

Artikel ini meneroka generasi pengambilan semula (RAG), teknik AI canggih yang meningkatkan ketepatan tindak balas dengan menggabungkan keupayaan pengambilan dan generasi. RAG meningkatkan keupayaan AI untuk memberikan jawapan yang boleh dipercayai dan kontekstual yang relevan dengan mendapatkan maklumat terkini yang berkaitan dengan asas dari asas pengetahuan sebelum menghasilkan respons. Perbincangan meliputi aliran kerja RAG secara terperinci, termasuk penggunaan pangkalan data vektor untuk pengambilan data yang cekap, kepentingan metrik jarak untuk kesamaan kesamaan, dan bagaimana RAG mengurangkan perangkap AI yang biasa seperti halusinasi dan konflik. Langkah-langkah praktikal untuk menubuhkan dan melaksanakan RAG juga disediakan, menjadikan ini panduan yang komprehensif bagi sesiapa yang bertujuan untuk meningkatkan pengambilan pengetahuan berasaskan AI.
*Artikel ini adalah sebahagian daripada *** Data Science Blogathon.
RAG adalah kaedah AI yang meningkatkan ketepatan jawapan dengan mengambil maklumat yang relevan sebelum menghasilkan respons. Tidak seperti AI tradisional, yang hanya bergantung pada data latihan, RAG mencari pangkalan data atau sumber pengetahuan untuk maklumat terkini atau khusus. Maklumat ini kemudian memberitahu penjanaan jawapan yang lebih tepat dan boleh dipercayai. Pendekatan RAG menggabungkan model pengambilan dan generasi untuk meningkatkan kualiti dan ketepatan kandungan yang dihasilkan, terutama dalam tugas NLP.
Bacaan lanjut: Generasi pengambilan semula untuk tugas NLP yang berintensifkan pengetahuan
Aliran kerja RAG terdiri daripada dua peringkat utama: pengambilan semula dan generasi. Proses langkah demi langkah digariskan di bawah.
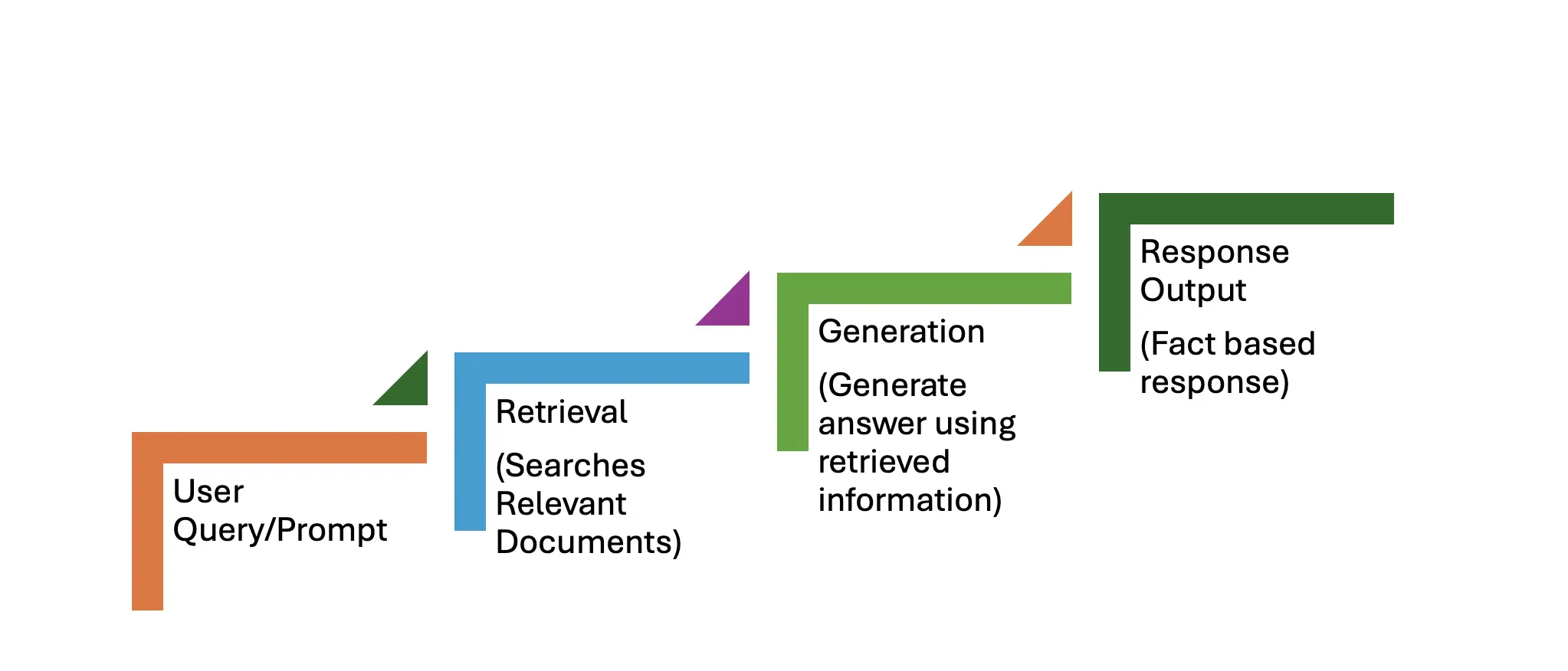
Pertanyaan pengguna, seperti: "Apakah kemajuan terkini dalam pengkomputeran kuantum?" berfungsi sebagai petunjuk.
