

爬虫如何获得biilbili播放数?

<i id="dianji" title="播放"></i><i id="dm_count" title="弹幕"></i><i id="stow_count" title="收藏"></i><i id="pt"><span class="v_ctimes" title="硬币数量"></span></i>
回复内容:
用av2047063举例,访问下面的网址:【网址已隐去】@妹空酱 提醒我才想起来。。。。
先去自己申请一个appkey。。。在这里:
bilibili - 提示
然后就可以对bilibiliapi为所欲为了。。。。
B站第三方客户端就是这么开发出来的。。。


可以看到最后两个参数id=av号&page=分p
play后面的18253即为播放数。
==============================
b站有公开api啊。。。。。。。那么麻烦干嘛。。。 答主的第一次就就交在这里了,,,
———————————————————————————————————————
前不久学习了python,正好复习一下
代码如下:
import re,urllib
page=urllib.urlopen('http://m.acg.tv/video/av2046040.html')
HTML=page.read()
re_times=r'
result = re.findall(re_times,HTML)
re_title=r'
(.*)
'title=re.findall(re_title,HTML)
print title[0],'的播放次数为',result[0]
下面以av2046040为例:http://www.bilibili.com/video/av2046040/
可以看到
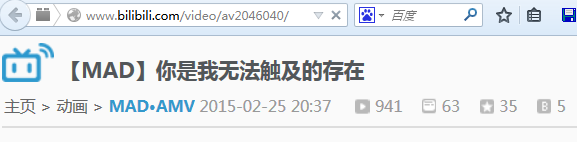 使用火狐查看选中部分源代码,如下
使用火狐查看选中部分源代码,如下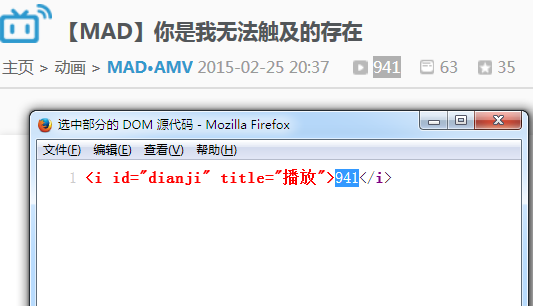 但是我通过python的urllib模块并没有获取到页面内容:
但是我通过python的urllib模块并没有获取到页面内容:page=urllib.urlopen('http://www.bilibili.com/video/av2046040/')
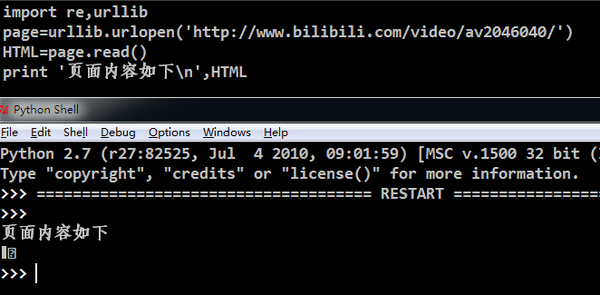 于是我转换思路,貌似B站的手机版网页可以,
于是我转换思路,貌似B站的手机版网页可以,然后使用火狐的User-Agent Overrider修改浏览器UA为Android FireFox/29
 既可以获得如下界面:
既可以获得如下界面: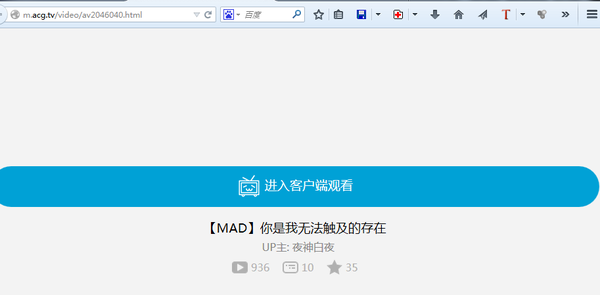 获取到页面实际地址后,就可以再次使用火狐查看源代码
获取到页面实际地址后,就可以再次使用火狐查看源代码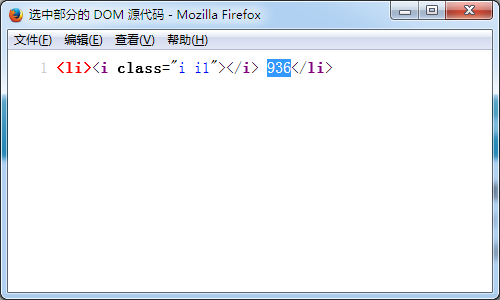 既可以写出正则表达式:
既可以写出正则表达式:re_times=r'
然后正则匹配就好了。
<span class="c"># encoding=utf8</span>
<span class="c"># author:shell-von</span>
<span class="kn">import</span> <span class="nn">requests</span>
<span class="kn">import</span> <span class="nn">re</span>
<span class="n">aid</span> <span class="o">=</span> <span class="s">'3210612'</span>
<span class="n">api_key</span> <span class="o">=</span> <span class="s">"http://interface.bilibili.com/count?key=27f582250563d5d6b11d6833&aid=</span><span class="si">%s</span><span class="s">"</span>
<span class="n">data</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">api_key</span> <span class="o">%</span> <span class="n">aid</span><span class="p">)</span><span class="o">.</span><span class="n">content</span>
