

Javascript图像处理—虚拟边缘介绍及使用方法_javascript技巧

上一篇文章,我们来给矩阵添加一些常用方法,这篇文章将讲解图像的虚拟边缘。
虚拟边缘
虚拟边缘就是按照一定映射关系,给图像添加边缘。
那么虚拟边缘有什么用呢?比如可以很容易做一个倒影的效果:

当然这只是附带效果了,虚拟边缘主要用在图像卷积运算(例如平滑操作)时候,由于卷积运算的特点,需要将图片扩大才能对边角进行卷积运算,这时候就需要对图片进行预处理,添加虚拟边缘。
说白了,就是在一些图片处理前进行预处理。
边缘类型
这里参考OpenCV相关文档的边缘描述:
/*
Various border types, image boundaries are denoted with '|'
* BORDER_REPLICATE: aaaaaa|abcdefgh|hhhhhhh
* BORDER_REFLECT: fedcba|abcdefgh|hgfedcb
* BORDER_REFLECT_101: gfedcb|abcdefgh|gfedcba
* BORDER_WRAP: cdefgh|abcdefgh|abcdefg
* BORDER_CONSTANT: iiiiii|abcdefgh|iiiiiii with some specified 'i'
*/
举个例子BODER_REFLECT就是对于某一行或某一列像素点:
abcdefgh
其左的虚拟边缘对应为fedcba,右边对应为hgfedcb,也就是反射映射。上图就是通过对图片底部进行添加BORDER_REFLECT类型的虚拟边缘得到的。
而BORDER_CONSTANT则是所有边缘都是固定值i。
实现
因为BORDER_CONSTANT比较特殊,所以和其他类型分开处理。
function copyMakeBorder(__src, __top, __left, __bottom, __right, __borderType, __value){
if(__src.type != "CV_RGBA"){
console.error("不支持类型!");
}
if(__borderType === CV_BORDER_CONSTANT){
return copyMakeConstBorder_8U(__src, __top, __left, __bottom, __right, __value);
}else{
return copyMakeBorder_8U(__src, __top, __left, __bottom, __right, __borderType);
}
};
这个函数接受一个输入矩阵src,每个方向要添加的像素大小top,left,bottom,right,边缘的类型borderType,还有一个数组value,即如果是常数边缘时候添加的常数值。
然后我们引入一个边缘的映射关系函数borderInterpolate。
function borderInterpolate(__p, __len, __borderType){
if(__p = __len){
switch(__borderType){
case CV_BORDER_REPLICATE:
__p = __p break;
case CV_BORDER_REFLECT:
case CV_BORDER_REFLECT_101:
var delta = __borderType == CV_BORDER_REFLECT_101;
if(__len == 1)
return 0;
do{
if(__p __p = -__p - 1 + delta;
else
__p = __len - 1 - (__p - __len) - delta;
}while(__p = __len)
break;
case CV_BORDER_WRAP:
if(__p __p -= ((__p - __len + 1) / __len) * __len;
if(__p >= __len)
__p %= __len;
break;
case CV_BORDER_CONSTANT:
__p = -1;
default:
error(arguments.callee, UNSPPORT_BORDER_TYPE/* {line} */);
}
}
return __p;
};
这个函数的意义是对于原长度为len的某一行或者某一列的虚拟像素点p(p一般是负数或者大于或等于该行原长度的数,负数则表示该行左边的像素点,大于或等于原长度则表示是右边的像素点),映射成这一行的哪一个像素点。我们拿CV_BORDER_REPLICATE分析一下,其表达式是:
__p = __p 也就是说p为负数时(也就是左边)的时候映射为0,否则映射成len - 1。
然后我们来实现copyMakeBorder_8U函数:
function copyMakeBorder_8U(__src, __top, __left, __bottom, __right, __borderType){
var i, j;
var width = __src.col,
height = __src.row;
var top = __top,
left = __left || __top,
right = __right || left,
bottom = __bottom || top,
dstWidth = width + left + right,
dstHeight = height + top + bottom,
borderType = borderType || CV_BORDER_REFLECT;
var buffer = new ArrayBuffer(dstHeight * dstWidth * 4),
tab = new Uint32Array(left + right);
for(i = 0; i tab[i] = borderInterpolate(i - left, width, __borderType);
}
