

ExtJS中文乱码之GBK格式编码解决方案及代码_extjs

这几天做后台看了一些Ext的知识,在切入工作项目的时候出现了乱码情况,所以就总结了这篇ExtJS中文乱码之GBK格式编码解决办法的文章,作为记录。
1、具体情况:
在引入:
02.
03.
04.
05.
后,写了一个简单的例子:
结果出现:
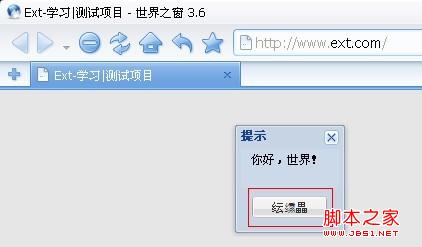
2、页面的编码是GBK,具体代码如下:
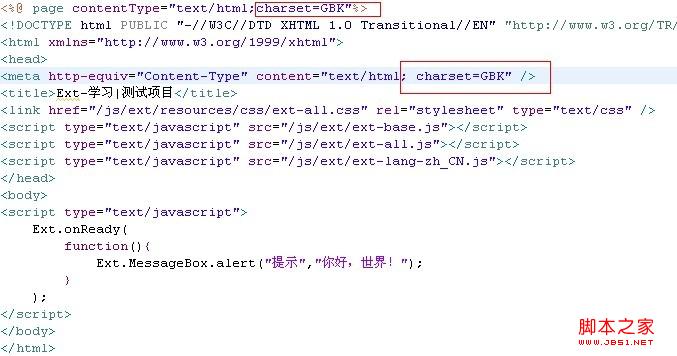
3、解决办法:
(1)把页面的编码定义为UFT-8后正常,但项目指定编码是UTF-8,所以不能采用这个思路。
(2)把引入的资源文件(/js/ext/ext-lang-zh_CN.js)改变为合适的编码,具体如下:
A 、用EditPlus打开这个js文件,选择另存为,如下图:
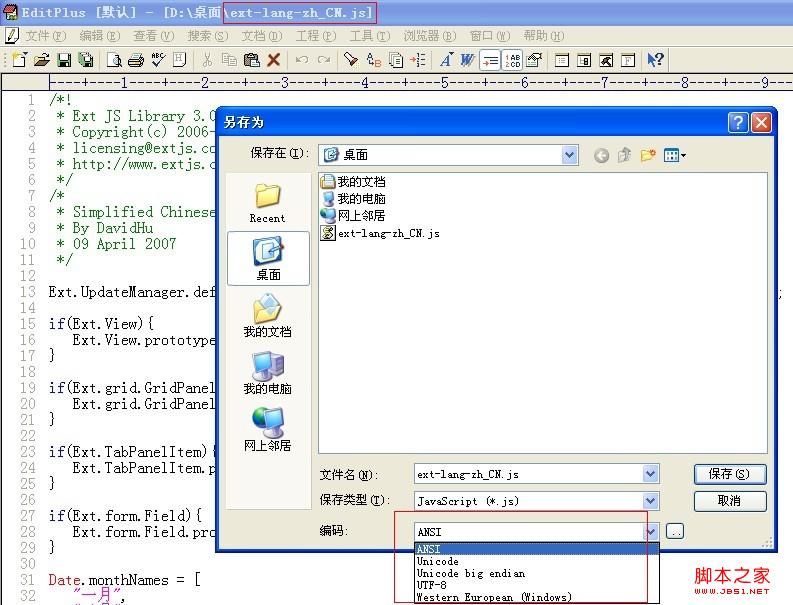
B、可以看到编码选项一共有5项,但是都不是我们需要的,我们点击后面的 更多的小按钮(上面有两个点的不起眼的哪个按钮)
看到下图后,选择图中的编码并确认:

然后,替换工程里面的js,再测试:
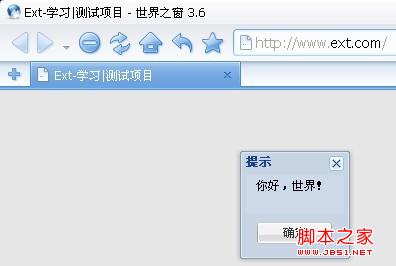
可以看到,乱码问题已经解决,文字显示正常了。

