju dan pasukan yang bekerja dengan perkakasan yang terkawal sumber atau yang memerlukan prestasi yang boleh diramal tanpa kerumitan sistem yang diedarkan.
Alat dan kerangka
Kami akan meneroka alat dan kerangka penting yang digunakan untuk menanda aras dan mengoptimumkan kesimpulan model pembelajaran yang mendalam pada CPU, memberikan gambaran tentang keupayaan mereka untuk pelaksanaan yang cekap dalam persekitaran yang terkawal sumber.
Alat profil
- Masa Python (Perpustakaan Masa) : Perpustakaan Masa di Python adalah alat ringan untuk mengukur masa pelaksanaan blok kod. Dengan merakam setem permulaan dan akhir, ia membantu mengira masa yang diambil untuk operasi seperti kesimpulan model atau pemprosesan data.
- PSUTIL (CPU, profil memori) : PSUTI L adalah perpustakaan python untuk pemantauan dan profil SUSTEM. Ia menyediakan data masa nyata mengenai penggunaan CPU, penggunaan memori, cakera I/O dan banyak lagi, menjadikannya sesuai untuk menganalisis penggunaan semasa latihan model atau kesimpulan.
Rangka kerja untuk kesimpulan
- Tensorflow : Rangka kerja yang mantap untuk pembelajaran mendalam yang digunakan secara meluas untuk kedua -dua tugas latihan dan kesimpulan. Ia menawarkan sokongan yang kuat untuk pelbagai model dan strategi penempatan.
- Pytorch: Dikenali dengan kemudahan penggunaan dan graf pengiraan dinamik, Pytorch adalah pilihan yang popular untuk penyelidikan dan penggunaan pengeluaran.
- ONNX RUNTIME : Sumber terbuka, enjin silang platform untuk menjalankan model ONXX (Open Neural Network Exchange), memberikan kesimpulan yang cekap di pelbagai perkakasan dan kerangka.
- Jax : Rangka kerja berfungsi memberi tumpuan kepada pengkomputeran berangka dan pembelajaran mesin berprestasi tinggi, yang menawarkan pembezaan automatik dan pecutan GPU/TPU.
- OpenVino: Dioptimumkan untuk perkakasan Intel, Openvino menyediakan alat untuk pengoptimuman dan penggunaan model pada CPU Intel, GPU dan VPU.
Spesifikasi dan persekitaran perkakasan
Kami menggunakan GitHub Codespace (mesin maya) dengan konfigurasi di bawah:
- Spesifikasi mesin maya: 2 teras, 8 GB RAM, dan penyimpanan 32 GB
- Versi Python: 3.12.1
Pasang kebergantungan
Versi pakej yang digunakan adalah seperti berikut dan utama ini termasuk lima perpustakaan kesimpulan pembelajaran mendalam: Tensorflow, Pytorch, Onnx Runtime, Jax, dan Openvino:
! Pip memasang numpy == 1.26.4 ! Pip Pasang Obor == 2.2.2 ! Pip Pasang TensorFlow == 2.16.2 ! Pip Install Onnx == 1.17.0 ! Pip Pasang onnxruntime == 1.17.0! Pip Pasang Jax == 0.4.30 ! Pip Pasang JaxLib == 0.4.30 ! Pip Pasang OpenVino == 2024.6.0 ! Pip memasang matplotlib == 3.9.3 ! Pip memasang matplotlib: 3.4.3 ! Pip memasang bantal: 8.3.2 ! Pip Pasang PSUTIL: 5.8.0
Penyataan masalah dan spesifikasi input
Oleh kerana kesimpulan model terdiri daripada melakukan beberapa operasi matriks antara berat rangkaian dan data input, ia tidak memerlukan latihan model atau dataset. Untuk contoh kami proses penandaarasan, kami mensimulasikan kes penggunaan klasifikasi standard. Ini menyerupai tugas klasifikasi binari yang biasa seperti pengesanan spam dan keputusan permohonan pinjaman (kelulusan atau penafian). Sifat binari masalah ini menjadikan mereka ideal untuk membandingkan prestasi model di seluruh rangka kerja yang berbeza. Persediaan ini mencerminkan sistem dunia sebenar tetapi membolehkan kita memberi tumpuan kepada prestasi kesimpulan merentasi rangka kerja tanpa memerlukan dataset besar atau model terlatih.
