

Apache Iceberg: Format meja moden untuk Pengurusan Tasik Data yang Dipertingkatkan
Apache Iceberg adalah format jadual canggih yang direka untuk menangani kekurangan jadual sarang tradisional, menyampaikan prestasi unggul, konsistensi data, dan skalabiliti. Artikel ini meneroka evolusi Iceberg, ciri -ciri utama (urus niaga asid, evolusi skema, perjalanan masa), seni bina, dan perbandingan dengan format meja lain seperti Delta Lake dan Parquet. Kami juga akan mengkaji integrasi dengan tasik data moden dan kesannya terhadap pengurusan data dan analisis berskala besar.
Berasal di Netflix pada tahun 2017 (gagasan Ryan Blue dan Daniel Weeks), Apache Iceberg dicipta untuk menyelesaikan kesesakan prestasi, masalah konsistensi, dan batasan yang wujud dalam format meja sarang. Sumber terbuka dan disumbangkan kepada Yayasan Perisian Apache pada tahun 2018, ia dengan cepat mendapat daya tarikan, menarik sumbangan dari gergasi industri seperti Apple, AWS, dan LinkedIn.
Pengalaman Netflix menyerlahkan kelemahan kritikal di Hive: pergantungannya pada direktori untuk penjejakan meja. Pendekatan ini tidak mempunyai butiran yang diperlukan untuk konsistensi yang mantap, kesesuaian yang cekap, dan ciri -ciri canggih yang dijangka dalam gudang data moden. Pembangunan Iceberg bertujuan untuk mengatasi batasan -batasan ini dengan tumpuan:
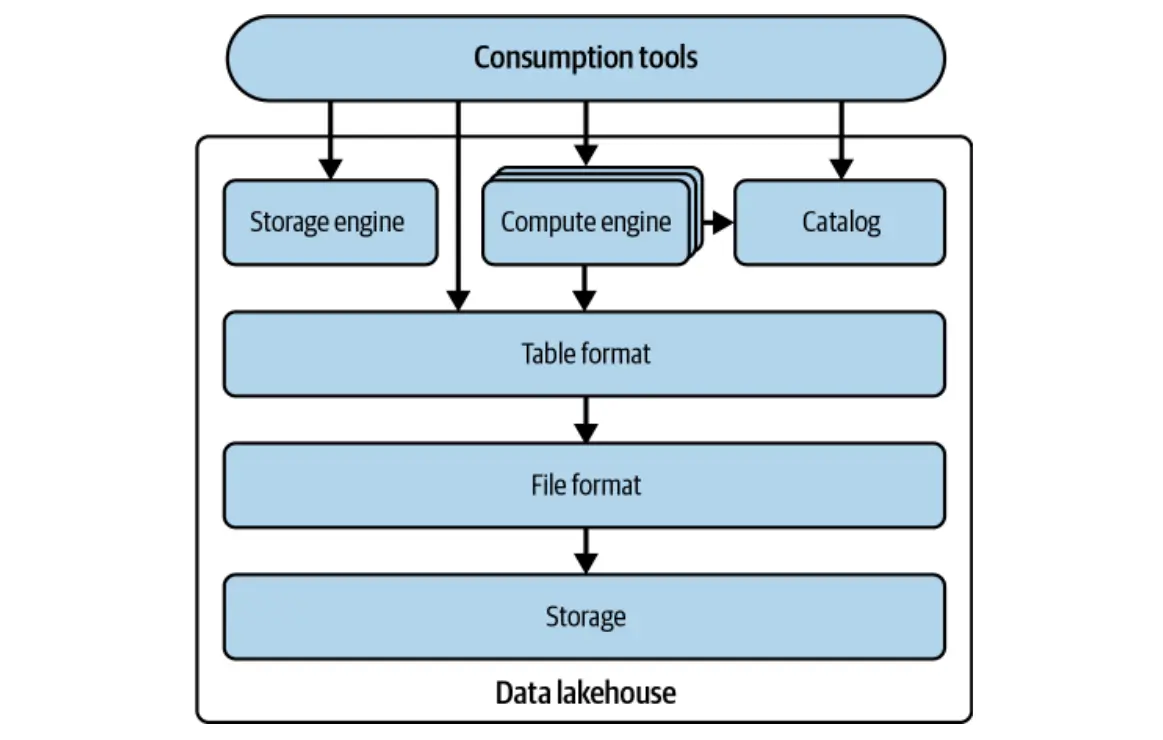
Iceberg menangani cabaran ini dengan menjejaki jadual sebagai senarai fail berstruktur, bukan direktori. Ia menyediakan format piawai yang menentukan struktur metadata merentasi pelbagai fail dan menawarkan perpustakaan untuk integrasi lancar dengan enjin popular seperti Spark dan Flink.
