

Mengoptimumkan Prestasi AI: Panduan untuk Penyebaran LLM yang cekap

Menguasai Model Bahasa Besar (LLM) yang berkhidmat untuk aplikasi AI berprestasi tinggi
Kebangkitan kecerdasan buatan (AI) memerlukan penggunaan LLM yang cekap untuk inovasi dan produktiviti yang optimum. Bayangkan perkhidmatan pelanggan berkuasa AI menjangkakan keperluan anda atau alat analisis data yang menyampaikan pandangan segera. Ini memerlukan menguasai LLM berkhidmat-mengubah LLM menjadi aplikasi yang berprestasi tinggi, masa nyata. Artikel ini meneroka hidangan dan penempatan LLM yang cekap, meliputi platform optimum, strategi pengoptimuman, dan contoh praktikal untuk mewujudkan penyelesaian AI yang kuat dan responsif.

Objektif Pembelajaran Utama:
- Memahami konsep penggunaan LLM dan kepentingannya dalam aplikasi masa nyata.
- Periksa pelbagai rangka kerja LLM, termasuk ciri -ciri dan kes penggunaannya.
- Dapatkan pengalaman praktikal dengan contoh kod untuk menggunakan LLM menggunakan rangka kerja yang berbeza.
- Belajar untuk membandingkan dan penanda aras LLM berkhidmat rangka kerja berdasarkan latensi dan throughput.
- Kenal pasti senario yang ideal untuk menggunakan rangka kerja hidangan LLM tertentu dalam pelbagai aplikasi.
Artikel ini adalah sebahagian daripada Blogathon Sains Data.
Jadual Kandungan:
- Pengenalan
- Pelayan Inference Triton: menyelam yang mendalam
- Mengoptimumkan model pelukan untuk penjanaan teks pengeluaran
- VLLM: Merevolusi pemprosesan batch untuk model bahasa
- DeepSpeed-Mii: Memanfaatkan kelajuan mendalam untuk penggunaan LLM yang cekap
- OpenLLM: Integrasi Rangka Kerja yang Boleh Dihadapkan
- Penggunaan model skala dengan Ray Servent
- Mempercepat kesimpulan dengan ctranslate2
- Perbandingan latensi dan shutput
- Kesimpulan
- Soalan yang sering ditanya
Pelayan Inference Triton: menyelam yang mendalam