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1392
1392
 52
52

 Kaedah untuk menyelesaikan masalah aksara Cina bercelaru dalam PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Kaedah untuk menyelesaikan masalah aksara Cina bercelaru dalam PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Kaedah untuk menyelesaikan masalah bahasa Cina PHPDompdf PHPDompdf ialah alat untuk menukar dokumen HTML kepada fail PDF Ia berkuasa dan mudah digunakan. Walau bagaimanapun, semasa memproses kandungan Cina, anda kadangkala menghadapi masalah aksara Cina yang bercelaru. Artikel ini akan memperkenalkan beberapa kaedah untuk menyelesaikan masalah aksara Cina bercelaru dalam PHPDompdf dan memberikan contoh kod khusus. 1. Apabila menggunakan fail fon untuk memproses kandungan Cina, masalah biasa ialah Dompdf tidak menyokong kandungan Cina secara lalai.
 11 teknik pengekodan ciri klasifikasi biasa
Apr 12, 2023 pm 12:16 PM
11 teknik pengekodan ciri klasifikasi biasa
Apr 12, 2023 pm 12:16 PM
Algoritma pembelajaran mesin hanya menerima input berangka, jadi jika kami menemui ciri kategori, kami akan mengekodkan ciri kategori Artikel ini meringkaskan 11 kaedah pengekodan pembolehubah kategori biasa. 1. ONE HOT ENCOD Kaedah pengekodan yang paling popular dan biasa digunakan ialah One Hot Enoding. Pembolehubah tunggal dengan n pemerhatian dan d nilai berbeza ditukar kepada d pembolehubah binari dengan n pemerhatian, setiap pembolehubah binari dikenal pasti dengan sedikit (0, 1). Contohnya: pelaksanaan paling mudah selepas pengekodan ialah menggunakan get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2, panda,
 Berapa banyak bait yang diduduki oleh aksara Cina yang dikodkan utf8?
Feb 21, 2023 am 11:40 AM
Berapa banyak bait yang diduduki oleh aksara Cina yang dikodkan utf8?
Feb 21, 2023 am 11:40 AM
Aksara Cina yang dikodkan UTF8 menduduki 3 bait. Dalam pengekodan UTF-8, satu aksara Cina bersamaan dengan tiga bait, dan satu tanda baca bahasa Cina menduduki tiga bait manakala dalam pengekodan Unicode, satu aksara Cina (termasuk bahasa Cina tradisional) adalah sama dengan dua bait; UTF-8 menggunakan 1~4 bait untuk mengekod setiap aksara Satu aksara AS-ASCIl hanya memerlukan 1 bait untuk mengekod Latin, Yunani, Cyrillic, Armenia dan Ibrani dengan tanda diakritik , Arab, Syria dan huruf lain pengekodan.
 Penyelesaian muktamad kepada masalah aksara Cina yang kacau dalam PyCharm
Jan 27, 2024 am 08:00 AM
Penyelesaian muktamad kepada masalah aksara Cina yang kacau dalam PyCharm
Jan 27, 2024 am 08:00 AM
Kaedah muktamad untuk menyelesaikan masalah aksara Cina yang kacau dalam PyCharm memerlukan contoh kod khusus Pengenalan: PyCharm, sebagai persekitaran pembangunan bersepadu (IDE) Python yang biasa digunakan, mempunyai fungsi yang berkuasa dan antara muka pengguna yang mesra, serta disukai dan digunakan oleh. majoriti pemaju. Walau bagaimanapun, apabila PyCharm memproses aksara Cina, kadangkala ia mungkin menghadapi aksara bercelaru, yang menyebabkan masalah tertentu dalam pembangunan dan penyahpepijatan. Artikel ini akan memperkenalkan cara menyelesaikan masalah bercelaru bahasa Cina dalam PyCharm dan memberikan contoh kod khusus. 1. Sediakan projek
 Punca dan penyelesaian biasa untuk aksara Cina yang kacau dalam pemasangan MySQL
Mar 02, 2024 am 09:00 AM
Punca dan penyelesaian biasa untuk aksara Cina yang kacau dalam pemasangan MySQL
