

Python使用Srapy框架爬虫模拟登陆并抓取知乎内容

一、Cookie原理
HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制
Cookie是http消息头中的一种属性,包括:
- Cookie名字(Name)Cookie的值(Value)
- Cookie的过期时间(Expires/Max-Age)
- Cookie作用路径(Path)
- Cookie所在域名(Domain),使用Cookie进行安全连接(Secure)
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
二、模拟登陆
这次主要爬取的网站是知乎
爬取知乎就需要登陆的, 通过之前的python内建库, 可以很容易的实现表单提交。
现在就来看看如何通过Scrapy实现表单提交。
首先查看登陆时的表单结果, 依然像前面使用的技巧一样, 故意输错密码, 方面抓到登陆的网页头部和表单(我使用的Chrome自带的开发者工具中的Network功能)
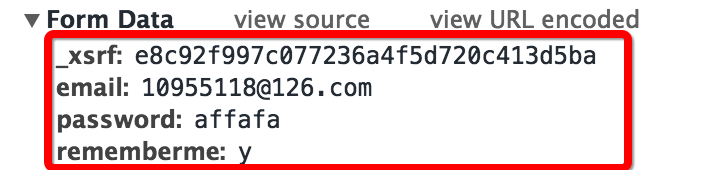
查看抓取到的表单可以发现有四个部分:
- 邮箱和密码就是个人登陆的邮箱和密码
- rememberme字段表示是否记住账号
- 第一个字段是_xsrf,猜测是一种验证机制
- 现在只有_xsrf不知道, 猜想这个验证字段肯定会实现在请求网页的时候发送过来, 那么我们查看当前网页的源码(鼠标右键然后查看网页源代码, 或者直接用快捷键)
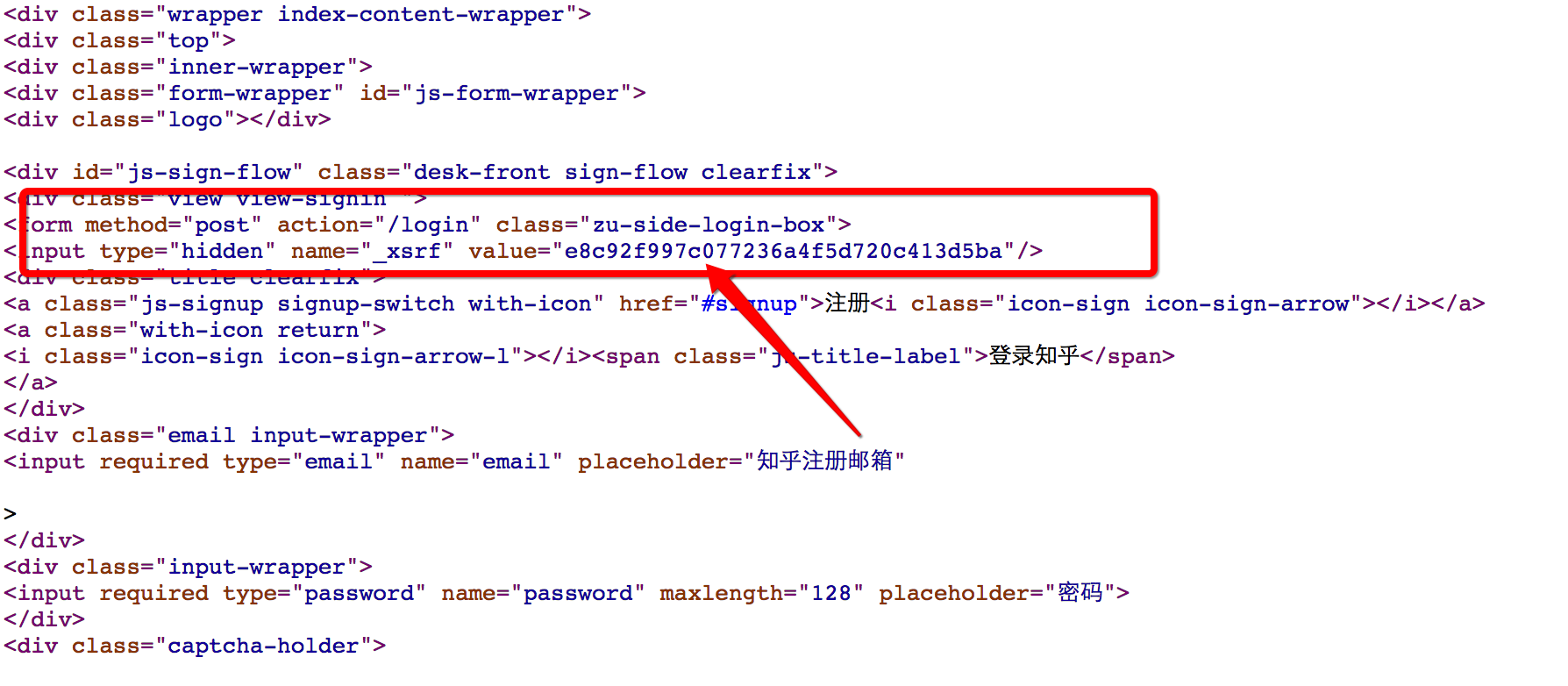
发现我们的猜测是正确的
那么现在就可以来写表单登陆功能了
def start_requests(self):
return [Request("https://www.zhihu.com/login", callback = self.post_login)] #重写了爬虫类的方法, 实现了自定义请求, 运行成功后会调用callback回调函数
#FormRequeset
def post_login(self, response):
print 'Preparing login'
#下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
xsrf = Selector(response).xpath('//input[@name="_xsrf"]/@value').extract()[0]
print xsrf
#FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
#登陆成功后, 会调用after_login回调函数
return [FormRequest.from_response(response,
formdata = {
'_xsrf': xsrf,
'email': '123456',
'password': '123456'
},
callback = self.after_login
)]
其中主要的功能都在函数的注释中说明
三、Cookie的保存
为了能使用同一个状态持续的爬取网站, 就需要保存cookie, 使用cookie保存状态, Scrapy提供了cookie处理的中间件, 可以直接拿来使用
CookiesMiddleware:
这个cookie中间件保存追踪web服务器发出的cookie, 并将这个cookie在接来下的请求的时候进行发送
Scrapy官方的文档中给出了下面的代码范例 :
for i, url in enumerate(urls):
yield scrapy.Request("http://www.example.com", meta={'cookiejar': i},
callback=self.parse_page)