Reka bentuk Iceberg mengutamakan keserasian dengan penyimpanan dan pengiraan enjin sedia ada, mempromosikan penggunaan luas tanpa perubahan yang ketara. Matlamatnya adalah untuk menubuhkan gunung es sebagai standard industri, yang membolehkan pengguna berinteraksi dengan jadual tanpa mengira format asas. Banyak alat data kini menawarkan sokongan aisberg asli.
Iceberg melampaui hanya menangani batasan Hive; Ia memperkenalkan keupayaan yang kuat meningkatkan Data Lake dan Data Lakehouse Workloads. Ciri -ciri utama termasuk:
Iceberg menggunakan kawalan konvensyen yang optimis untuk memastikan sifat asid, menjamin bahawa urus niaga sama ada komited sepenuhnya atau sepenuhnya digulung. Ini meminimumkan konflik sambil mengekalkan integriti data.
Tidak seperti tasik data tradisional, Iceberg membolehkan mengubahsuai skim partition tanpa menulis semula keseluruhan jadual. Ini memastikan pengoptimuman pertanyaan yang cekap tanpa mengganggu data sedia ada.
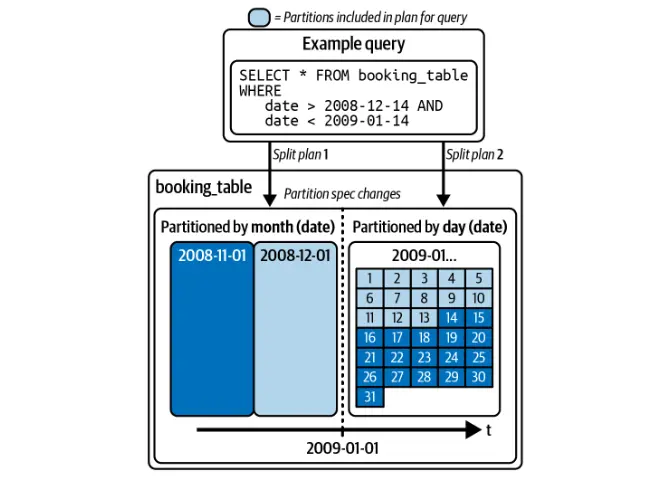
Iceberg secara automatik mengoptimumkan pertanyaan berdasarkan pembahagian, menghapuskan keperluan pengguna untuk menapis secara manual oleh lajur partition.
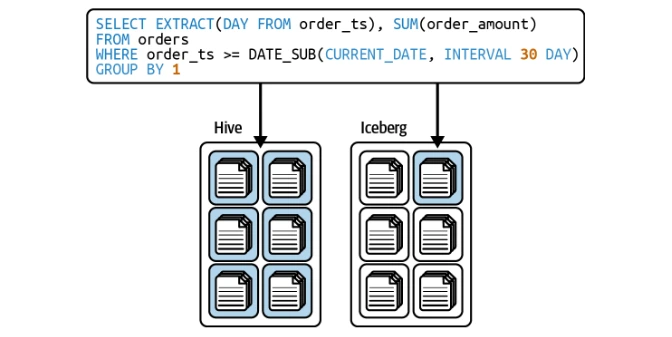
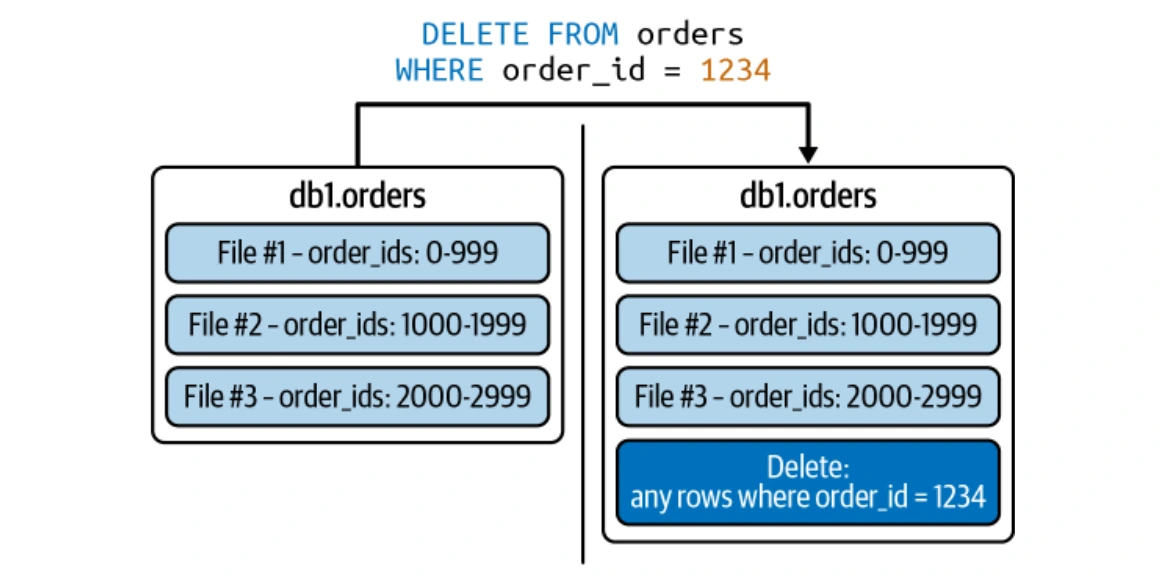
Iceberg menyokong kedua-dua strategi salinan (COW) dan Merge-on-Read (MOR) untuk kemas kini peringkat baris yang cekap.
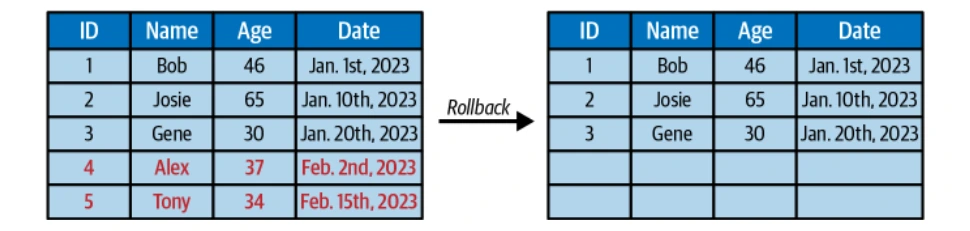
Gambar Iceberg yang tidak berubah membolehkan pertanyaan perjalanan masa dan keupayaan untuk melancarkan kembali ke negeri -negeri meja sebelumnya.