Penyataan masalah
Tugas sampel melibatkan meramalkan sama ada sampel yang diberikan adalah spam atau tidak (kelulusan pinjaman atau penafian), berdasarkan satu set ciri input. Masalah klasifikasi binari ini adalah efisien yang komputasi, membolehkan analisis fokus prestasi kesimpulan tanpa kerumitan tugas klasifikasi pelbagai kelas.
Spesifikasi input
Untuk mensimulasikan data e-mel dunia sebenar, kami menjana input secara rawak. Lembaran ini meniru jenis data yang mungkin diproses oleh penapis spam tetapi mengelakkan keperluan untuk dataset luaran. Data input simulasi ini membolehkan penandaarasan tanpa bergantung pada mana -mana dataset luaran tertentu, menjadikannya sesuai untuk menguji masa kesimpulan model, penggunaan memori, dan prestasi CPU. Sebagai alternatif, anda boleh menggunakan klasifikasi imej, tugas NLP atau tugas pembelajaran mendalam yang lain untuk melaksanakan proses penandaarasan ini.
Senibina dan format model
Pemilihan model adalah langkah kritikal dalam penandaarasan kerana ia secara langsung mempengaruhi prestasi kesimpulan dan pandangan yang diperoleh dari proses profil. Seperti yang disebutkan dalam bahagian sebelumnya, untuk kajian penandaarasan ini, kami memilih kes penggunaan klasifikasi standard, yang melibatkan mengenal pasti sama ada e -mel yang diberikan adalah spam atau tidak. Tugas ini adalah masalah klasifikasi dua kelas yang mudah dikomputasi namun memberikan hasil yang bermakna untuk perbandingan merentasi kerangka.
Senibina model untuk penandaarasan
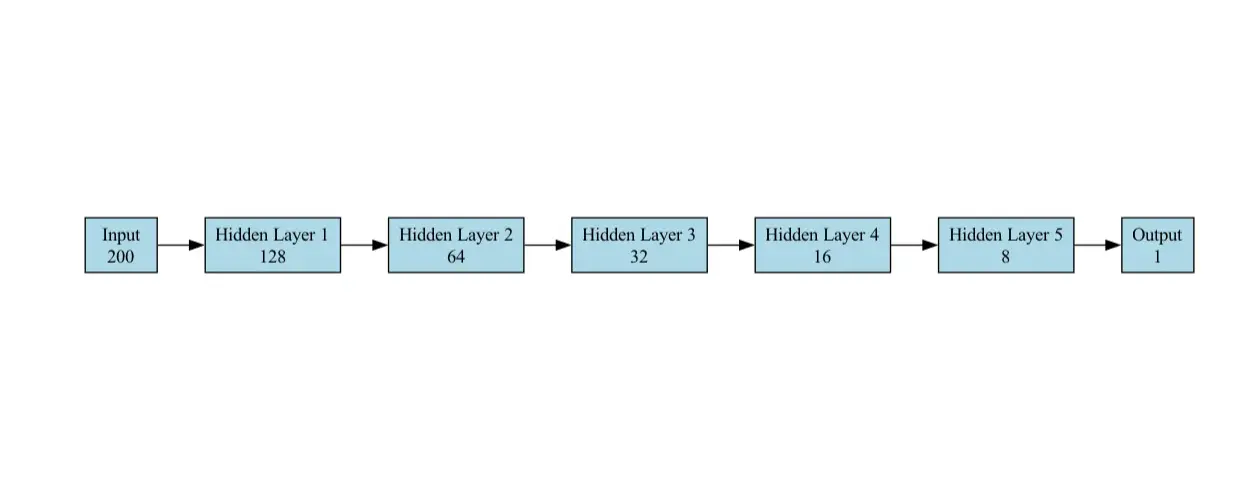
Model untuk tugas klasifikasi adalah rangkaian neural feedforward (FNN) yang direka untuk klasifikasi binari (spam vs tidak spam). Ia terdiri daripada lapisan berikut:
- Lapisan input : Menerima vektor saiz 200 (ciri embedding). Kami telah memberikan contoh pytorch, rangka kerja lain mengikuti konfigurasi rangkaian yang sama
self.fc1 = obor.nn.linear (200,128)
- Lapisan Tersembunyi : Rangkaian mempunyai 5 lapisan tersembunyi, dengan setiap lapisan berturut -turut yang mengandungi unit yang lebih sedikit daripada yang sebelumnya.