Mar 02, 2024 am 09:00 AM
Penyebab dan penyelesaian biasa untuk aksara Cina yang kacau dalam pemasangan MySQL MySQL ialah sistem pengurusan pangkalan data hubungan yang biasa digunakan, tetapi anda mungkin menghadapi masalah aksara Cina yang kacau semasa digunakan, yang membawa masalah kepada pembangun dan pentadbir sistem. Masalah aksara Cina bercelaru terutamanya disebabkan oleh tetapan set aksara yang salah, set aksara yang tidak konsisten antara pelayan pangkalan data dan pelanggan, dsb. Artikel ini akan memperkenalkan secara terperinci punca dan penyelesaian biasa aksara Cina yang kacau dalam pemasangan MySQL untuk membantu semua orang menyelesaikan masalah ini dengan lebih baik. 1. Sebab biasa: tetapan set watak
 Graf pengetahuan: rakan kongsi yang ideal untuk model besar
Jan 29, 2024 am 09:21 AM
Graf pengetahuan: rakan kongsi yang ideal untuk model besar
Jan 29, 2024 am 09:21 AM
Model bahasa besar (LLM) mempunyai keupayaan untuk menghasilkan teks yang lancar dan koheren, membawa prospek baharu ke bidang seperti perbualan kecerdasan buatan dan penulisan kreatif. Walau bagaimanapun, LLM juga mempunyai beberapa had utama. Pertama, pengetahuan mereka terhad kepada corak yang diiktiraf daripada data latihan, kurang pemahaman sebenar tentang dunia. Kedua, kemahiran menaakul adalah terhad dan tidak boleh membuat inferens logik atau menggabungkan fakta daripada pelbagai sumber data. Apabila berhadapan dengan soalan yang lebih kompleks dan terbuka, jawapan LLM mungkin menjadi tidak masuk akal atau bercanggah, dikenali sebagai "ilusi." Oleh itu, walaupun LLM sangat berguna dalam beberapa aspek, ia masih mempunyai had tertentu apabila berhadapan dengan masalah kompleks dan situasi dunia sebenar. Untuk merapatkan jurang ini, sistem penjanaan dipertingkatkan semula (RAG) telah muncul dalam beberapa tahun kebelakangan ini
 Apa yang perlu dilakukan jika ajax menghantar aksara Cina yang kacau
Nov 15, 2023 am 10:42 AM
Apa yang perlu dilakukan jika ajax menghantar aksara Cina yang kacau
Nov 15, 2023 am 10:42 AM
Penyelesaian untuk ajax untuk menghantar aksara Cina yang kacau: 1. Tetapkan kaedah pengekodan bersatu 2. Pengekodan bahagian pelayan 4. Tetapkan pengepala respons HTTP; Pengenalan terperinci: 1. Tetapkan kaedah pengekodan bersatu untuk memastikan pelayan dan klien menggunakan kaedah pengekodan yang sama Dalam keadaan biasa, UTF-8 ialah kaedah pengekodan yang biasa digunakan kerana ia boleh menyokong pelbagai bahasa dan set aksara; 2 , Pengekodan bahagian pelayan Di bahagian pelayan, pastikan data Cina dikodkan dalam kaedah pengekodan yang betul dan kemudian dihantar kepada pelanggan, dsb.
 Beberapa kaedah pengekodan biasa
Oct 24, 2023 am 10:09 AM
Beberapa kaedah pengekodan biasa
Oct 24, 2023 am 10:09 AM
Kaedah pengekodan biasa termasuk pengekodan ASCII, pengekodan Unikod, pengekodan UTF-8, pengekodan UTF-16, pengekodan GBK, dsb. Pengenalan terperinci: 1. Pengekodan ASCII ialah standard pengekodan aksara yang paling awal, menggunakan nombor perduaan 7-bit untuk mewakili 128 aksara, termasuk huruf Inggeris, nombor, tanda baca, aksara kawalan, dsb. 2. Pengekodan Unikod ialah kaedah yang digunakan untuk mewakili semua aksara di dunia Kaedah pengekodan standard aksara, yang memberikan titik kod digital yang unik kepada setiap aksara 3. Pengekodan UTF-8, dsb.