Iceberg menyokong pengubahsuaian skema (menambah, mengeluarkan, atau mengubah lajur) tanpa penulisan semula data, memastikan fleksibiliti dan keserasian.
Bahagian ini meneroka seni bina Iceberg dan bagaimana ia mengatasi batasan Hive.
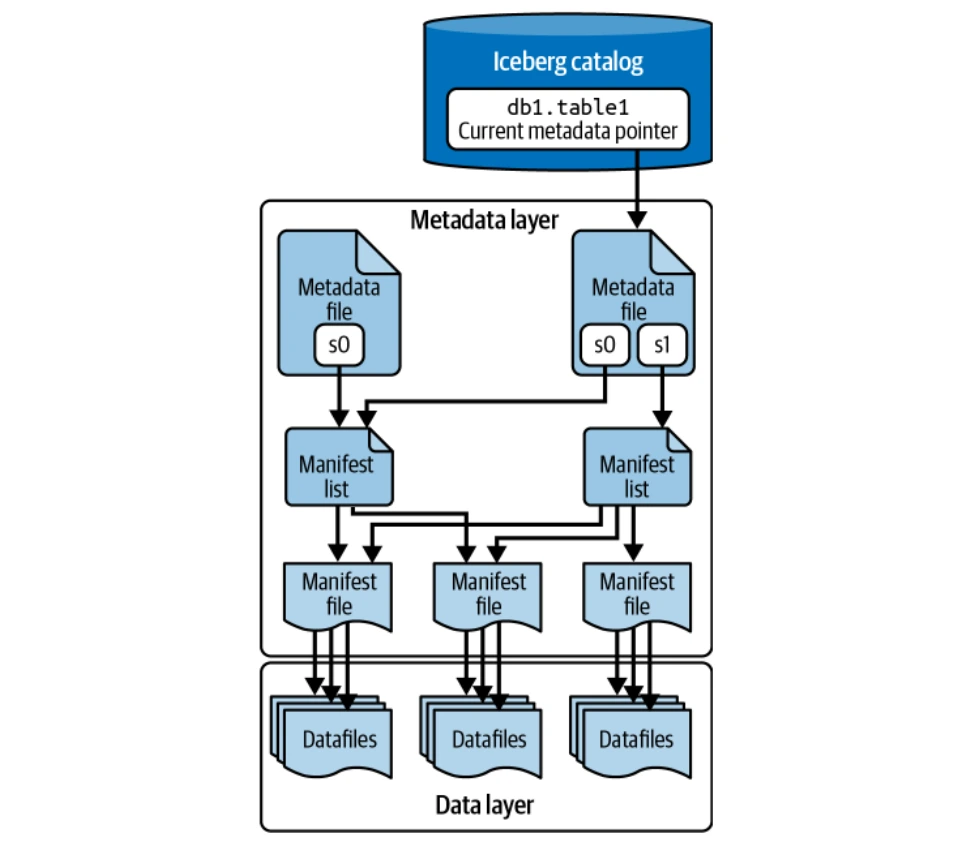
Lapisan data menyimpan data jadual sebenar (fail data dan memadam fail). Ia dihoskan pada sistem fail yang diedarkan (HDFS, S3, dan lain -lain) dan menyokong pelbagai format fail (Parquet, ORC, AVRO). Parquet biasanya disukai untuk penyimpanan kolumnarnya.


Lapisan ini menguruskan semua fail metadata dalam struktur pokok, mengesan fail dan operasi data. Komponen utama termasuk fail manifes, senarai nyata, dan fail metadata. Fail Puffin menyimpan statistik dan indeks lanjutan untuk pengoptimuman pertanyaan.
Katalog bertindak sebagai pendaftaran pusat, menyediakan lokasi fail metadata semasa untuk setiap jadual, memastikan akses yang konsisten untuk semua pembaca dan penulis. Pelbagai backend boleh berfungsi sebagai katalog ais (katalog Hadoop, Metastore Hive, katalog Nessie, katalog AWS Glue).
Iceberg, Parquet, Orc, dan Delta Lake sering digunakan dalam pemprosesan data berskala besar. Iceberg membezakan dirinya sebagai format jadual yang menawarkan jaminan transaksional dan pengoptimuman metadata, tidak seperti parket dan orc yang merupakan format fail. Berbanding dengan Delta Lake, Iceberg cemerlang dalam skema dan evolusi partition.
Apache Iceberg menawarkan pendekatan yang mantap, berskala, dan mesra pengguna kepada Pengurusan Data Lake. Cirinya menjadikannya penyelesaian yang menarik untuk organisasi yang mengendalikan data berskala besar.