Triton Inference Server adalah platform yang mantap untuk menggunakan dan menskalakan model pembelajaran mesin dalam pengeluaran. Dibangunkan oleh Nvidia, ia menyokong Tensorflow, Pytorch, Onnx, dan Backends Custom.
Ciri -ciri utama:
- Pengurusan Model: Memuatkan/Memunggah Dinamik, Kawalan Versi.
- Pengoptimuman Inferensi: Multi-model ensembles, batching, batching dinamik.
- Metrik dan Pembalakan: Integrasi Prometheus untuk Pemantauan.
- Sokongan pemecut: Sokongan GPU, CPU, dan DLA.
Persediaan dan Konfigurasi:
Persediaan Triton boleh menjadi rumit, memerlukan Docker dan Kubernetes. Walau bagaimanapun, NVIDIA menyediakan dokumentasi komprehensif dan sokongan komuniti.
Gunakan Kes:
Ideal untuk penyebaran besar-besaran yang menuntut prestasi, skalabilitas, dan sokongan pelbagai rangka kerja.
Kod Demo dan Penjelasan: (Kod tetap sama seperti dalam input asal)
Mengoptimumkan model pelukan untuk penjanaan teks pengeluaran
Bahagian ini memberi tumpuan kepada menggunakan model Huggingface untuk penjanaan teks, menekankan sokongan asli tanpa penyesuai tambahan. Ia menggunakan model sharding untuk pemprosesan selari, penimbal untuk pengurusan permintaan, dan batching untuk kecekapan. GRPC memastikan komunikasi cepat antara komponen.
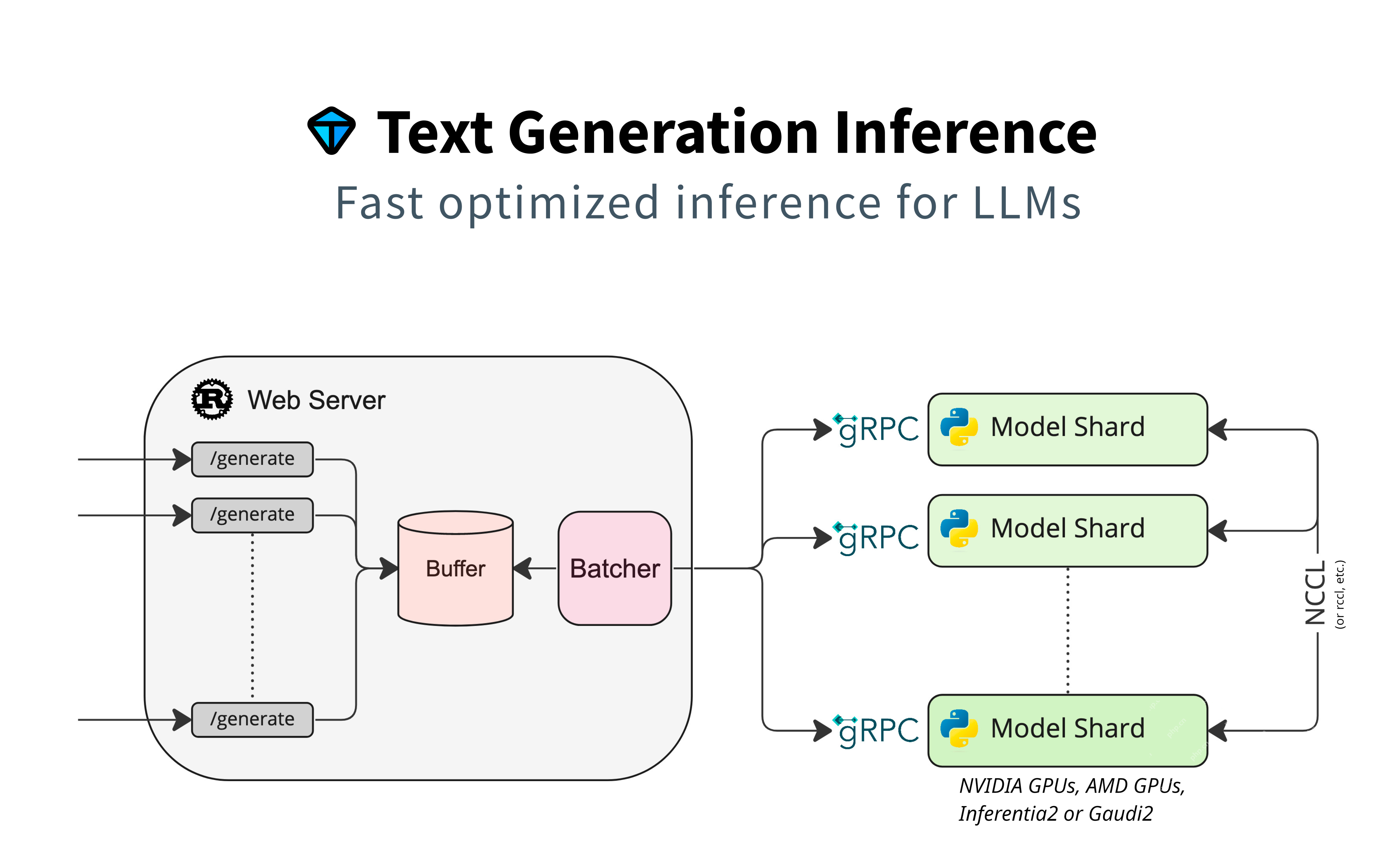
Ciri -ciri utama:
- Keramahan Pengguna: Integrasi Huggingface yang lancar.
- Penyesuaian: Membolehkan konfigurasi penalaan dan adat.
- Sokongan Transformers: Memanfaatkan Perpustakaan Transformers.
Gunakan Kes:
Sesuai untuk aplikasi yang memerlukan integrasi model Huggingface langsung, seperti chatbots dan penjanaan kandungan.
Kod Demo dan Penjelasan: (Kod tetap sama seperti dalam input asal)
VLLM: Merevolusi pemprosesan batch untuk model bahasa
VLLM mengutamakan kelajuan dalam penghantaran segera, mengoptimumkan latensi dan throughput. Ia menggunakan operasi vektor dan pemprosesan selari untuk penjanaan teks yang cekap.

