

比如说有个name列和一个eamil列,如果数据库里面有条记录的这两列的值相同(我说的是这条记录的对应的那两列的值相同,并不是同一条记录里面两列值相同)的话就自动删除其他多余的列而保留最新的那一条(也就是ID最小的那个,ID是一个自增主键)
——————————————————
也就是说表里面有两条记录的name都是admin,email都是abc@163.com,我只想保留其中一条,这该怎么做
<span class="k">delete</span> <span class="k">from</span> <span class="n">test</span> <span class="k">where</span> <span class="n">id</span> <span class="k">not</span> <span class="k">in</span><span class="p">(</span> <span class="k">select</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span><span class="p">,</span><span class="k">max</span><span class="p">(</span><span class="n">id</span><span class="p">)</span> <span class="k">from</span> <span class="n">test</span> <span class="k">group</span> <span class="k">by</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span> <span class="k">having</span> <span class="n">id</span> <span class="k">is</span> <span class="k">not</span> <span class="k">null</span><span class="p">)</span>
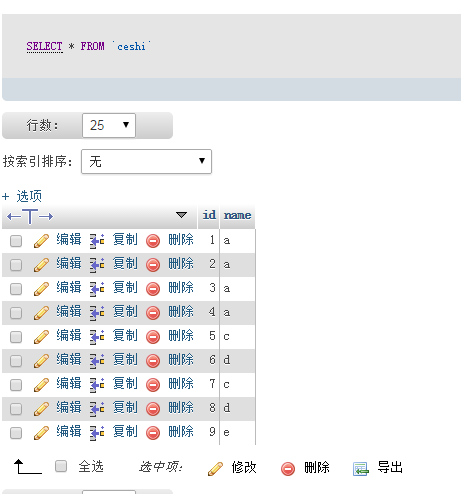

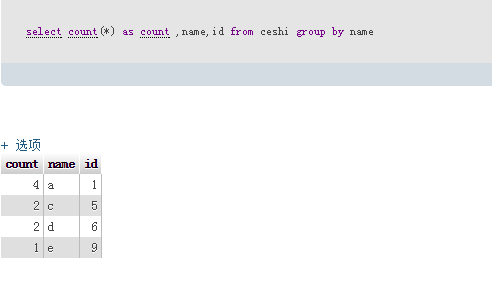 最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)
最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name) Anda memerlukan kebenaran daripada pentadbir untuk membuat perubahan pada fail ini
Anda memerlukan kebenaran daripada pentadbir untuk membuat perubahan pada fail ini
 Apa yang perlu dilakukan jika kod skrin biru 0x0000007e berlaku
Apa yang perlu dilakukan jika kod skrin biru 0x0000007e berlaku
 Semak sama ada port dibuka dalam linux
Semak sama ada port dibuka dalam linux
 Bagaimana untuk memusatkan teks div secara menegak
Bagaimana untuk memusatkan teks div secara menegak
 Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
 Bagaimana untuk berpakaian Douyin Xiaohuoren
Bagaimana untuk berpakaian Douyin Xiaohuoren
 Pesanan yang disyorkan untuk mempelajari bahasa c++ dan c
Pesanan yang disyorkan untuk mempelajari bahasa c++ dan c
 Adakah kadar inflasi mempunyai kesan ke atas mata wang digital?
Adakah kadar inflasi mempunyai kesan ke atas mata wang digital?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