self.fc2 = obor.nn.linear (128, 64) self.fc3 = obor.nn.linear (64, 32) self.fc4 = obor.nn.linear (32, 16) self.fc5 = obor.nn.linear (16, 8) self.fc6 = obor.nn.linear (8, 1)
- Lapisan Output : Satu neuron tunggal dengan fungsi pengaktifan sigmoid untuk mengeluarkan kebarangkalian (0 untuk tidak spam, 1 untuk spam). Kami telah menggunakan lapisan sigmoid sebagai output akhir untuk klasifikasi binari.
self.sigmoid = obor.nn.sigmoid ()
Model ini mudah tetapi berkesan untuk tugas klasifikasi.
Gambar rajah seni bina model yang digunakan untuk penandaarasan dalam kes penggunaan kami ditunjukkan di bawah:
Contoh rangkaian tambahan untuk penanda aras
- Klasifikasi Imej: Model seperti ResNet-50 (kerumitan sederhana) dan Mobilenet (ringan) boleh ditambah ke suite penanda aras untuk tugas yang melibatkan pengiktirafan imej. ResNet-50 menawarkan keseimbangan antara kerumitan dan ketepatan pengiraan, sementara Mobilenet dioptimumkan untuk persekitaran sumber rendah.
- Tugas NLP: Distilbert : Varian yang lebih kecil, lebih cepat model Bert, sesuai untuk tugas pemahaman bahasa semula jadi.
Format model
- Format asli: Setiap rangka kerja menyokong format model asalnya, seperti .pt untuk pytorch dan .h5 untuk tensorflow.
- Format Bersatu (ONNX) : Untuk memastikan keserasian merentasi rangka kerja, kami mengeksport model PyTorch ke format ONNX (Model.onnx). ONNX (Buka Neural Network Exchange) bertindak sebagai jambatan, membolehkan model digunakan dalam rangka lain seperti pytorch, tensorflow, Jax, atau openvino tanpa pengubahsuaian yang signifikan. Ini amat berguna untuk ujian pelbagai rangka kerja dan senario penyebaran dunia sebenar, di mana interoperabilitas adalah kritikal.
- Format ini dioptimumkan untuk rangka kerja masing -masing, menjadikannya mudah untuk menyelamatkan, memuat, dan menggunakan dalam ekosistem tersebut.
Aliran kerja penanda aras
Aliran kerja ini bertujuan untuk membandingkan prestasi kesimpulan pelbagai kerangka pembelajaran dalam (Tensorflow, Pytorch, Onnx, Jax, dan Openvino) menggunakan tugas klasifikasi. Tugas ini melibatkan menggunakan data input yang dijana secara rawak dan penanda aras setiap rangka kerja untuk mengukur masa purata yang diambil untuk ramalan.