Ciri -ciri utama:
- Prestasi Tinggi: Dioptimumkan untuk latensi rendah dan throughput yang tinggi.
- Pemprosesan Batch: Pengendalian yang cekap dari permintaan batch.
- Skalabiliti: Sesuai untuk penyebaran besar-besaran.
Gunakan Kes:
Terbaik untuk aplikasi kritikal laju, seperti terjemahan masa nyata dan sistem AI interaktif.
Kod Demo dan Penjelasan: (Kod tetap sama seperti dalam input asal)
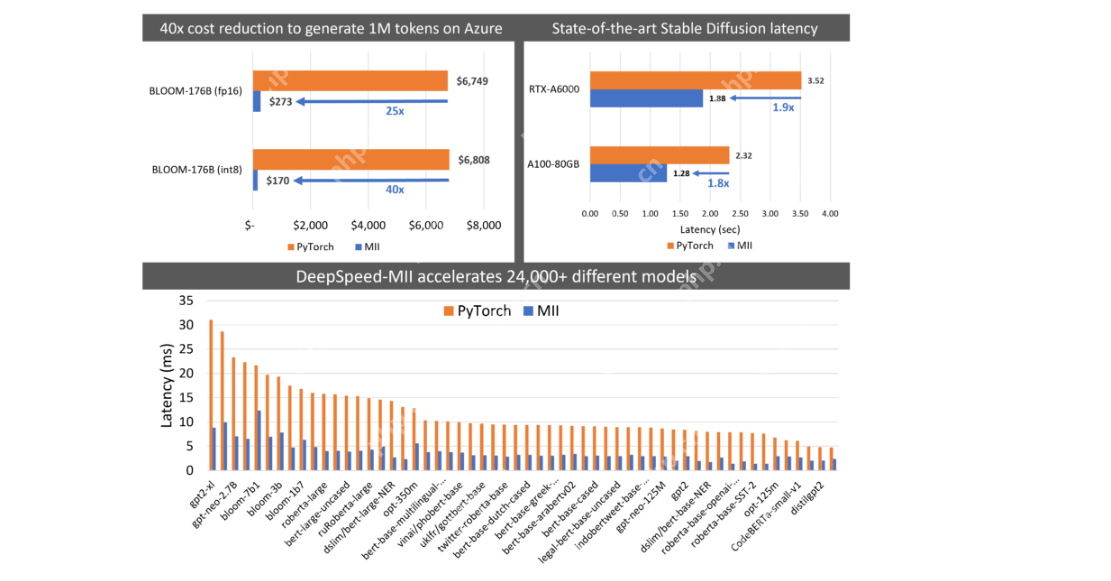
DeepSpeed-Mii: Memanfaatkan Kelajuan Deepspeed untuk Penyebaran LLM Cekap
DeepSpeed-MII adalah untuk pengguna yang berpengalaman dengan kelajuan yang mendalam, memberi tumpuan kepada penggunaan LLM yang cekap dan skala melalui model paralelisme, kecekapan memori, dan pengoptimuman kelajuan.

Ciri -ciri utama:
- Kecekapan: Memori dan kecekapan pengiraan.
- Skalabiliti: Mengendalikan model yang sangat besar.
- Integrasi: Lancar dengan aliran kerja yang mendalam.
Gunakan Kes:
Ideal untuk penyelidik dan pemaju yang biasa dengan DeepSpeed, mengutamakan latihan dan penempatan prestasi tinggi.
Kod Demo dan Penjelasan: (Kod tetap sama seperti dalam input asal)
OpenLLM: Integrasi Penyesuai Fleksibel
OpenLLM menghubungkan penyesuai ke model teras dan menggunakan ejen Huggingface. Ia menyokong pelbagai kerangka, termasuk pytorch.
Ciri -ciri utama:
- Rangka Kerja Agnostik: Menyokong pelbagai kerangka pembelajaran mendalam.
- Integrasi Ejen: Leverages Huggingface Ejen.
- Sokongan Penyesuai: Integrasi fleksibel dengan penyesuai model.
Gunakan Kes:
Hebat untuk projek yang memerlukan fleksibiliti kerangka dan penggunaan alat peluh yang luas.
Kod Demo dan Penjelasan: (Kod tetap sama seperti dalam input asal)