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)
那么可以对我们的爬虫类中方法进行修改, 使其追踪cookie
#重写了爬虫类的方法, 实现了自定义请求, 运行成功后会调用callback回调函数
def start_requests(self):
return [Request("https://www.zhihu.com/login", meta = {'cookiejar' : 1}, callback = self.post_login)] #添加了meta
#FormRequeset出问题了
def post_login(self, response):
print 'Preparing login'
#下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
xsrf = Selector(response).xpath('//input[@name="_xsrf"]/@value').extract()[0]
print xsrf
#FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
#登陆成功后, 会调用after_login回调函数
return [FormRequest.from_response(response, #"http://www.zhihu.com/login",
meta = {'cookiejar' : response.meta['cookiejar']}, #注意这里cookie的获取
headers = self.headers,
formdata = {
'_xsrf': xsrf,
'email': '123456',
'password': '123456'
},
callback = self.after_login,
dont_filter = True
)]
四、伪装头部
有时候登陆网站需要进行头部伪装, 比如增加防盗链的头部, 还有模拟服务器登陆
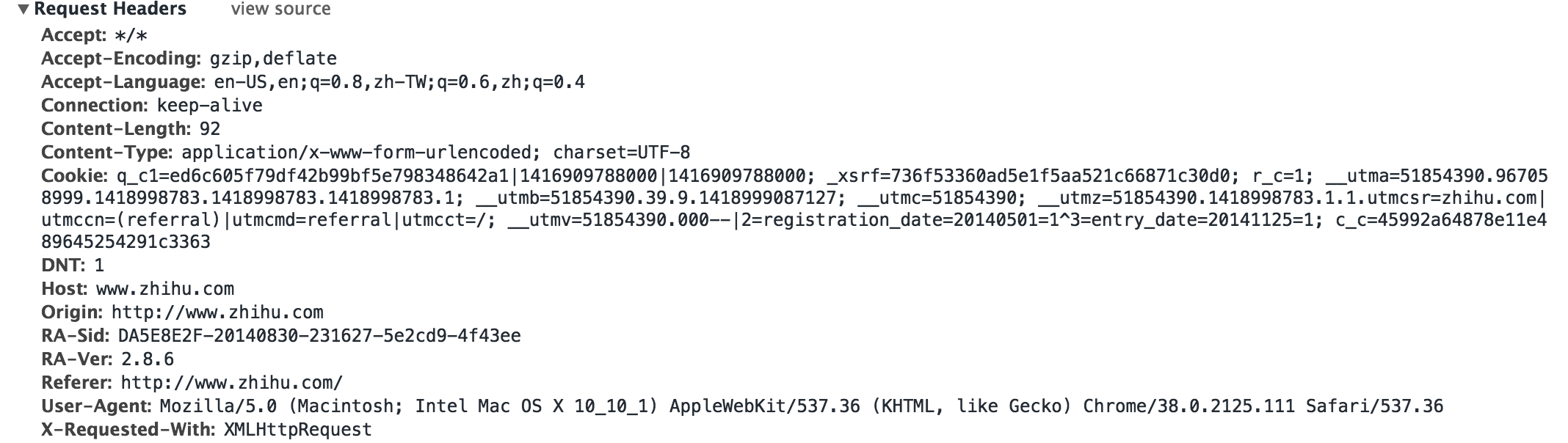
为了保险, 我们可以在头部中填充更多的字段, 如下
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
在scrapy中Request和FormRequest初始化的时候都有一个headers字段, 可以自定义头部, 这样我们可以添加headers字段
形成最终版的登陆函数
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.selector import Selector
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.http import Request, FormRequest
from zhihu.items import ZhihuItem
class ZhihuSipder(CrawlSpider) :
name = "zhihu"
allowed_domains = ["www.zhihu.com"]
start_urls = [
"http://www.zhihu.com"
]
rules = (
Rule(SgmlLinkExtractor(allow = ('/question/\d+#.*?', )), callback = 'parse_page', follow = True),
Rule(SgmlLinkExtractor(allow = ('/question/\d+', )), callback = 'parse_page', follow = True),
)
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