- Import pakej python
- Lumpuhkan Penggunaan GPU dan Menindas Pembalakan Tensorflow
- Penyediaan data input
- Pelaksanaan model untuk setiap rangka kerja
- Definisi fungsi penandaarasan
- Kesimpulan model dan pelaksanaan penandaarasan untuk setiap rangka kerja
- Visualisasi dan eksport hasil penanda aras
Mengimport pakej python yang diperlukan
Untuk memulakan dengan penanda aras model pembelajaran mendalam, kita perlu mengimport pakej Python penting yang membolehkan integrasi dan penilaian prestasi lancar.
masa import Import OS import numpy sebagai np obor import Import Tensorflow sebagai TF dari input import tensorflow.keras import onnxruntime sebagai ort import matplotlib.pyplot sebagai PLT dari gambar import pil Import psutil Import Jax import jax.numpy sebagai jnp dari Openvino.Runtime Import Core Import CSV
Lumpuhkan Penggunaan GPU dan Menindas Pembalakan Tensorflow
os.environ ["cuda_visible_devices"] = "-1" # lumpuhkan gpu os.environ ["tf_cpp_min_log_level"] = "3" #Suppress Tensorflow Log
Penyediaan data input
Dalam langkah ini, kami secara rawak menjana data input untuk klasifikasi spam:
- Dimensi sampel (ciri-ciri 200-dimesnional)
- Bilangan kelas (2: spam atau tidak spam)
Kami menjana data randome menggunakan Numpy untuk berfungsi sebagai ciri input untuk model.
#Generate data dummy input_data = np.random.rand (1000, 200) .Astype (np.float32)
Definisi model
Dalam langkah ini, kami mentakrifkan seni bina Netwrok atau membuat model dari setiap rangka kerja pembelajaran yang mendalam (Tensorflow, Pytorch, Onnx, Jax dan Openvino). Setiap rangka memerlukan kaedah khusus untuk memuatkan model dan menetapkannya untuk kesimpulan.
- Model Pytorch : Di Pytorch, kami mentakrifkan seni bina rangkaian saraf saraf yang mudah dengan lima lapisan yang disambungkan sepenuhnya.
- Model Tensorflow: Model Tensorflow ditakrifkan menggunakan API Keras dan terdiri daripada rangkaian saraf feedforward yang mudah untuk tugas klasifikasi.
- Model JAX: Model ini diasaskan dengan parameter, dan fungsi ramalan disusun menggunakan kompilasi JAX Just-in-Time (JIT) untuk pelaksanaan yang cekap.
- Model ONNX: Untuk ONNX, kami mengeksport model dari Pytorch. Selepas mengeksport ke format ONNX, kami memuatkan model menggunakan onnxruntime. API Inferencesession. Ini membolehkan kita menjalankan kesimpulan pada model merentasi spesifikasi perkakasan yang berbeza.
- Model Openvino : Openvino digunakan untuk menjalankan model yang dioptimumkan dan digunakan, terutamanya yang terlatih menggunakan rangka kerja lain (seperti pytorch atau tensorflow). Kami memuatkan model ONNX dan menyusunnya dengan runtime Openvino.
