

正则截取html中的一段

1 |
|
这样的循环 我要截取第一条,多的不要
 标题标题
标题标题回复讨论(解决方案)
1 |
|
页面有点大,有没有更高效的方法!!!!!!!
1 |
|

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.
Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bekerja dengan Data Sesi Flash di Laravel
Mar 12, 2025 pm 05:08 PM
Bekerja dengan Data Sesi Flash di Laravel
Mar 12, 2025 pm 05:08 PM
Laravel memudahkan mengendalikan data sesi sementara menggunakan kaedah flash intuitifnya. Ini sesuai untuk memaparkan mesej ringkas, makluman, atau pemberitahuan dalam permohonan anda. Data hanya berterusan untuk permintaan seterusnya secara lalai: $ permintaan-
 Curl dalam PHP: Cara Menggunakan Pelanjutan PHP Curl dalam API REST
Mar 14, 2025 am 11:42 AM
Curl dalam PHP: Cara Menggunakan Pelanjutan PHP Curl dalam API REST
Mar 14, 2025 am 11:42 AM
Pelanjutan URL Pelanggan PHP (CURL) adalah alat yang berkuasa untuk pemaju, membolehkan interaksi lancar dengan pelayan jauh dan API rehat. Dengan memanfaatkan libcurl, perpustakaan pemindahan fail multi-protokol yang dihormati, php curl memudahkan execu yang cekap
 Respons HTTP yang dipermudahkan dalam ujian Laravel
Mar 12, 2025 pm 05:09 PM
Respons HTTP yang dipermudahkan dalam ujian Laravel
Mar 12, 2025 pm 05:09 PM
Laravel menyediakan sintaks simulasi respons HTTP ringkas, memudahkan ujian interaksi HTTP. Pendekatan ini dengan ketara mengurangkan redundansi kod semasa membuat simulasi ujian anda lebih intuitif. Pelaksanaan asas menyediakan pelbagai jenis pintasan jenis tindak balas: Gunakan Illuminate \ Support \ Facades \ http; Http :: palsu ([ 'Google.com' => 'Hello World', 'github.com' => ['foo' => 'bar'], 'forge.laravel.com' =>
 12 skrip sembang php terbaik di codecanyon
Mar 13, 2025 pm 12:08 PM
12 skrip sembang php terbaik di codecanyon
Mar 13, 2025 pm 12:08 PM
Adakah anda ingin memberikan penyelesaian segera, segera kepada masalah yang paling mendesak pelanggan anda? Sembang langsung membolehkan anda mempunyai perbualan masa nyata dengan pelanggan dan menyelesaikan masalah mereka dengan serta-merta. Ia membolehkan anda memberikan perkhidmatan yang lebih pantas kepada adat anda
 Terangkan konsep pengikatan statik lewat dalam PHP.
Mar 21, 2025 pm 01:33 PM
Terangkan konsep pengikatan statik lewat dalam PHP.
Mar 21, 2025 pm 01:33 PM
Artikel membincangkan pengikatan statik lewat (LSB) dalam PHP, yang diperkenalkan dalam Php 5.3, yang membolehkan resolusi runtime kaedah statik memerlukan lebih banyak warisan yang fleksibel. Isu: LSB vs polimorfisme tradisional; Aplikasi Praktikal LSB dan Potensi Perfo
 Pembalakan PHP: Amalan Terbaik untuk Analisis Log PHP
Mar 10, 2025 pm 02:32 PM
Pembalakan PHP: Amalan Terbaik untuk Analisis Log PHP
Mar 10, 2025 pm 02:32 PM
Pembalakan PHP adalah penting untuk memantau dan menyahpepijat aplikasi web, serta menangkap peristiwa kritikal, kesilapan, dan tingkah laku runtime. Ia memberikan pandangan yang berharga dalam prestasi sistem, membantu mengenal pasti isu -isu, dan menyokong penyelesaian masalah yang lebih cepat
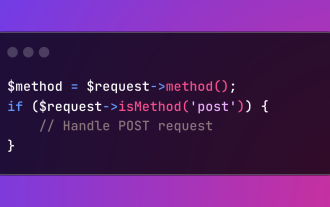 Pengesahan Kaedah HTTP di Laravel
Mar 05, 2025 pm 04:14 PM
Pengesahan Kaedah HTTP di Laravel
Mar 05, 2025 pm 04:14 PM
Laravel memudahkan pengendalian kata kerja HTTP dalam permintaan masuk, menyelaraskan pengurusan operasi yang pelbagai dalam aplikasi anda. Kaedah () dan ismethod () kaedah mengenal pasti dan mengesahkan jenis permintaan. Ciri ini penting untuk membina
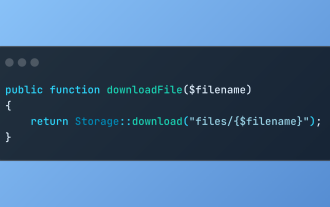 Cari muat turun fail di laravel dengan penyimpanan :: muat turun
Mar 06, 2025 am 02:22 AM
Cari muat turun fail di laravel dengan penyimpanan :: muat turun
Mar 06, 2025 am 02:22 AM
Penyimpanan :: Kaedah Muat turun Rangka Kerja Laravel menyediakan API ringkas untuk mengendalikan muat turun fail dengan selamat sambil menguruskan abstraksi penyimpanan fail. Berikut adalah contoh menggunakan penyimpanan :: muat turun () dalam pengawal contoh:
