

浅谈网站文件下载的原理

今晚我们来聊聊网站文件下载的原理,下面我结合代码来给大家分析。
function download($file_name){
header("Content-type:text/html;charset=utf-8");
// 可以将带中文的文件名进行编码转换,避免file_exists函数不认识中文!
$file_name = iconv("utf-8","gb2312",$file_name);
$path = $_SERVER['DOCUMENT_ROOT']'; // 获取下载文件的绝对目录
$file_path = $path.'/'.$file_name; // 拼接将被下载的文件的路径
if(!file_exists($file_path)){
echo '要下载的文件不存在!';
exit();
}
// 分享下载的文件,必须首先读入到内存
// 注意:任何有关从服务器下载的文件操作,必然需要先在服务端将文件读入内存当中
$fp = fopen($file_path, 'r');
$file_size = filesize($file_path); // 获取文件的总大小
// PHP下载文件需要用到的头
// 通过这句代码客户端浏览器就能知道服务端返回的文件形式
Header("Content-type: application/octet-stream");
Header("Accept-Ranges: bytes"); // 说明文件传输单位是字节
Header("Accept-Length:".$file_size); // 因为是http协议传输,因此必须指明需要接收的长度
// 告诉浏览器下载返回的文件的名称
Header("Content-Disposition: attachment; filename=".$file_name);
$buffer = 1024 ; // 避免给服务器造成很大压力,因此一次只读1024字节
$file_count = 0;
// feof:读取到文件结尾
while(!feof($fp) && $file_count // 通过fopen,文件已经被放入内存了!现在从内存中读取fread即下载
$file_content = fread($fp, $buffer); // $file_content:每次读到的文件内容
$file_count += $buffer;
echo $file_content; // echo每次读取到的内容,就好比是一点一点的下载
}
fclose($fp);
}
?>
今天我们简单的讲解了文件下载原理,希望会对大家以后做下载方面功能的时候,有些许启发,那样就足够了!

以上就介绍了浅谈网站文件下载的原理,包括了方面的内容,希望对PHP教程有兴趣的朋友有所帮助。

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Penyelesaian: Organisasi anda memerlukan anda menukar PIN anda
Oct 04, 2023 pm 05:45 PM
Penyelesaian: Organisasi anda memerlukan anda menukar PIN anda
Oct 04, 2023 pm 05:45 PM
Mesej "Organisasi anda memerlukan anda menukar PIN anda" akan muncul pada skrin log masuk. Ini berlaku apabila had tamat tempoh PIN dicapai pada komputer menggunakan tetapan akaun berasaskan organisasi, di mana mereka mempunyai kawalan ke atas peranti peribadi. Walau bagaimanapun, jika anda menyediakan Windows menggunakan akaun peribadi, sebaiknya mesej ralat tidak akan muncul. Walaupun ini tidak selalu berlaku. Kebanyakan pengguna yang mengalami ralat melaporkan menggunakan akaun peribadi mereka. Mengapa organisasi saya meminta saya menukar PIN saya pada Windows 11? Ada kemungkinan akaun anda dikaitkan dengan organisasi dan pendekatan utama anda adalah untuk mengesahkan perkara ini. Menghubungi pentadbir domain anda boleh membantu! Selain itu, tetapan dasar tempatan yang salah konfigurasi atau kunci pendaftaran yang salah boleh menyebabkan ralat. Sekarang ni
 Cara melaraskan tetapan sempadan tetingkap pada Windows 11: Tukar warna dan saiz
Sep 22, 2023 am 11:37 AM
Cara melaraskan tetapan sempadan tetingkap pada Windows 11: Tukar warna dan saiz
Sep 22, 2023 am 11:37 AM
Windows 11 membawa reka bentuk yang segar dan elegan ke hadapan antara muka moden membolehkan anda memperibadikan dan menukar butiran terbaik, seperti sempadan tingkap. Dalam panduan ini, kami akan membincangkan arahan langkah demi langkah untuk membantu anda mencipta persekitaran yang mencerminkan gaya anda dalam sistem pengendalian Windows. Bagaimana untuk menukar tetapan sempadan tetingkap? Tekan + untuk membuka apl Tetapan. WindowsSaya pergi ke Pemperibadian dan klik Tetapan Warna. Perubahan Warna Tetingkap Sempadan Tetapan Tetingkap 11" Lebar="643" Tinggi="500" > Cari pilihan Tunjukkan warna aksen pada bar tajuk dan sempadan tetingkap, dan togol suis di sebelahnya. Untuk memaparkan warna aksen pada menu Mula dan bar tugas Untuk memaparkan warna tema pada menu Mula dan bar tugas, hidupkan Tunjukkan tema pada menu Mula dan bar tugas
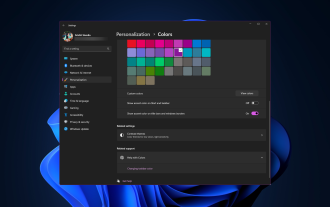 Bagaimana untuk menukar warna bar tajuk pada Windows 11?