<span class="n">regex</span> <span class="o">=</span> <span class="s">r"\('(?:.|#)([\w_]+)'\)\.html\('?(\d+)'?\)"</span>
<span class="k">print</span> <span class="nb">dict</span><span class="p">(</span><span class="n">re</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="n">regex</span><span class="p">,</span> <span class="n">data</span><span class="p">))</span>
 haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:
haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:<span class="n">aid</span> <span class="p">=</span> <span class="mi">3295561</span><span class="p">;</span>
<span class="n">api</span> <span class="p">=</span> <span class="s">'http://interface.bilibili.com/count?key=b9415053057bb00966665eaa'</span><span class="p">;</span>
<span class="n">data</span> <span class="p">=</span> <span class="n">regexp</span><span class="p">(</span><span class="n">webread</span><span class="p">(</span><span class="n">api</span><span class="p">,</span><span class="s">'aid'</span><span class="p">,</span><span class="n">aid</span><span class="p">),</span><span class="s">'#(\w)+\D*(\d)+'</span><span class="p">,</span><span class="s">'tokens'</span><span class="p">);</span>
<span class="n">data</span> <span class="p">=</span> <span class="p">[</span><span class="n">data</span><span class="p">{:}]</span>
0、打开特定的av页面,通过这条语句来找到CID和AID。注意:ctrl + u中能看到的源代码就是能匹配的源代码。
1、发送请求到interface.bilibili.com/player?id=cid:(匹配的CID,要前面的冒号)&aid=(匹配的AID)
2、从获取的xml文件中找到
=====================================================
实际上,我们ctrl + u看到的页面是网站发给我们的其中一个包而已,而最终的结果页面是网站发给我们的多个包组合的结果。
有时候,网站会将数据封装在json或者xml中,然后通过多个请求获取数据,最后在本地用js来进行最后的构建。
因此,页面上看到的内容是最后的结果,如果你要判断这个结果来自于源页面还是json还是xml,就需要通过开发者工具抓抓包,然后自己分析。
总之,逻辑就是:
0、这个数据哪来的? —— 通过抓包分析
1、模拟获取这个数据的过程。 —— 直接访问该数据的来源url
当然还要注意你要传的参数。这个参数从哪些地方获取也需要自己分析。
====================================================
还是举个例子吧。
注意:B站发回的数据是gzip,然而urllib2的urlopen不会自动解压,需要手动处理。
可以参考这个回答:
Does python urllib2 automatically uncompress gzip data fetched from webpage?
