

Campuran model pakar (MOE) merevolusi model bahasa besar (LLMS) dengan meningkatkan kecekapan dan skalabiliti. Senibina inovatif ini membahagikan model ke dalam sub-rangkaian khusus, atau "pakar," masing-masing dilatih untuk jenis atau tugas data tertentu. Dengan mengaktifkan hanya subset pakar yang berkaitan berdasarkan input, model MOE dengan ketara meningkatkan kapasiti tanpa peningkatan kos pengiraan secara proporsional. Pengaktifan selektif ini mengoptimumkan penggunaan sumber dan membolehkan pengendalian tugas kompleks merentasi pelbagai bidang seperti pemprosesan bahasa semulajadi, penglihatan komputer, dan sistem cadangan. Artikel ini meneroka model MOE, fungsi mereka, contoh popular, dan pelaksanaan Python.
Artikel ini adalah sebahagian daripada Blogathon Sains Data.
Jadual Kandungan:
Apakah campuran pakar (MOE)?
Model MOE meningkatkan pembelajaran mesin dengan menggunakan model yang lebih kecil, khusus dan bukannya satu besar. Setiap model yang lebih kecil cemerlang pada jenis masalah tertentu. "Pembuat keputusan" (mekanisme gating) memilih model yang sesuai untuk setiap tugas, meningkatkan prestasi keseluruhan. Model pembelajaran mendalam moden, termasuk transformer, menggunakan unit yang saling berkaitan berlapis ("neuron") yang memproses data dan lulus hasil ke lapisan berikutnya. MOE mencerminkan ini dengan membahagikan masalah kompleks ke dalam komponen khusus ("pakar"), masing -masing menangani aspek tertentu.
Kelebihan utama model MOE:
Model MOE terdiri daripada dua bahagian utama: pakar (rangkaian neural yang lebih kecil) dan penghala (yang mengaktifkan pakar yang relevan berdasarkan input). Pengaktifan selektif ini meningkatkan kecekapan.
Moes dalam pembelajaran mendalam
Dalam pembelajaran mendalam, MOE meningkatkan prestasi rangkaian saraf dengan memecahkan masalah yang kompleks. Daripada satu model besar, ia menggunakan model "pakar" yang lebih kecil yang mengkhususkan diri dalam aspek data input yang berbeza. Rangkaian gating menentukan pakar mana yang digunakan untuk setiap input, meningkatkan kecekapan dan keberkesanan.
Bagaimana model MOE berfungsi?
Model MOE beroperasi seperti berikut:
Model berasaskan MOE yang terkenal
Model MOE semakin penting dalam AI kerana skala LLM yang cekap sambil mengekalkan prestasi. Mixtral 8x7b, contoh yang ketara, menggunakan seni bina MOE yang jarang, mengaktifkan hanya subset pakar untuk setiap input, yang membawa kepada keuntungan kecekapan yang signifikan.
Mixtral 8x7b adalah pengubah decoder sahaja. Token input tertanam ke dalam vektor dan diproses melalui lapisan decoder. Output adalah kebarangkalian setiap lokasi yang diduduki oleh perkataan, membolehkan teks dan ramalan teks. Setiap lapisan penyahkod mempunyai mekanisme perhatian (untuk maklumat kontekstual) dan seksyen pakar pakar (SMOE) yang jarang (memproses secara individu setiap vektor perkataan). Lapisan SMOE menggunakan pelbagai lapisan ("pakar") dan, untuk setiap input, jumlah wajaran output pakar yang paling relevan diambil.