Pytorch
kelas pytorchmodel (obor.nn.module):
def __init __ (diri):
super (pytorchmodel, diri) .__ init __ ()
self.fc1 = obor.nn.linear (200, 128)
self.fc2 = obor.nn.linear (128, 64)
self.fc3 = obor.nn.linear (64, 32)
self.fc4 = obor.nn.linear (32, 16)
self.fc5 = obor.nn.linear (16, 8)
self.fc6 = obor.nn.linear (8, 1)
self.sigmoid = obor.nn.sigmoid ()
def forward (diri, x):
x = obor.relu (self.fc1 (x))
x = obor.relu (self.fc2 (x))
x = obor.relu (self.fc3 (x))
x = obor.relu (self.fc4 (x))
x = obor.relu (self.fc5 (x))
x = self.sigmoid (self.fc6 (x))
kembali x
# Buat Model PyTorch
pytorch_model = pytorchModel ()Tensorflow
tensorflow_model = tf.keras.sequential ([[
Input (bentuk = (200,)),
tf.keras.layers.dense (128, pengaktifan = 'relu'),
tf.keras.layers.dense (64, pengaktifan = 'relu'),
tf.keras.layers.dense (32, pengaktifan = 'relu'),
tf.keras.layers.dense (16, pengaktifan = 'relu'),
tf.keras.layers.dense (8, pengaktifan = 'relu'),
tf.keras.layers.dense (1, pengaktifan = 'sigmoid')
])
tensorflow_model.compile ()Jax
def jax_model (x):
x = jax.nn.relu (jnp.dot (x, jnp.ones ((200, 128))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((128, 64))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((64, 32))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((32, 16))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((16, 8))))
x = jax.nn.sigmoid (jnp.dot (x, jnp.ones ((8, 1))))
kembali xOnnx
# Tukar model pytorch ke onnx
dummy_input = obor.randn (1, 200)
onnx_model_path = "model.onnx"
obor.onnx.export (
pytorch_model,
dummy_input,
onnx_model_path,
export_params = benar,
opset_version = 11,
input_names = ['input'],
output_names = ['output'],
dynamic_axes = {'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}
)
onnx_session = ort.inferencesession (onnx_model_path)Openvino
# Definisi Model Openvino teras = teras () openVino_model = core.read_model (model = "model.onnx") compiled_model = core.compile_model (openVino_model, device_name = "cpu")
Fungsi penanda aras definiton
Fungsi ini melaksanakan ujian penanda aras merentasi rangka kerja yang berbeza dengan mengambil tiga argumen: predict_function, input_data, dan num_runs. Secara lalai, ia melaksanakan 1,000 kali tetapi ia boleh ditingkatkan mengikut keperluan.
DEF Benchmark_model (predict_function, input_data, num_runs = 1000):
start_time = time.time ()
proses = psutil.process (os.getPid ())
cpu_usage = []
Memory_usage = []
untuk _ dalam julat (num_runs):
predict_function (input_data)
cpu_usage.append (process.cpu_percent ())
Memory_usage.append (process.memory_info (). RSS)
end_time = time.time ()
avg_latency = (end_time - start_time) / num_runs
avg_cpu = np.mean (cpu_usage)
avg_memory = np.mean (memory_usage) / (1024 * 1024) # Tukar ke MB
Kembalikan AVG_LATENCY, AVG_CPU, AVG_MEMORYKesimpulan model dan melaksanakan penandaarasan untuk setiap rangka kerja
Sekarang kita telah memuatkan model, sudah tiba masanya untuk menanda aras prestasi setiap rangka kerja. Proses penandaarasan melakukan kesimpulan pada data input yang dihasilkan.
Pytorch
# Model Pytorch Benchmark
def pytorch_predict (input_data):
pytorch_model (obor.tensor (input_data))
pytorch_latency, pytorch_cpu, pyTorch_memory = Benchmark_model (lambda x: pytorch_predict (x), input_data)Tensorflow
# Model Tensorflow Benchmark
def tensorflow_predict (input_data):
tensorflow_model (input_data)
tensorflow_latency, tensorflow_cpu, tensorflow_memory = benchmark_model (lambda x: tensorflow_predict (x), input_data)Jax
# Model penanda aras jax
def jax_predict (input_data):
jax_model (jnp.array (input_data))
JAX_LATENCY, JAX_CPU, JAX_MEMORY = Benchmark_model (Lambda X: JAX_PREDICT (X), input_data)Onnx
# Model onnx penanda aras
def onnx_predict (input_data):
# Proses input dalam kelompok
untuk i dalam julat (input_data.shape [0]):
single_input = input_data [i: i 1] # Ekstrak input tunggal
onnx_session.run (none, {onnx_session.get_inputs () [0] .name: single_input})
onnx_latency, onnx_cpu, onnx_memory = benchmark_model (lambda x: onnx_predict (x), input_data)Openvino
# Model Openvino penanda aras
def openvino_predict (input_data):
# Proses input dalam kelompok
untuk i dalam julat (input_data.shape [0]):
single_input = input_data [i: i 1] # Ekstrak input tunggal
compiled_model.infer_new_request ({0: single_input})
OpenVino_Latency, OpenVino_CPU, OpenVino_Memory = Benchmark_Model (lambda x: openvino_predict (x), input_data)
Keputusan dan perbincangan
Di sini kita membincangkan hasil penanda aras prestasi yang disebutkan sebelumnya. Kami membandingkannya - latensi, penggunaan CPU, dan penggunaan memori. Kami telah memasukkan data tabular dan plot untuk perbandingan cepat.