for(i = 0; i tab[i + left] = borderInterpolate(width + i, width, __borderType);
}
var tempArray, data;
for(i = 0; i tempArray = new Uint32Array(buffer, (i + top) * dstWidth * 4, dstWidth);
data = new Uint32Array(__src.buffer, i * width * 4, width);
for(j = 0; j tempArray[j] = data[tab[j]];
for(j = 0; j tempArray[j + width + left] = data[tab[j + left]];
tempArray.set(data, left);
}
var allArray = new Uint32Array(buffer);
for(i = 0; i j = borderInterpolate(i - top, height, __borderType);
tempArray = new Uint32Array(buffer, i * dstWidth * 4, dstWidth);
tempArray.set(allArray.subarray((j + top) * dstWidth, (j + top + 1) * dstWidth));
}
for(i = 0; i j = borderInterpolate(i + height, height, __borderType);
tempArray = new Uint32Array(buffer, (i + top + height) * dstWidth * 4, dstWidth);
tempArray.set(allArray.subarray((j + top) * dstWidth, (j + top + 1) * dstWidth));
}
return new Mat(dstHeight, dstWidth, new Uint8ClampedArray(buffer));
}
这里需要解释下,边缘的复制顺序是:先对每行的左右进行扩展,然后在此基础上进行上下扩展,如图所示。
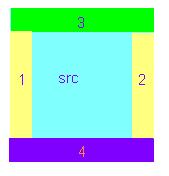
然后我们根据ArrayBuffer的性质,将数据转成无符号32位整数来操作,这样每个操作单位就对应了每个像素点了。什么意思?
比如对于某个像素点:RGBA,由于某个通道是用无符号8为整数来存储的,所以实际上一个像素点则对应了32位的存储大小,由于ArrayBuffer的性质,可以将数据转成任意类型来处理,这样我们就可以通过转成Uint32Array类型,将数据变成每个像素点的数据数组。
那么copyMakeConstBorder_8U就比较容易实现了:
function copyMakeConstBorder_8U(__src, __top, __left, __bottom, __right, __value){
var i, j;
var width = __src.col,
height = __src.row;
var top = __top,
left = __left || __top,
right = __right || left,
bottom = __bottom || top,
dstWidth = width + left + right,
dstHeight = height + top + bottom,
value = __value || [0, 0, 0, 255];
var constBuf = new ArrayBuffer(dstWidth * 4),
constArray = new Uint8ClampedArray(constBuf);
buffer = new ArrayBuffer(dstHeight * dstWidth * 4);
for(i = 0; i for( j = 0; j constArray[i * 4 + j] = value[j];
}
}
constArray = new Uint32Array(constBuf);
var tempArray;
for(i = 0; i tempArray = new Uint32Array(buffer, (i + top) * dstWidth * 4, left);
tempArray.set(constArray.subarray(0, left));
tempArray = new Uint32Array(buffer, ((i + top + 1) * dstWidth - right) * 4, right);
tempArray.set(constArray.subarray(0, right));
tempArray = new Uint32Array(buffer, ((i + top) * dstWidth + left) * 4, width);
tempArray.set(new Uint32Array(__src.buffer, i * width * 4, width));
}
for(i = 0; i tempArray = new Uint32Array(buffer, i * dstWidth * 4, dstWidth);
tempArray.set(constArray);
}
for(i = 0; i tempArray = new Uint32Array(buffer, (i + top + height) * dstWidth * 4, dstWidth);
tempArray.set(constArray);
}
return new Mat(dstHeight, dstWidth, new Uint8ClampedArray(buffer));
}
效果图
CV_BORDER_REPLICATE