Sep 14, 2023 pm 03:33 PM
Bagaimana untuk menukar warna bar tajuk pada Windows 11?
Sep 14, 2023 pm 03:33 PM
Secara lalai, warna bar tajuk pada Windows 11 bergantung pada tema gelap/terang yang anda pilih. Walau bagaimanapun, anda boleh menukarnya kepada mana-mana warna yang anda mahu. Dalam panduan ini, kami akan membincangkan arahan langkah demi langkah untuk tiga cara mengubahnya dan memperibadikan pengalaman desktop anda untuk menjadikannya menarik secara visual. Adakah mungkin untuk menukar warna bar tajuk tetingkap aktif dan tidak aktif? Ya, anda boleh menukar warna bar tajuk tetingkap aktif menggunakan apl Tetapan, atau anda boleh menukar warna bar tajuk tetingkap tidak aktif menggunakan Registry Editor. Untuk mempelajari langkah-langkah ini, pergi ke bahagian seterusnya. Bagaimana untuk menukar warna bar tajuk dalam Windows 11? 1. Tekan + untuk membuka tetingkap tetapan menggunakan apl Tetapan. WindowsSaya pergi ke "Peribadikan" dan kemudian
 Masalah Ralat OOBELANGUAGE dalam Pembaikan Windows 11/10
Jul 16, 2023 pm 03:29 PM
Masalah Ralat OOBELANGUAGE dalam Pembaikan Windows 11/10
Jul 16, 2023 pm 03:29 PM
Adakah anda melihat "Masalah berlaku" bersama-sama dengan pernyataan "OOBELANGUAGE" pada halaman Pemasang Windows? Pemasangan Windows kadangkala terhenti kerana ralat tersebut. OOBE bermaksud pengalaman di luar kotak. Seperti yang ditunjukkan oleh mesej ralat, ini ialah isu yang berkaitan dengan pemilihan bahasa OOBE. Tiada apa yang perlu dibimbangkan, anda boleh menyelesaikan masalah ini dengan penyuntingan pendaftaran yang bagus dari skrin OOBE itu sendiri. Pembetulan Pantas – 1. Klik butang “Cuba Semula” di bahagian bawah apl OOBE. Ini akan meneruskan proses tanpa gangguan lagi. 2. Gunakan butang kuasa untuk menutup paksa sistem. Selepas sistem dimulakan semula, OOBE harus diteruskan. 3. Putuskan sambungan sistem daripada Internet. Lengkapkan semua aspek OOBE dalam mod luar talian
 Bagaimana untuk mendayakan atau melumpuhkan pratonton lakaran kecil bar tugas pada Windows 11
Sep 15, 2023 pm 03:57 PM
Bagaimana untuk mendayakan atau melumpuhkan pratonton lakaran kecil bar tugas pada Windows 11
Sep 15, 2023 pm 03:57 PM
Lakaran kecil bar tugas boleh menjadi menyeronokkan, tetapi ia juga boleh mengganggu atau menjengkelkan. Memandangkan kekerapan anda menuding di atas kawasan ini, anda mungkin telah menutup tetingkap penting secara tidak sengaja beberapa kali. Kelemahan lain ialah ia menggunakan lebih banyak sumber sistem, jadi jika anda telah mencari cara untuk menjadi lebih cekap sumber, kami akan menunjukkan kepada anda cara untuk melumpuhkannya. Walau bagaimanapun, jika spesifikasi perkakasan anda boleh mengendalikannya dan anda menyukai pratonton, anda boleh mendayakannya. Bagaimana untuk mendayakan pratonton lakaran kecil bar tugas dalam Windows 11? 1. Menggunakan apl Tetapan ketik kekunci dan klik Tetapan. Windows klik Sistem dan pilih Perihal. Klik Tetapan sistem lanjutan. Navigasi ke tab Lanjutan dan pilih Tetapan di bawah Prestasi. Pilih "Kesan Visual"