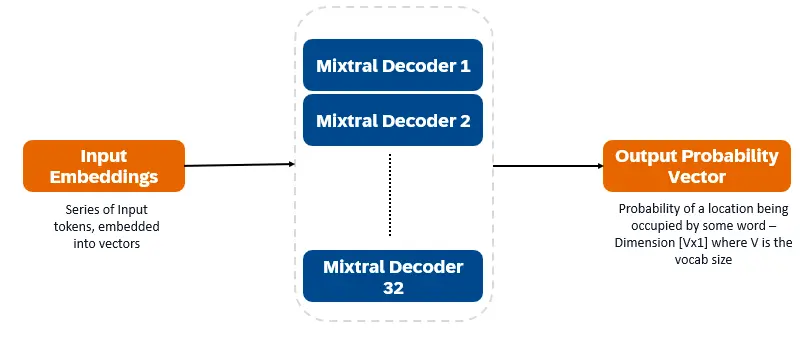
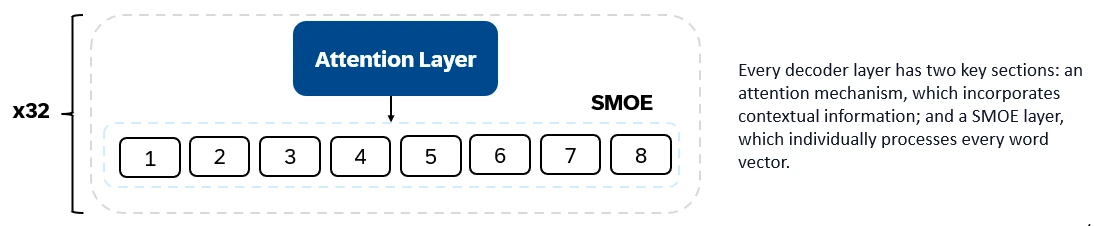
Ciri -ciri utama Mixtral 8x7b:
Mixtral 8x7b cemerlang dalam penjanaan teks, pemahaman, terjemahan, ringkasan, dan banyak lagi.
DBRX (Databricks) adalah LLM decoder-only berasaskan pengubah yang dilatih menggunakan ramalan yang seterusnya. Ia menggunakan seni bina MOE halus (parameter total 132B, aktif 36B). Ia telah terlatih pada token 12T teks dan data kod. DBRX adalah halus, menggunakan banyak pakar yang lebih kecil (16 pakar, 4 dipilih setiap input).
Ciri -ciri seni bina utama DBRX:
Ciri -ciri utama DBRX:
DBRX cemerlang dalam penjanaan kod, pemahaman bahasa yang kompleks, dan penalaran matematik.
DeepSeek-V2 menggunakan pakar halus dan pakar bersama (sentiasa aktif) untuk mengintegrasikan pengetahuan sejagat.
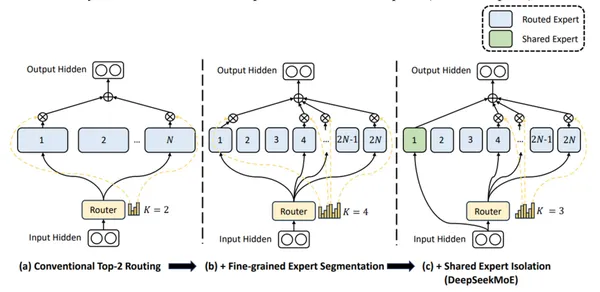
Ciri-ciri utama DeepSeek-V2:
DeepSeek-V2 adalah mahir dalam perbualan, penciptaan kandungan, dan penjanaan kod.
(Bahagian Perbandingan Pelaksanaan dan Output Python dikeluarkan untuk keringkasan, kerana ia adalah contoh kod yang panjang dan analisis terperinci.)
Soalan yang sering ditanya
Q1. Apakah Model Campuran Pakar (MOE)? A. Model MOE menggunakan seni bina yang jarang, mengaktifkan hanya pakar yang paling relevan untuk setiap tugas, yang membawa kepada penggunaan sumber pengiraan yang dikurangkan.
S2. Apakah perdagangan dengan model MOE? A. Model MOE memerlukan VRAM penting untuk menyimpan semua pakar dalam ingatan, mengimbangi kuasa pengiraan dan keperluan memori.
Q3. Apakah kiraan parameter aktif untuk mixtral 8x7b? A. Mixtral 8x7b mempunyai 12.8 bilion parameter aktif.
Q4. Bagaimanakah DBRX berbeza daripada model MOE yang lain? A. DBRX menggunakan pendekatan MOE yang halus dengan pakar yang lebih kecil.
S5. Apa yang membezakan DeepSeek-V2? A. DeepSeek-V2 menggabungkan pakar-pakar yang halus dan dikongsi bersama, bersama dengan set parameter yang besar dan panjang konteks yang panjang.
Kesimpulan
Model MOE menawarkan pendekatan yang sangat berkesan untuk pembelajaran mendalam. Walaupun memerlukan VRAM yang penting, pengaktifan pakar selektif mereka menjadikan mereka alat yang kuat untuk mengendalikan tugas -tugas kompleks di pelbagai domain. Mixtral 8x7b, DBRX, dan DeepSeek-V2 mewakili kemajuan yang ketara dalam bidang ini, masing-masing dengan kekuatan dan aplikasinya sendiri.
Atas ialah kandungan terperinci Apakah campuran pakar?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