Fasa ini melibatkan tiga langkah:
Fasa ini juga melibatkan tiga langkah:
Sistem ini mengembalikan tindak balas yang tepat dan terkini, lebih tinggi daripada model generatif yang boleh dihasilkan.
Membandingkan AI dengan dan tanpa RAG menyoroti kuasa transformasi RAG. Model tradisional bergantung semata-mata pada data yang terlatih, sementara RAG meningkatkan respons dengan pengambilan maklumat masa nyata, merapatkan jurang antara output statik dan dinamik, secara kontekstual.
| Dengan kain | Tanpa kain |
|---|---|
| Mendapatkan maklumat semasa dari sumber luaran. | Bergantung semata-mata kepada pengetahuan pra-terlatih (berpotensi ketinggalan zaman). |
| Menyediakan penyelesaian khusus (contohnya, versi patch, perubahan konfigurasi). | Menjana tindak balas yang samar -samar dan umum yang tidak mempunyai butiran yang boleh dilakukan. |
| Meminimumkan risiko halusinasi dengan memberi tanggapan dalam dokumen sebenar. | Risiko halusinasi atau ketidaktepatan, terutamanya untuk maklumat baru -baru ini. |
| Termasuk penasihat vendor terkini atau patch keselamatan. | Mungkin tidak menyedari nasihat atau kemas kini baru -baru ini. |
| Menggabungkan maklumat dalaman (khusus organisasi) dan luaran (pangkalan data awam). | Tidak dapat mengambil maklumat khusus baru atau organisasi. |
Pangkalan data vektor adalah penting untuk dokumen yang cekap dan tepat atau pengambilan data dalam RAG, berdasarkan persamaan semantik. Tidak seperti carian berasaskan kata kunci, yang bergantung pada pencocokan istilah tepat, pangkalan data vektor mewakili teks sebagai vektor dalam ruang dimensi tinggi, clustering makna serupa bersama-sama. Ini menjadikan mereka sangat sesuai untuk sistem RAG. Pangkalan data vektor menyimpan dokumen vektor, membolehkan pengambilan maklumat yang lebih tepat untuk model AI.