#重写了爬虫类的方法, 实现了自定义请求, 运行成功后会调用callback回调函数
def start_requests(self):
return [Request("https://www.zhihu.com/login", meta = {'cookiejar' : 1}, callback = self.post_login)]
#FormRequeset出问题了
def post_login(self, response):
print 'Preparing login'
#下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
xsrf = Selector(response).xpath('//input[@name="_xsrf"]/@value').extract()[0]
print xsrf
#FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
#登陆成功后, 会调用after_login回调函数
return [FormRequest.from_response(response, #"http://www.zhihu.com/login",
meta = {'cookiejar' : response.meta['cookiejar']},
headers = self.headers, #注意此处的headers
formdata = {
'_xsrf': xsrf,
'email': '1095511864@qq.com',
'password': '123456'
},
callback = self.after_login,
dont_filter = True
)]
def after_login(self, response) :
for url in self.start_urls :
yield self.make_requests_from_url(url)
def parse_page(self, response):
problem = Selector(response)
item = ZhihuItem()
item['url'] = response.url
item['name'] = problem.xpath('//span[@class="name"]/text()').extract()
print item['name']
item['title'] = problem.xpath('//h2[@class="zm-item-title zm-editable-content"]/text()').extract()
item['description'] = problem.xpath('//div[@class="zm-editable-content"]/text()').extract()
item['answer']= problem.xpath('//div[@class=" zm-editable-content clearfix"]/text()').extract()
return item
五、Item类和抓取间隔
完整的知乎爬虫代码链接
from scrapy.item import Item, Field class ZhihuItem(Item): # define the fields for your item here like: # name = scrapy.Field() url = Field() #保存抓取问题的url title = Field() #抓取问题的标题 description = Field() #抓取问题的描述 answer = Field() #抓取问题的答案 name = Field() #个人用户的名称
设置抓取间隔, 访问由于爬虫的过快抓取, 引发网站的发爬虫机制, 在setting.py中设置