随便在首页找了个页面,地址如下:
【爱深黑切】路人女主的玩坏方法~第一弹
import urllib2
import re
from StringIO import StringIO
import gzip
def find_cid_aid(html):
target = re.compile('EmbedPlayer(?P<args>.*?)</script>',re.DOTALL)
cidaid = target.search(html)
cidaid = html[cidaid.start('args'):cidaid.end('args')]
cid = cidaid.find('cid=')
aid = cidaid.find('&aid=')
index = aid
while cidaid[index] != '"':
index += 1
return (cidaid[cid + 4:aid],cidaid[aid + 5:index])
def find_how_many(cid_aid):
target = re.compile(r'<click>(?P<result>.*?)</click>',re.DOTALL)
cid = cid_aid[0]
aid = cid_aid[1]
addr = r'http://interface.bilibili.com/player?id=cid:' + cid + '&aid=' + aid
f = urllib2.urlopen(addr)
res = f.read()
target = target.search(res)
return res[target.start('result'):target.end('result')]
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', \
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3', \
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:28.0) Gecko/20100101 Firefox/28.0',\
'Host':'www.bilibili.com', \
'Accept-Encoding':'gzip, deflate', \
'Cache-Control':'max-age=0', \
'Connection':'keep-alive'}
request = urllib2.Request(r'http://www.bilibili.com/video/av2046145/', headers=headers)
html = urllib2.urlopen(request)
if html.info().get('Content-Encoding') == 'gzip':
buf = StringIO(html.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
cid_aid = find_cid_aid(html)
print find_how_many(cid_aid)
什么东西抓抓包就知道了
比如说如图一样的懒人眼镜,你懂的~~这里的源码直接可以直接用正则匹配到cid和aid,
cid=1511100&aid=1044050然后请求
http://interface.bilibili.com/player?id=cid:1511100&aid=1044050然后被
<click>4611</click>

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Apakah perbezaan antara Huawei GT3 Pro dan GT4?
Dec 29, 2023 pm 02:27 PM
Apakah perbezaan antara Huawei GT3 Pro dan GT4?
Dec 29, 2023 pm 02:27 PM
Ramai pengguna akan memilih jenama Huawei apabila memilih jam tangan pintar Antaranya, Huawei GT3pro dan GT4 adalah pilihan yang sangat popular. Apakah perbezaan antara Huawei GT3pro dan GT4? 1. Rupa GT4: 46mm dan 41mm, bahan cermin kaca + badan keluli tahan karat + cangkang belakang gentian resolusi tinggi. GT3pro: 46.6mm dan 42.9mm, bahannya ialah kaca nilam + badan titanium/badan seramik + cangkerang belakang seramik 2. GT4 yang sihat: Menggunakan algoritma Huawei Truseen5.5+ terkini, hasilnya akan lebih tepat. GT3pro: Penambahan elektrokardiogram ECG dan saluran darah serta keselamatan
 Betulkan: Alat snipping tidak berfungsi dalam Windows 11
Aug 24, 2023 am 09:48 AM
Betulkan: Alat snipping tidak berfungsi dalam Windows 11
Aug 24, 2023 am 09:48 AM
Mengapa Alat Snipping Tidak Berfungsi pada Windows 11 Memahami punca masalah boleh membantu mencari penyelesaian yang betul. Berikut ialah sebab utama Alat Snipping mungkin tidak berfungsi dengan betul: Focus Assistant dihidupkan: Ini menghalang Snipping Tool daripada dibuka. Aplikasi rosak: Jika alat snipping ranap semasa pelancaran, ia mungkin rosak. Pemacu grafik lapuk: Pemacu yang tidak serasi mungkin mengganggu alat snipping. Gangguan daripada aplikasi lain: Aplikasi lain yang sedang berjalan mungkin bercanggah dengan Alat Snipping. Sijil telah tamat tempoh: Ralat semasa proses naik taraf boleh menyebabkan penyelesaian mudah ini sesuai untuk kebanyakan pengguna dan tidak memerlukan sebarang pengetahuan teknikal khusus. 1. Kemas kini apl Windows dan Microsoft Store
 Perbezaan antara counta dan count
Nov 20, 2023 am 10:01 AM
Perbezaan antara counta dan count
Nov 20, 2023 am 10:01 AM
Fungsi Count digunakan untuk mengira bilangan nombor dalam julat yang ditentukan. Ia mengabaikan teks, nilai logik dan nilai nol, tetapi mengira sel kosong Fungsi Count hanya mengira bilangan sel yang mengandungi nombor sebenar. Fungsi CountA digunakan untuk mengira bilangan sel yang tidak kosong dalam julat tertentu. Ia bukan sahaja mengira sel yang mengandungi nombor sebenar, tetapi juga mengira bilangan sel bukan kosong yang mengandungi teks, nilai logik dan formula.