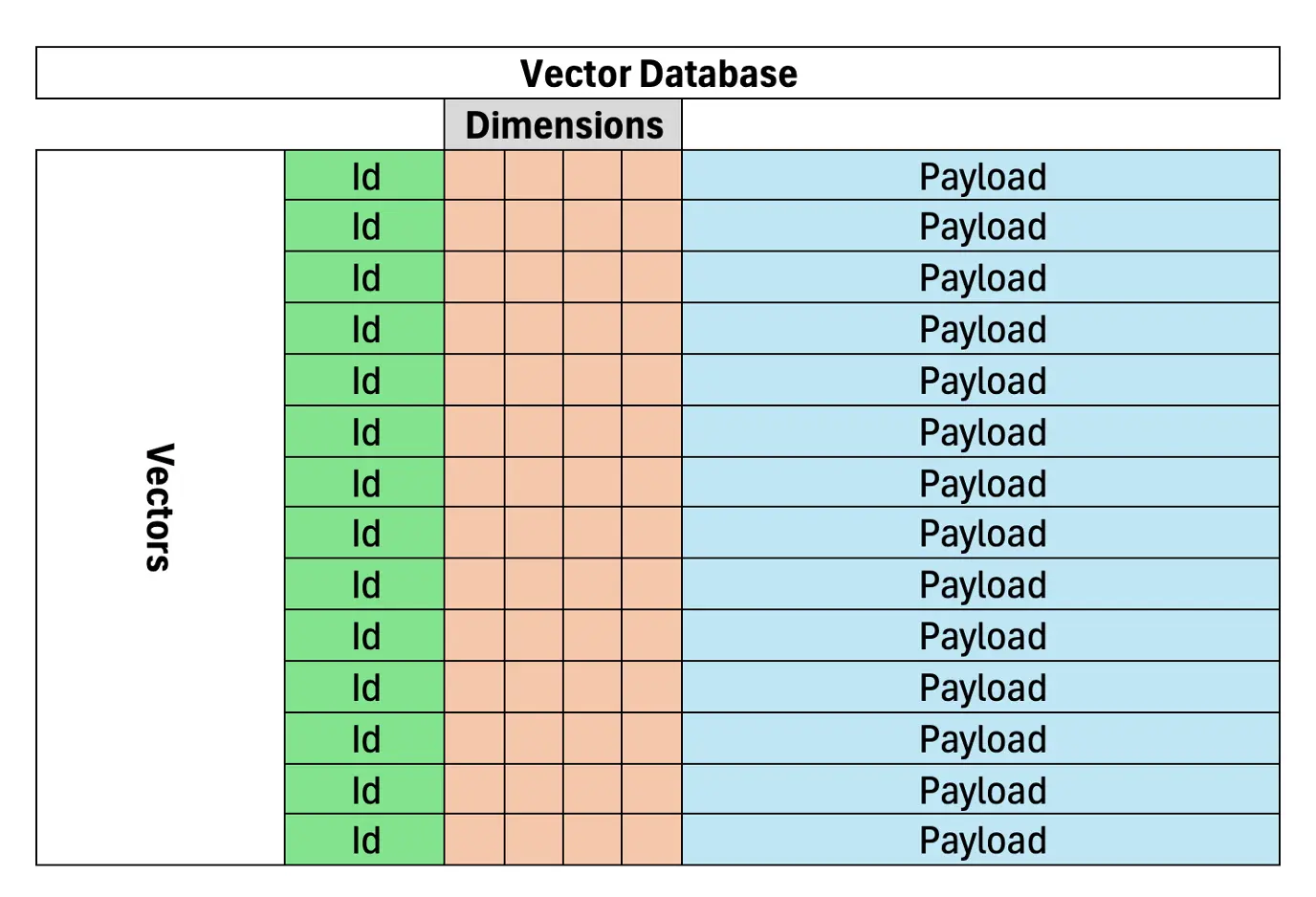
(Bahagian yang selebihnya akan mengikuti corak penyusunan semula dan penstrukturan semula yang sama, mengekalkan maklumat asal dan penempatan imej.)
Atas ialah kandungan terperinci Meningkatkan halusinasi AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyelesaikan sintaks yang tidak sah dalam Python
Bagaimana untuk menyelesaikan sintaks yang tidak sah dalam Python
 securefx tidak boleh menyambung
securefx tidak boleh menyambung
 java mengkonfigurasi pembolehubah persekitaran jdk
java mengkonfigurasi pembolehubah persekitaran jdk
 Padam medan jadual
Padam medan jadual
 harga mata wang fil harga masa nyata
harga mata wang fil harga masa nyata
 Bagaimana untuk membuka fail iso
Bagaimana untuk membuka fail iso
 Apakah kuota cakera
Apakah kuota cakera
 Komponen utama dhtml
Komponen utama dhtml
 Apakah peranan kumpulan pengguna kafka
Apakah peranan kumpulan pengguna kafka








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