Memanfaatkan Ray berkhidmat untuk penggunaan model berskala
Ray Server menyediakan saluran paip yang stabil dan penggunaan fleksibel untuk projek -projek matang yang memerlukan penyelesaian yang boleh dipercayai dan berskala.
Ciri -ciri utama:
- Fleksibiliti: Menyokong pelbagai arkitek penempatan.
- Skalabiliti: Mengendalikan aplikasi beban tinggi.
- Integrasi: Bekerja dengan baik dengan ekosistem Ray.
Gunakan Kes:
Ideal untuk projek -projek yang ditubuhkan yang memerlukan infrastruktur berkhidmat yang mantap dan berskala.
Kod Demo dan Penjelasan: (Kod tetap sama seperti dalam input asal)
Mempercepatkan kesimpulan dengan ctranslate2
CTranslate2 mengutamakan kelajuan, terutamanya untuk kesimpulan berasaskan CPU. Ia dioptimumkan untuk model terjemahan dan menyokong pelbagai seni bina.
Ciri -ciri utama:
- Pengoptimuman CPU: Prestasi tinggi untuk kesimpulan CPU.
- Keserasian: Menyokong seni bina model popular.
- Ringan: Ketergantungan yang minimum.
Gunakan Kes:
Sesuai untuk aplikasi yang mengutamakan kelajuan dan kecekapan CPU, seperti perkhidmatan terjemahan.
Kod Demo dan Penjelasan: (Kod tetap sama seperti dalam input asal)

Perbandingan latensi dan shutput
(Jadual dan imej membandingkan latensi dan throughput tetap sama seperti dalam input asal)
Kesimpulan
Hidangan LLM yang cekap adalah penting untuk aplikasi AI yang responsif. Artikel ini meneroka pelbagai platform, masing -masing dengan kelebihan yang unik. Pilihan terbaik bergantung kepada keperluan khusus.
Takeaways Kunci:
- Model berkhidmat menggunakan model terlatih untuk kesimpulan.
- Platform yang berbeza cemerlang dalam aspek prestasi yang berbeza.
- Pemilihan kerangka bergantung pada kes penggunaan.
- Sesetengah rangka kerja lebih baik untuk penyebaran berskala dalam projek yang matang.
Soalan Lazim:
(Soalan Lazim tetap sama seperti dalam input asal)
Nota: Media yang ditunjukkan dalam artikel ini tidak dimiliki oleh [menyebutkan entiti yang berkaitan] dan digunakan mengikut budi bicara penulis.
Atas ialah kandungan terperinci Mengoptimumkan Prestasi AI: Panduan untuk Penyebaran LLM yang cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
Artikel ini membandingkan chatbots AI seperti Chatgpt, Gemini, dan Claude, yang memberi tumpuan kepada ciri -ciri unik mereka, pilihan penyesuaian, dan prestasi dalam pemprosesan bahasa semula jadi dan kebolehpercayaan.
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Artikel ini membincangkan pembantu penulisan AI terkemuka seperti Grammarly, Jasper, Copy.ai, WriteSonic, dan Rytr, yang memberi tumpuan kepada ciri -ciri unik mereka untuk penciptaan kandungan. Ia berpendapat bahawa Jasper cemerlang dalam pengoptimuman SEO, sementara alat AI membantu mengekalkan nada terdiri
 Sistem Rag Agentik 7 Teratas untuk Membina Ejen AI
Mar 31, 2025 pm 04:25 PM
Sistem Rag Agentik 7 Teratas untuk Membina Ejen AI
Mar 31, 2025 pm 04:25 PM
2024 menyaksikan peralihan daripada menggunakan LLMS untuk penjanaan kandungan untuk memahami kerja dalaman mereka. Eksplorasi ini membawa kepada penemuan agen AI - sistem pengendalian sistem autonomi dan keputusan dengan intervensi manusia yang minimum. Buildin
 Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Artikel ini mengulas penjana suara AI atas seperti Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, dan Descript, memberi tumpuan kepada ciri -ciri mereka, kualiti suara, dan kesesuaian untuk keperluan yang berbeza.
 Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Menjual Strategi AI kepada Pekerja: Manifesto CEO Shopify
Apr 10, 2025 am 11:19 AM
Memo CEO Shopify Tobi Lütke baru -baru ini dengan berani mengisytiharkan penguasaan AI sebagai harapan asas bagi setiap pekerja, menandakan peralihan budaya yang signifikan dalam syarikat. Ini bukan trend seketika; Ini adalah paradigma operasi baru yang disatukan ke p