BOT_NAME = 'zhihu' SPIDER_MODULES = ['zhihu.spiders'] NEWSPIDER_MODULE = 'zhihu.spiders' DOWNLOAD_DELAY = 0.25 #设置下载间隔为250ms
更多设置可以查看官方文档
抓取结果(只是截取了其中很少一部分)
...
'url': 'http://www.zhihu.com/question/20688855/answer/16577390'}
2014-12-19 23:24:15+0800 [zhihu] DEBUG: Crawled (200) <GET http://www.zhihu.com/question/20688855/answer/15861368> (referer: http://www.zhihu.com/question/20688855/answer/19231794)
[]
2014-12-19 23:24:15+0800 [zhihu] DEBUG: Scraped from <200 http://www.zhihu.com/question/20688855/answer/15861368>
{'answer': [u'\u9009\u4f1a\u8ba1\u8fd9\u4e2a\u4e13\u4e1a\uff0c\u8003CPA\uff0c\u5165\u8d22\u52a1\u8fd9\u4e2a\u884c\u5f53\u3002\u8fd9\u4e00\u8def\u8d70\u4e0b\u6765\uff0c\u6211\u53ef\u4ee5\u5f88\u80af\u5b9a\u7684\u544a\u8bc9\u4f60\uff0c\u6211\u662f\u771f\u7684\u559c\u6b22\u8d22\u52a1\uff0c\u70ed\u7231\u8fd9\u4e2a\u884c\u4e1a\uff0c\u56e0\u6b64\u575a\u5b9a\u4e0d\u79fb\u5730\u5728\u8fd9\u4e2a\u884c\u4e1a\u4e2d\u8d70\u4e0b\u53bb\u3002',
u'\u4e0d\u8fc7\u4f60\u8bf4\u6709\u4eba\u4ece\u5c0f\u5c31\u559c\u6b22\u8d22\u52a1\u5417\uff1f\u6211\u89c9\u5f97\u51e0\u4e4e\u6ca1\u6709\u5427\u3002\u8d22\u52a1\u7684\u9b45\u529b\u5728\u4e8e\u4f60\u771f\u6b63\u61c2\u5f97\u5b83\u4e4b\u540e\u3002',
u'\u901a\u8fc7\u5b83\uff0c\u4f60\u53ef\u4ee5\u5b66\u4e60\u4efb\u4f55\u4e00\u79cd\u5546\u4e1a\u7684\u7ecf\u8425\u8fc7\u7a0b\uff0c\u4e86\u89e3\u5176\u7eb7\u7e41\u5916\u8868\u4e0b\u7684\u5b9e\u7269\u6d41\u3001\u73b0\u91d1\u6d41\uff0c\u751a\u81f3\u4f60\u53ef\u4ee5\u638c\u63e1\u5982\u4f55\u53bb\u7ecf\u8425\u8fd9\u79cd\u5546\u4e1a\u3002',