CV_BORDER_REFLECT

CV_BORDER_WRAP

CV_BORDER_CONSTANT


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Bagaimanakah jarak Wasserstein digunakan dalam tugas pemprosesan imej?
Jan 23, 2024 am 10:39 AM
Bagaimanakah jarak Wasserstein digunakan dalam tugas pemprosesan imej?
Jan 23, 2024 am 10:39 AM
Jarak Wasserstein, juga dikenali sebagai Jarak EarthMover (EMD), ialah metrik yang digunakan untuk mengukur perbezaan antara dua taburan kebarangkalian. Berbanding dengan perbezaan tradisional KL atau perbezaan JS, jarak Wasserstein mengambil kira maklumat struktur antara pengedaran dan oleh itu mempamerkan prestasi yang lebih baik dalam banyak tugas pemprosesan imej. Dengan mengira kos pengangkutan minimum antara dua pengedaran, jarak Wasserstein dapat mengukur jumlah kerja minimum yang diperlukan untuk mengubah satu pengedaran kepada yang lain. Metrik ini mampu menangkap perbezaan geometri antara taburan, dengan itu memainkan peranan penting dalam tugas seperti penjanaan imej dan pemindahan gaya. Oleh itu, jarak Wasserstein menjadi konsep
 Analisis mendalam tentang prinsip kerja dan ciri-ciri model Pengubah Penglihatan (VIT).
Jan 23, 2024 am 08:30 AM
Analisis mendalam tentang prinsip kerja dan ciri-ciri model Pengubah Penglihatan (VIT).
Jan 23, 2024 am 08:30 AM
VisionTransformer (VIT) ialah model klasifikasi imej berasaskan Transformer yang dicadangkan oleh Google. Tidak seperti model CNN tradisional, VIT mewakili imej sebagai jujukan dan mempelajari struktur imej dengan meramalkan label kelas imej. Untuk mencapai matlamat ini, VIT membahagikan imej input kepada berbilang patch dan menggabungkan piksel dalam setiap patch melalui saluran dan kemudian melakukan unjuran linear untuk mencapai dimensi input yang dikehendaki. Akhir sekali, setiap tampalan diratakan menjadi satu vektor, membentuk urutan input. Melalui mekanisme perhatian kendiri Transformer, VIT dapat menangkap hubungan antara tampalan yang berbeza dan melakukan pengekstrakan ciri dan ramalan klasifikasi yang berkesan. Perwakilan imej bersiri ini ialah
 Cara menggunakan teknologi AI untuk memulihkan foto lama (dengan contoh dan analisis kod)
Jan 24, 2024 pm 09:57 PM
Cara menggunakan teknologi AI untuk memulihkan foto lama (dengan contoh dan analisis kod)
Jan 24, 2024 pm 09:57 PM
Pemulihan foto lama ialah kaedah menggunakan teknologi kecerdasan buatan untuk membaiki, menambah baik dan menambah baik foto lama. Menggunakan penglihatan komputer dan algoritma pembelajaran mesin, teknologi ini secara automatik boleh mengenal pasti dan membaiki kerosakan dan kecacatan pada foto lama, menjadikannya kelihatan lebih jelas, lebih semula jadi dan lebih realistik. Prinsip teknikal pemulihan foto lama terutamanya merangkumi aspek-aspek berikut: 1. Penyahnosian dan penambahbaikan imej Apabila memulihkan foto lama, foto itu perlu dibunyikan dan dipertingkatkan terlebih dahulu. Algoritma dan penapis pemprosesan imej, seperti penapisan min, penapisan Gaussian, penapisan dua hala, dsb., boleh digunakan untuk menyelesaikan masalah bunyi dan bintik warna, dengan itu meningkatkan kualiti foto. 2. Pemulihan dan pembaikan imej Dalam foto lama, mungkin terdapat beberapa kecacatan dan kerosakan, seperti calar, retak, pudar, dsb. Masalah ini boleh diselesaikan dengan algoritma pemulihan dan pembaikan imej
 Aplikasi teknologi AI dalam pembinaan semula resolusi super imej
Jan 23, 2024 am 08:06 AM
Aplikasi teknologi AI dalam pembinaan semula resolusi super imej
Jan 23, 2024 am 08:06 AM
Pembinaan semula imej resolusi super ialah proses menjana imej resolusi tinggi daripada imej resolusi rendah menggunakan teknik pembelajaran mendalam seperti rangkaian neural convolutional (CNN) dan rangkaian adversarial generatif (GAN). Matlamat kaedah ini adalah untuk meningkatkan kualiti dan perincian imej dengan menukar imej resolusi rendah kepada imej resolusi tinggi. Teknologi ini mempunyai aplikasi yang luas dalam banyak bidang, seperti pengimejan perubatan, kamera pengawasan, imej satelit, dsb. Melalui pembinaan semula imej resolusi super, kami boleh mendapatkan imej yang lebih jelas dan terperinci, membantu menganalisis dan mengenal pasti sasaran dan ciri dalam imej dengan lebih tepat. Kaedah pembinaan semula Kaedah pembinaan semula imej resolusi super secara amnya boleh dibahagikan kepada dua kategori: kaedah berasaskan interpolasi dan kaedah berasaskan pembelajaran mendalam. 1) Kaedah berasaskan interpolasi Pembinaan semula imej resolusi super berdasarkan interpolasi