 Cara Membetulkan Ralat Tidak Dapat Menyambung ke App Store pada iPhone
Jul 29, 2023 am 08:22 AM
Cara Membetulkan Ralat Tidak Dapat Menyambung ke App Store pada iPhone
Jul 29, 2023 am 08:22 AM
Bahagian 1: Langkah Penyelesaian Masalah Awal Menyemak Status Sistem Apple: Sebelum menyelidiki penyelesaian yang rumit, mari kita mulakan dengan asas. Masalahnya mungkin tidak terletak pada peranti anda; Lawati halaman Status Sistem Apple untuk melihat sama ada AppStore berfungsi dengan betul. Jika terdapat masalah, anda hanya boleh menunggu Apple membetulkannya. Semak sambungan Internet anda: Pastikan anda mempunyai sambungan internet yang stabil kerana isu "Tidak dapat menyambung ke AppStore" kadangkala boleh dikaitkan dengan sambungan yang lemah. Cuba tukar antara Wi-Fi dan data mudah alih atau tetapkan semula tetapan rangkaian (Umum > Tetapkan Semula > Tetapkan Semula Tetapan Rangkaian > Tetapan). Kemas kini versi iOS anda:
 php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出php提交表单通过后,弹出的对话框怎样在当前页弹出而不是在空白页弹出?想实现这样的效果:而不是空白页弹出:------解决方案--------------------如果你的验证用PHP在后端,那么就用Ajax;仅供参考:HTML code
 apa maksud tajuk
Aug 04, 2023 am 11:18 AM
apa maksud tajuk
Aug 04, 2023 am 11:18 AM
Tajuk ialah makna yang mentakrifkan tajuk halaman web Ia terletak dalam teg dan teks yang dipaparkan dalam bar tajuk pelayar adalah sangat penting untuk pengoptimuman enjin carian dan pengalaman pengguna halaman web. Apabila menulis halaman web HTML, anda harus memberi perhatian kepada menggunakan kata kunci yang berkaitan dan penerangan yang menarik untuk menentukan elemen tajuk untuk menarik lebih ramai pengguna mengklik dan menyemak imbas.
 Apakah maksud tajuk dalam HTML
Mar 06, 2024 am 09:53 AM
Apakah maksud tajuk dalam HTML
Mar 06, 2024 am 09:53 AM
Tajuk dalam HTML memaparkan teg tajuk halaman web, yang membolehkan penonton mengetahui perkara utama halaman semasa, jadi setiap halaman web harus mempunyai tajuk yang berasingan.
 Apakah perbezaan antara div dan span?
Nov 02, 2023 pm 02:29 PM
Apakah perbezaan antara div dan span?
Nov 02, 2023 pm 02:29 PM
Perbezaannya ialah: 1. div ialah elemen peringkat blok, dan span ialah elemen sebaris; 2. div akan secara automatik menduduki baris, manakala span tidak akan secara automatik membalut; span digunakan untuk membalut Teks atau elemen sebaris lain 4. div boleh mengandungi unsur peringkat blok dan unsur sebaris lain, dan span boleh mengandungi unsur sebaris lain.