Q1. Apa itu gunung es apache? A. Format jadual moden, sumber terbuka meningkatkan prestasi tasik data, konsistensi, dan skalabiliti.
S2. Kenapa gunung es Apache diperlukan? A. Untuk mengatasi batasan Hive dalam pengendalian metadata dan keupayaan transaksional.
Q3. Bagaimanakah Iceberg mengendalikan evolusi skema? A. Ia menyokong perubahan skema tanpa memerlukan penulisan semula jadual penuh.
Q4. Apakah evolusi partition di aisberg? A. Mengubah skim pembahagian tanpa menulis semula data sejarah.
S5. Bagaimanakah aisberg menyokong urus niaga asid? A. Melalui kawalan konvensyen yang optimis, memastikan kemas kini atom.
Atas ialah kandungan terperinci Bagaimana cara menggunakan meja aisberg Apache?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membersihkan pemacu C komputer apabila ia penuh
Bagaimana untuk membersihkan pemacu C komputer apabila ia penuh
 harga mata wang fil harga masa nyata
harga mata wang fil harga masa nyata
 Bagaimana untuk mempertahankan pelayan awan daripada serangan DDoS
Bagaimana untuk mempertahankan pelayan awan daripada serangan DDoS
 Bagaimana untuk memuat turun Binance
Bagaimana untuk memuat turun Binance
 Bagaimana untuk membeli dan menjual Bitcoin di Huobi.com
Bagaimana untuk membeli dan menjual Bitcoin di Huobi.com
 Bagaimana untuk membuka fail iso
Bagaimana untuk membuka fail iso
 Apakah fungsi rangkaian komputer
Apakah fungsi rangkaian komputer
 bagaimana untuk menyembunyikan alamat ip
bagaimana untuk menyembunyikan alamat ip
 Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej
Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