 Paparkan panduan penskalaan pada Windows 11
Sep 19, 2023 pm 06:45 PM
Paparkan panduan penskalaan pada Windows 11
Sep 19, 2023 pm 06:45 PM
Kita semua mempunyai pilihan yang berbeza apabila ia berkaitan dengan penskalaan paparan pada Windows 11. Sesetengah orang suka ikon besar, ada yang suka ikon kecil. Walau bagaimanapun, kita semua bersetuju bahawa mempunyai penskalaan yang betul adalah penting. Penskalaan fon yang lemah atau penskalaan berlebihan imej boleh menjadi pembunuh produktiviti sebenar apabila bekerja, jadi anda perlu tahu cara menyesuaikannya untuk memanfaatkan sepenuhnya keupayaan sistem anda. Kelebihan Zum Tersuai: Ini adalah ciri yang berguna untuk orang yang mengalami kesukaran membaca teks pada skrin. Ia membantu anda melihat lebih banyak pada skrin pada satu masa. Anda boleh membuat profil sambungan tersuai yang digunakan hanya pada monitor dan aplikasi tertentu. Boleh membantu meningkatkan prestasi perkakasan kelas rendah. Ia memberi anda lebih kawalan ke atas perkara yang terdapat pada skrin anda. Cara menggunakan Windows 11
 10 Cara untuk Melaraskan Kecerahan pada Windows 11
Dec 18, 2023 pm 02:21 PM
10 Cara untuk Melaraskan Kecerahan pada Windows 11
Dec 18, 2023 pm 02:21 PM
Kecerahan skrin adalah bahagian penting dalam menggunakan peranti pengkomputeran moden, terutamanya apabila anda melihat skrin untuk jangka masa yang lama. Ia membantu anda mengurangkan ketegangan mata, meningkatkan kebolehbacaan dan melihat kandungan dengan mudah dan cekap. Walau bagaimanapun, bergantung pada tetapan anda, kadangkala sukar untuk mengurus kecerahan, terutamanya pada Windows 11 dengan perubahan UI baharu. Jika anda menghadapi masalah melaraskan kecerahan, berikut ialah semua cara untuk mengurus kecerahan pada Windows 11. Cara Menukar Kecerahan pada Windows 11 [10 Cara Diterangkan] Pengguna monitor tunggal boleh menggunakan kaedah berikut untuk melaraskan kecerahan pada Windows 11. Ini termasuk sistem desktop menggunakan monitor tunggal serta komputer riba. Jom mulakan. Kaedah 1: Gunakan Pusat Tindakan Pusat Tindakan boleh diakses
 Bagaimana untuk Membetulkan Kod Ralat Pengaktifan 0xc004f069 dalam Pelayan Windows
Jul 22, 2023 am 09:49 AM
Bagaimana untuk Membetulkan Kod Ralat Pengaktifan 0xc004f069 dalam Pelayan Windows
Jul 22, 2023 am 09:49 AM
Proses pengaktifan pada Windows kadangkala mengambil giliran secara tiba-tiba untuk memaparkan mesej ralat yang mengandungi kod ralat ini 0xc004f069. Walaupun proses pengaktifan adalah dalam talian, beberapa sistem lama yang menjalankan Windows Server mungkin mengalami masalah ini. Lakukan semakan awal ini dan jika ia tidak membantu anda mengaktifkan sistem anda, lompat ke penyelesaian utama untuk menyelesaikan isu tersebut. Penyelesaian – Tutup mesej ralat dan tetingkap pengaktifan. Kemudian, mulakan semula komputer anda. Cuba semula proses pengaktifan Windows dari awal lagi. Betulkan 1 – Aktifkan dari Terminal Aktifkan sistem Windows Server Edition dari terminal cmd. Peringkat – 1 Semak Versi Pelayan Windows Anda perlu menyemak jenis W yang anda gunakan