Perbandingan latensi
| Rangka Kerja | Latihan (MS) | Latihan relatif (vs Pytorch) |
| Pytorch | 1.26 | 1.0 (garis dasar) |
| Tensorflow | 6.61 | ~ 5.25 × |
| Jax | 3.15 | ~ 2.50 × |
| Onnx | 14.75 | ~ 11.72 × |
| Openvino | 144.84 | ~ 115 × |
Wawasan:
- Pytorch memimpin sebagai kerangka terpantas dengan latensi ~ 1.26 ms .
- Tensorflow mempunyai ~ 6.61 ms latency, kira -kira 5.25 × masa pytorch.
- Jax duduk di antara pytorch dan tensorflow dalam latensi mutlak.
- ONNX agak perlahan juga, pada ~ 14.75 ms .
- Openvino adalah yang paling lambat dalam eksperimen ini, pada ~ 145 ms (115 × lebih perlahan daripada pytorch).
Penggunaan CPU
| Rangka Kerja | Penggunaan CPU (%) | Penggunaan CPU Relatif 1 |
| Pytorch | 99.79 | ~ 1.00 |
| Tensorflow | 112.26 | ~ 1.13 |
| Jax | 130.03 | ~ 1.31 |
| Onnx | 99.58 | ~ 1.00 |
| Openvino | 99.32 | 1.00 (garis dasar) |
Wawasan:
- Jax menggunakan CPU paling banyak ( ~ 130 % ), ~ 31 % lebih tinggi daripada Openvino.
- Tensorflow berada pada ~ 112 % , lebih daripada Pytorch/Onnx/Openvino tetapi masih lebih rendah daripada Jax.
- Pytorch, Onnx, dan Openvino, semuanya mempunyai penggunaan CPU ~ 99-100% .
Penggunaan memori
| Rangka Kerja | Memori (MB) | Penggunaan Memori Relatif (vs Pytorch) |
| Pytorch | ~ 959.69 | 1.0 (garis dasar) |
| Tensorflow | ~ 969.72 | ~ 1.01 × |
| Jax | ~ 1033.63 | ~ 1.08 × |
| Onnx | ~ 1033.82 | ~ 1.08 × |
| Openvino | ~ 1040.80 | ~ 1.08-1.09 × |
Wawasan:
- Pytorch dan Tensorflow mempunyai penggunaan memori yang sama sekitar ~ 960-970 MB
- Jax, Onnx, dan Openvino menggunakan sekitar ~ 1,030-1,040 MB memori, kira -kira 8-9% lebih daripada pytorch.
Berikut adalah plot yang membandingkan prestasi kerangka pembelajaran mendalam:

Kesimpulan
Dalam artikel ini, kami membentangkan aliran kerja penanda aras yang komprehensif untuk menilai prestasi kesimpulan kerangka pembelajaran mendalam -tensorflow, Pytorch, Onnx, Jax, dan Openvino -menggunakan tugas klasifikasi spam sebagai rujukan. Dengan menganalisis metrik utama seperti latensi, penggunaan CPU dan penggunaan memori, hasilnya menyerlahkan perdagangan antara kerangka dan kesesuaian mereka untuk senario penempatan yang berbeza.