u'\u5982\u679c\u5bf9\u4f1a\u8ba1\u7684\u8ba4\u8bc6\u4ec5\u4ec5\u505c\u7559\u5728\u505a\u5206\u5f55\u8fd9\u4e2a\u5c42\u9762\uff0c\u5f53\u7136\u4f1a\u89c9\u5f97\u67af\u71e5\u65e0\u5473\u3002\u5f53\u4f60\u5bf9\u5b83\u7684\u8ba4\u8bc6\u8fdb\u5165\u5230\u6df1\u5c42\u6b21\u7684\u65f6\u5019\uff0c\u4f60\u81ea\u7136\u5c31\u4f1a\u559c\u6b22\u4e0a\u5b83\u4e86\u3002\n\n\n'],
'description': [u'\u672c\u4eba\u5b66\u4f1a\u8ba1\u6559\u80b2\u4e13\u4e1a\uff0c\u6df1\u611f\u5176\u67af\u71e5\u4e4f\u5473\u3002\n\u5f53\u521d\u662f\u51b2\u7740\u5e08\u8303\u4e13\u4e1a\u62a5\u7684\uff0c\u56e0\u4e3a\u68a6\u60f3\u662f\u6210\u4e3a\u4e00\u540d\u8001\u5e08\uff0c\u4f46\u662f\u611f\u89c9\u73b0\u5728\u666e\u901a\u521d\u9ad8\u4e2d\u8001\u5e08\u5df2\u7ecf\u8d8b\u4e8e\u9971\u548c\uff0c\u800c\u987a\u6bcd\u4eb2\u5927\u4eba\u7684\u610f\u9009\u4e86\u8fd9\u4e2a\u4e13\u4e1a\u3002\u6211\u559c\u6b22\u4e0a\u6559\u80b2\u5b66\u7684\u8bfe\uff0c\u5e76\u597d\u7814\u7a76\u5404\u79cd\u6559\u80b2\u5fc3\u7406\u5b66\u3002\u4f46\u4f1a\u8ba1\u8bfe\u4f3c\u4e4e\u662f\u4e3b\u6d41\u3001\u54ce\u3002\n\n\u4e00\u76f4\u4e0d\u559c\u6b22\u94b1\u4e0d\u94b1\u7684\u4e13\u4e1a\uff0c\u6240\u4ee5\u5f88\u597d\u5947\u5927\u5bb6\u9009\u4f1a\u8ba1\u4e13\u4e1a\u5230\u5e95\u662f\u51fa\u4e8e\u4ec0\u4e48\u76ee\u7684\u3002\n\n\u6bd4\u5982\u8bf4\u5b66\u4e2d\u6587\u7684\u4f1a\u8bf4\u4ece\u5c0f\u559c\u6b22\u770b\u4e66\uff0c\u4f1a\u6709\u4ece\u5c0f\u559c\u6b22\u4f1a\u8ba1\u501f\u554a\u8d37\u554a\u7684\u7684\u4eba\u5417\uff1f'],
'name': [],
'title': [u'\n\n', u'\n\n'],
'url': 'http://www.zhihu.com/question/20688855/answer/15861368'}
...
六、存在问题
- Rule设计不能实现全网站抓取, 只是设置了简单的问题的抓取
- Xpath设置不严谨, 需要重新思考
- Unicode编码应该转换成UTF-8

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Apakah sebab mengapa PS terus menunjukkan pemuatan?
Apr 06, 2025 pm 06:39 PM
Apakah sebab mengapa PS terus menunjukkan pemuatan?