 Pembangunan Java: bagaimana untuk melaksanakan pengecaman dan pemprosesan imej
Sep 21, 2023 am 08:39 AM
Pembangunan Java: bagaimana untuk melaksanakan pengecaman dan pemprosesan imej
Sep 21, 2023 am 08:39 AM
Pembangunan Java: Panduan Praktikal untuk Pengecaman dan Pemprosesan Imej Abstrak: Dengan perkembangan pesat penglihatan komputer dan kecerdasan buatan, pengecaman dan pemprosesan imej memainkan peranan penting dalam pelbagai bidang. Artikel ini akan memperkenalkan cara menggunakan bahasa Java untuk melaksanakan pengecaman dan pemprosesan imej, serta menyediakan contoh kod khusus. 1. Prinsip asas pengecaman imej Pengecaman imej merujuk kepada penggunaan teknologi komputer untuk menganalisis dan memahami imej untuk mengenal pasti objek, ciri atau kandungan dalam imej. Sebelum melakukan pengecaman imej, kita perlu memahami beberapa teknik pemprosesan imej asas, seperti yang ditunjukkan dalam rajah
 Nota kajian PHP: pengecaman muka dan pemprosesan imej
Oct 08, 2023 am 11:33 AM
Nota kajian PHP: pengecaman muka dan pemprosesan imej
Oct 08, 2023 am 11:33 AM
Nota kajian PHP: Pengecaman muka dan pemprosesan imej Prakata: Dengan perkembangan teknologi kecerdasan buatan, pengecaman muka dan pemprosesan imej telah menjadi topik hangat. Dalam aplikasi praktikal, pengecaman muka dan pemprosesan imej kebanyakannya digunakan dalam pemantauan keselamatan, buka kunci muka, perbandingan kad, dsb. Sebagai bahasa skrip sebelah pelayan yang biasa digunakan, PHP juga boleh digunakan untuk melaksanakan fungsi yang berkaitan dengan pengecaman muka dan pemprosesan imej. Artikel ini akan membawa anda melalui pengecaman muka dan pemprosesan imej dalam PHP, dengan contoh kod khusus. 1. Pengecaman muka dalam PHP Pengecaman muka ialah a
 Cara menangani pemprosesan imej dan isu reka bentuk antara muka grafik dalam pembangunan C#
Oct 08, 2023 pm 07:06 PM
Cara menangani pemprosesan imej dan isu reka bentuk antara muka grafik dalam pembangunan C#
Oct 08, 2023 pm 07:06 PM
Cara menangani pemprosesan imej dan isu reka bentuk antara muka grafik dalam pembangunan C# memerlukan contoh kod khusus Pengenalan: Dalam pembangunan perisian moden, pemprosesan imej dan reka bentuk antara muka grafik adalah keperluan biasa. Sebagai bahasa pengaturcaraan peringkat tinggi tujuan umum, C# mempunyai pemprosesan imej yang berkuasa dan keupayaan reka bentuk antara muka grafik. Artikel ini akan berdasarkan C#, membincangkan cara menangani pemprosesan imej dan isu reka bentuk antara muka grafik, dan memberikan contoh kod terperinci. 1. Isu pemprosesan imej: Bacaan dan paparan imej: Dalam C#, bacaan dan paparan imej adalah operasi asas. Boleh digunakan.N
 Algoritma Ciri Invarian Skala (SIFT).
Jan 22, 2024 pm 05:09 PM
Algoritma Ciri Invarian Skala (SIFT).
Jan 22, 2024 pm 05:09 PM
Algoritma Scale Invariant Feature Transform (SIFT) ialah algoritma pengekstrakan ciri yang digunakan dalam bidang pemprosesan imej dan penglihatan komputer. Algoritma ini telah dicadangkan pada tahun 1999 untuk meningkatkan pengecaman objek dan prestasi pemadanan dalam sistem penglihatan komputer. Algoritma SIFT adalah teguh dan tepat dan digunakan secara meluas dalam pengecaman imej, pembinaan semula tiga dimensi, pengesanan sasaran, penjejakan video dan medan lain. Ia mencapai invarian skala dengan mengesan titik utama dalam ruang skala berbilang dan mengekstrak deskriptor ciri tempatan di sekitar titik utama. Langkah-langkah utama algoritma SIFT termasuk pembinaan ruang skala, pengesanan titik utama, kedudukan titik utama, penetapan arah dan penjanaan deskriptor ciri. Melalui langkah-langkah ini, algoritma SIFT boleh mengekstrak ciri yang teguh dan unik, dengan itu mencapai pemprosesan imej yang cekap.