Pytorch menunjukkan prestasi yang paling seimbang, cemerlang dalam latensi rendah dan penggunaan memori yang cekap, menjadikannya sesuai untuk aplikasi sensitif latency seperti ramalan masa nyata dan sistem cadangan. Tensorflow menyediakan penyelesaian tengah tanah dengan penggunaan sumber yang lebih tinggi. Jax mempamerkan melalui pengiraan pengiraan yang tinggi tetapi pada kos penggunaan CPU yang meningkat, yang mungkin merupakan faktor yang membatasi untuk persekitaran yang terkawal sumber. Sementara itu, Onnx dan Openvino tertinggal dalam latensi, dengan prestasi Openvino terutamanya terhalang oleh ketiadaan percepatan perkakasan.
Penemuan ini menggariskan kepentingan menyelaraskan pemilihan kerangka dengan keperluan penggunaan. Sama ada mengoptimumkan kelajuan, kecekapan sumber, atau perkakasan tertentu, memahami perdagangan adalah penting untuk penggunaan model yang berkesan dalam persekitaran dunia sebenar.
Takeaways utama
- Penanda aras CPU pembelajaran mendalam memberikan pandangan kritikal ke dalam prestasi CPU, membantu dalam memilih perkakasan optimum untuk tugas AI.
- Memanfaatkan penanda aras CPU pembelajaran mendalam memastikan latihan dan kesimpulan model yang cekap dengan mengenal pasti CPU berprestasi tinggi.
- Mencapai latensi terbaik (1.26 ms) dan mengekalkan penggunaan memori yang cekap, sesuai untuk aplikasi masa nyata dan sumber terhad.
- Latihan seimbang (6.61 ms) dengan penggunaan CPU sedikit lebih tinggi, sesuai untuk tugas yang memerlukan kompromi prestasi sederhana.
- Menyampaikan latensi kompetitif (3.15 ms) tetapi pada kos penggunaan CPU yang berlebihan ( 130% ), mengehadkan utilitinya dalam setup yang terkawal.
- Menunjukkan latency yang lebih tinggi (14.75 ms), tetapi sokongan silang platform menjadikannya fleksibel untuk penyebaran pelbagai rangka kerja.
Soalan yang sering ditanya
Q1. Kenapa Pytorch lebih disukai untuk aplikasi masa nyata?Grafik pengiraan dinamik Pytorch dan saluran paip pelaksanaan yang cekap membolehkan kesimpulan latency rendah (1.26 ms), menjadikannya sesuai untuk aplikasi seperti sistem cadangan dan ramalan masa nyata.
S2. Apa yang mempengaruhi prestasi Openvino dalam kajian ini?Pengoptimuman Openvino direka untuk perkakasan Intel. Tanpa pecutan ini, latensi (144.84 ms) dan penggunaan memori (1040.8 MB) kurang kompetitif berbanding dengan rangka kerja lain.
Q3. Bagaimanakah saya memilih rangka kerja untuk persekitaran yang terkawal sumber?A. Untuk persediaan CPU sahaja, pytorch adalah yang paling berkesan. TensorFlow adalah alternatif yang kuat untuk beban kerja yang sederhana. Elakkan kerangka seperti JAX melainkan penggunaan CPU yang lebih tinggi dapat diterima.
Q4. Apakah peranan yang dimainkan oleh perkakasan dalam prestasi kerangka?A. Prestasi kerangka bergantung pada keserasian perkakasan. Sebagai contoh, Openvino cemerlang pada CPU Intel dengan pengoptimuman khusus perkakasan, manakala pytorch dan tensorflow melakukan secara konsisten merentasi pelbagai persediaan.
S5. Bolehkah hasil penandaarasan berbeza dengan model atau tugas yang kompleks?A. Ya, hasil ini mencerminkan tugas klasifikasi binari yang mudah. Prestasi boleh berbeza -beza dengan seni bina yang kompleks seperti resnet atau tugas seperti NLP atau yang lain, di mana rangka kerja ini mungkin memanfaatkan pengoptimuman khusus.
Media yang ditunjukkan dalam artikel ini tidak dimiliki oleh Analytics Vidhya dan digunakan atas budi bicara penulis.
Atas ialah kandungan terperinci Penanda aras CPU pembelajaran yang mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
Hei ada, pengekodan ninja! Apa tugas yang berkaitan dengan pengekodan yang anda telah merancang untuk hari itu? Sebelum anda menyelam lebih jauh ke dalam blog ini, saya ingin anda memikirkan semua kesengsaraan yang berkaitan dengan pengekodan anda-lebih jauh menyenaraikan mereka. Selesai? - Let ’
 AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
Landskap AI minggu ini: Badai kemajuan, pertimbangan etika, dan perdebatan pengawalseliaan. Pemain utama seperti Openai, Google, Meta, dan Microsoft telah melepaskan kemas kini, dari model baru yang terobosan ke peralihan penting di LE
 Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Memo CEO Shopify Tobi Lütke baru -baru ini dengan berani mengisytiharkan penguasaan AI sebagai harapan asas bagi setiap pekerja, menandakan peralihan budaya yang signifikan dalam syarikat. Ini bukan trend seketika; Ini adalah paradigma operasi baru yang disatukan ke p
 Panduan Komprehensif untuk Model Bahasa Visi (VLMS)
Apr 12, 2025 am 11:58 AM
Panduan Komprehensif untuk Model Bahasa Visi (VLMS)
Apr 12, 2025 am 11:58 AM
Pengenalan Bayangkan berjalan melalui galeri seni, dikelilingi oleh lukisan dan patung yang terang. Sekarang, bagaimana jika anda boleh bertanya setiap soalan dan mendapatkan jawapan yang bermakna? Anda mungkin bertanya, "Kisah apa yang anda ceritakan?
 GPT-4O vs OpenAI O1: Adakah model Openai baru bernilai gembar-gembur?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1: Adakah model Openai baru bernilai gembar-gembur?
Apr 13, 2025 am 10:18 AM
Pengenalan OpenAI telah mengeluarkan model barunya berdasarkan seni bina "strawberi" yang sangat dijangka. Model inovatif ini, yang dikenali sebagai O1, meningkatkan keupayaan penalaran, yang membolehkannya berfikir melalui masalah MOR
 Membaca Indeks AI 2025: Adakah AI rakan, musuh, atau juruterbang bersama?
Apr 11, 2025 pm 12:13 PM
Membaca Indeks AI 2025: Adakah AI rakan, musuh, atau juruterbang bersama?
Apr 11, 2025 pm 12:13 PM
Laporan Indeks Perisikan Buatan 2025 yang dikeluarkan oleh Stanford University Institute for Manusia Berorientasikan Kecerdasan Buatan memberikan gambaran yang baik tentang revolusi kecerdasan buatan yang berterusan. Mari kita menafsirkannya dalam empat konsep mudah: kognisi (memahami apa yang sedang berlaku), penghargaan (melihat faedah), penerimaan (cabaran muka), dan tanggungjawab (cari tanggungjawab kita). Kognisi: Kecerdasan buatan di mana -mana dan berkembang pesat Kita perlu menyedari betapa cepatnya kecerdasan buatan sedang berkembang dan menyebarkan. Sistem kecerdasan buatan sentiasa bertambah baik, mencapai hasil yang sangat baik dalam ujian matematik dan pemikiran kompleks, dan hanya setahun yang lalu mereka gagal dalam ujian ini. Bayangkan AI menyelesaikan masalah pengekodan kompleks atau masalah saintifik peringkat siswazah-sejak tahun 2023
 3 Kaedah untuk menjalankan Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Kaedah untuk menjalankan Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2: Powerhouse AI Multimodal Model multimodal terbaru Meta, Llama 3.2, mewakili kemajuan yang ketara dalam AI, yang membanggakan pemahaman bahasa yang dipertingkatkan, ketepatan yang lebih baik, dan keupayaan penjanaan teks yang unggul. Keupayaannya t