Apr 06, 2025 pm 06:39 PM
PS "Memuatkan" Masalah disebabkan oleh akses sumber atau masalah pemprosesan: Kelajuan bacaan cakera keras adalah perlahan atau buruk: Gunakan CrystaldiskInfo untuk memeriksa kesihatan cakera keras dan menggantikan cakera keras yang bermasalah. Memori yang tidak mencukupi: Meningkatkan memori untuk memenuhi keperluan PS untuk imej resolusi tinggi dan pemprosesan lapisan kompleks. Pemandu kad grafik sudah lapuk atau rosak: Kemas kini pemandu untuk mengoptimumkan komunikasi antara PS dan kad grafik. Laluan fail terlalu panjang atau nama fail mempunyai aksara khas: Gunakan laluan pendek dan elakkan aksara khas. Masalah PS sendiri: Pasang semula atau membaiki pemasang PS.
 Bagaimana menyelesaikan masalah pemuatan apabila PS dimulakan?
Apr 06, 2025 pm 06:36 PM
Bagaimana menyelesaikan masalah pemuatan apabila PS dimulakan?
Apr 06, 2025 pm 06:36 PM
PS yang tersangkut pada "memuatkan" apabila boot boleh disebabkan oleh pelbagai sebab: Lumpuhkan plugin yang korup atau bercanggah. Padam atau namakan semula fail konfigurasi yang rosak. Tutup program yang tidak perlu atau menaik taraf memori untuk mengelakkan memori yang tidak mencukupi. Naik taraf ke pemacu keadaan pepejal untuk mempercepatkan bacaan cakera keras. Pasang semula PS untuk membaiki fail sistem rasuah atau isu pakej pemasangan. Lihat maklumat ralat semasa proses permulaan analisis log ralat.
 Bagaimana untuk menyelesaikan masalah pemuatan apabila PS membuka fail?
Apr 06, 2025 pm 06:33 PM
Bagaimana untuk menyelesaikan masalah pemuatan apabila PS membuka fail?
Apr 06, 2025 pm 06:33 PM
"Memuatkan" gagap berlaku apabila membuka fail pada PS. Sebab-sebabnya mungkin termasuk: fail yang terlalu besar atau rosak, memori yang tidak mencukupi, kelajuan cakera keras perlahan, masalah pemacu kad grafik, versi PS atau konflik plug-in. Penyelesaiannya ialah: Semak saiz fail dan integriti, tingkatkan memori, menaik taraf cakera keras, mengemas kini pemacu kad grafik, menyahpasang atau melumpuhkan pemalam yang mencurigakan, dan memasang semula PS. Masalah ini dapat diselesaikan dengan berkesan dengan memeriksa secara beransur -ansur dan memanfaatkan tetapan prestasi PS yang baik dan membangunkan tabiat pengurusan fail yang baik.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Kunci kawalan bulu adalah memahami sifatnya secara beransur -ansur. PS sendiri tidak menyediakan pilihan untuk mengawal lengkung kecerunan secara langsung, tetapi anda boleh melaraskan radius dan kelembutan kecerunan dengan pelbagai bulu, topeng yang sepadan, dan pilihan halus untuk mencapai kesan peralihan semula jadi.
 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Apa yang perlu saya lakukan jika kad PS berada di antara muka pemuatan?
Apr 06, 2025 pm 06:54 PM
Apa yang perlu saya lakukan jika kad PS berada di antara muka pemuatan?
Apr 06, 2025 pm 06:54 PM
Antara muka pemuatan kad PS mungkin disebabkan oleh perisian itu sendiri (fail rasuah atau konflik plug-in), persekitaran sistem (pemacu yang wajar atau fail sistem rasuah), atau perkakasan (rasuah cakera keras atau kegagalan tongkat memori). Pertama semak sama ada sumber komputer mencukupi, tutup program latar belakang dan lepaskan memori dan sumber CPU. Betulkan pemasangan PS atau periksa isu keserasian untuk pemalam. Mengemas kini atau menewaskan versi PS. Semak pemacu kad grafik dan kemas kini, dan jalankan semak fail sistem. Jika anda menyelesaikan masalah di atas, anda boleh mencuba pengesanan cakera keras dan ujian memori.
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
